1. 什么是神经网络?
神经网络(Neural Network)是一种模仿人类大脑神经元结构和工作方式的计算模型,广泛用于机器学习和人工智能中,尤其擅长处理图像识别、语音识别、自然语言处理等复杂任务。
💡 通俗理解
可以把神经网络看成一个“黑盒子”系统:
- 你给它输入数据(比如猫狗图片)
- 它通过大量训练,自动学习数据中的规律
- 最终给出输出(比如“这是猫”或“这是狗”)
就像人类通过经验不断学习一样,神经网络也通过数据“训练自己”。
2. 基本组成结构
神经网络通常由以下三部分组成:
-
输入层(Input Layer)
- 接收原始数据,如图片的像素值、文本的向量表示等。
-
隐藏层(Hidden Layers)
- 中间若干层神经元,负责对数据进行处理和特征提取(如边缘、纹理、语义)。
-
输出层(Output Layer)
- 输出最终结果,如分类标签(“猫”/“狗”)或预测数值(房价、股价)。
每一层包含多个神经元,神经元之间通过**权重(weight)和偏置(bias)连接,并经过激活函数(activation function)**进行非线性变换。
🌰 举个例子:识别猫和狗
- 输入层:接收一张图片的像素数据(如 224×224×3)
- 隐藏层:逐层提取特征(耳朵形状 → 毛发纹理 → 整体轮廓)
- 输出层:输出概率,如 P(猫)=0.9,P(狗)=0.1
3. 常见神经网络类型
主要有以下几类:
- 前馈神经网络(FNN)
- 卷积神经网络(CNN)
- 循环神经网络(RNN)
- 生成对抗网络(GAN)
下面逐一详解。
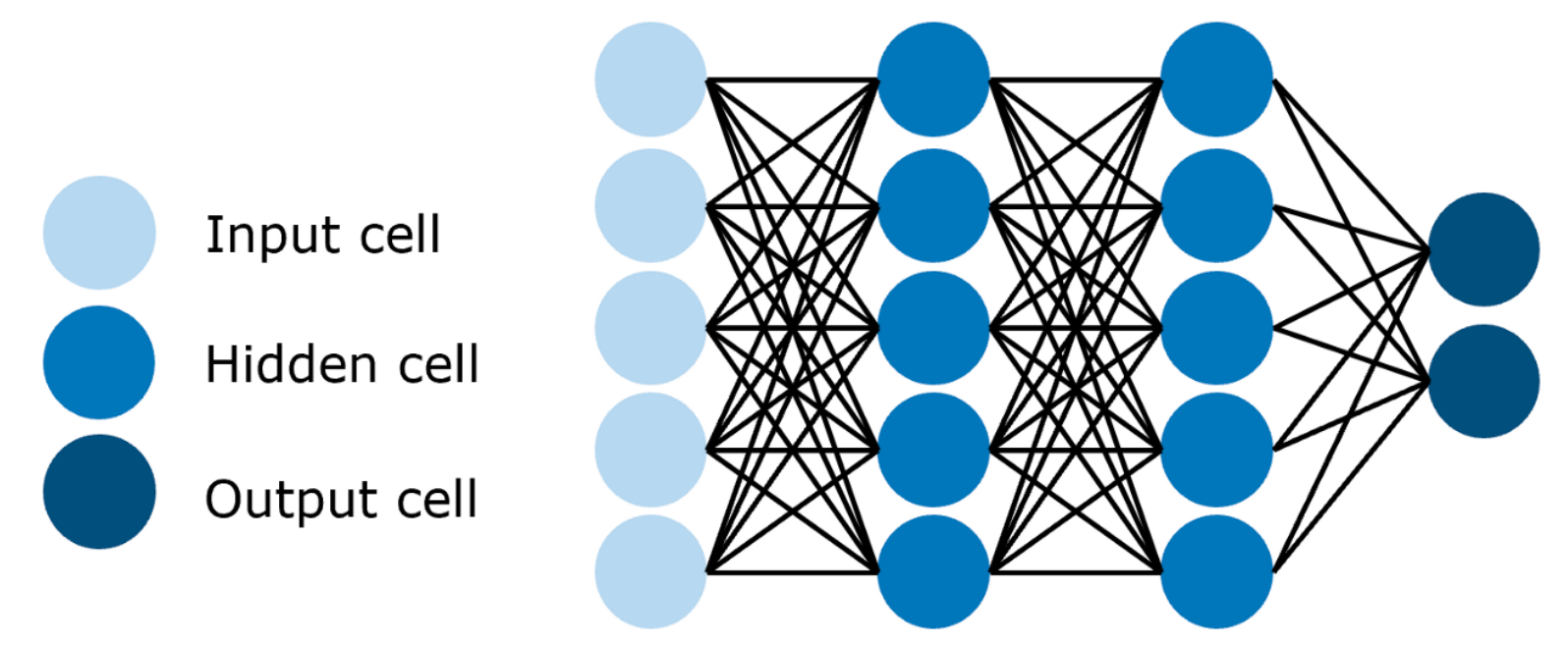
4. 前馈神经网络(Feedforward Neural Network,FNN)
📌 描述
最基本的神经网络结构,信息单向流动:从输入层 → 隐藏层 → 输出层,没有循环或反馈。
🎯 用途
- 图像分类(简单场景)
- 函数拟合
- 特征映射
🔧 核心算法
- 前向传播(Forward Propagation)
- 反向传播(Backpropagation)
📐 数学表达(前向传播)
对于第 $ l $ 层($ l = 1, 2, …, L $),计算分为两步:
-
线性变换(加权求和 + 偏置):
-
非线性激活:
✅ 符号解释
| 符号 | 含义 |
|---|---|
| $ \mathbf{a}^{(l-1)} $ | 上一层的输出(输入层时为原始输入 $ \mathbf{x} $) |
| $ \mathbf{W}^{(l)} $ | 第 $ l $ 层的权重矩阵 |
| $ \mathbf{b}^{(l)} $ | 第 $ l $ 层的偏置向量 |
| $ \mathbf{z}^{(l)} $ | 未激活的中间结果(“净输入”) |
| $ \sigma(\cdot) $ | 激活函数(如 ReLU、Sigmoid、Tanh) |
🌰 简单例子:二分类(2 层网络)
- 输入:2 个特征
- 隐藏层:3 个神经元,使用 ReLU 激活
- 输出层:1 个神经元,使用 Sigmoid 激活(输出概率)
前向过程:
-
隐藏层:
-
输出层:
✅ 输出 $\hat{y} $ 可解释为“是正类的概率”。
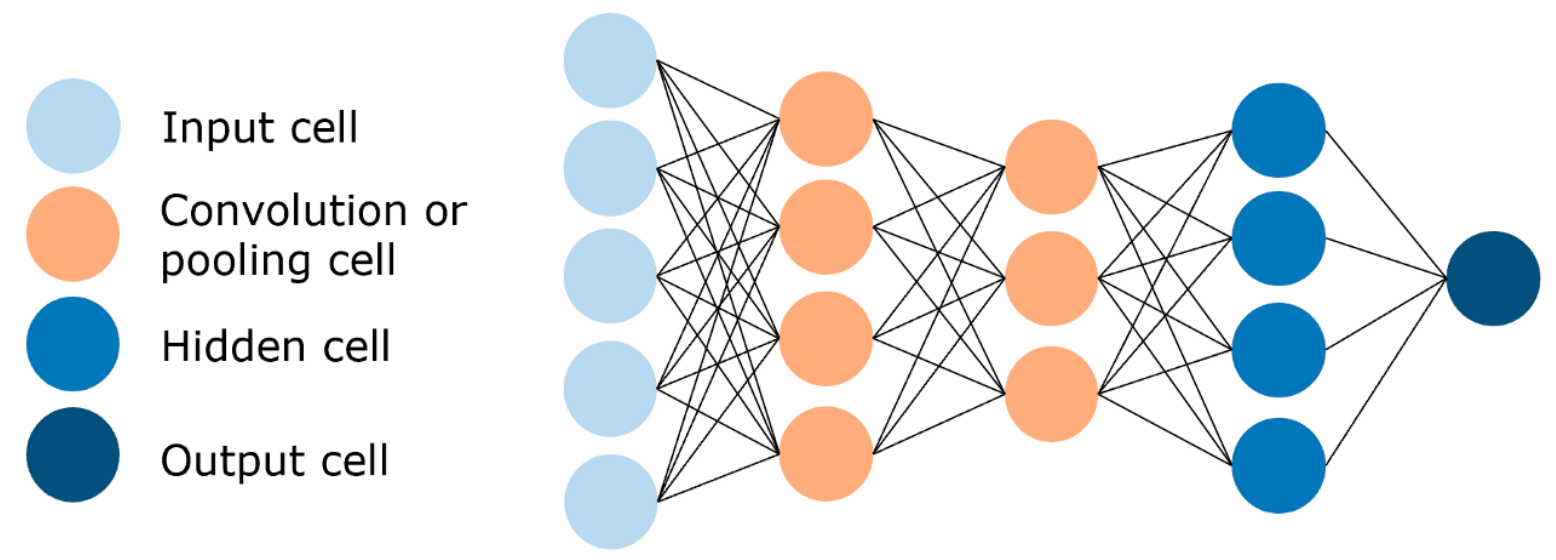
5. 卷积神经网络(Convolutional Neural Network,CNN)
📌 描述
专门用于处理具有空间结构的数据(如图像、视频),通过卷积操作自动提取局部特征(边缘、纹理等)。
🎯 用途
- 图像识别(人脸识别、物体检测)
- 医疗影像分析
- 视频动作识别
🧱 核心组成
- 卷积层(Convolutional Layer)
- 池化层(Pooling Layer)
- 全连接层(Fully Connected Layer)
🖼️ 直观理解
想象用一个“放大镜”(卷积核)在图片上滑动,每到一处就计算局部区域的加权和,得到一张“特征图”。多个卷积核可提取多种特征。
✅ 优势:
- 参数共享:同一个卷积核扫全图 → 参数少
- 局部感受野:只关注小区域 → 模仿人眼
📐 关键公式
(1)卷积操作
输入图像:$$ \mathbf{X} \in \mathbb{R}^{H \times W \times C_{\text{in}}} $$
卷积核:$$ \mathbf{K} \in \mathbb{R}^{k \times k \times C_{\text{in}}} $$
输出特征图的一个元素:
🔍 解释:把卷积核盖在图像某块上,对应位置相乘再相加,最后加偏置。
(2)最大池化(Max Pooling)
常用 2×2 窗口取最大值:
作用:降维 + 保留强特征,防止过拟合。
🧩 代表网络
| 网络 | 贡献 |
|---|---|
| LeNet (1998) | 首个成功 CNN,用于手写数字识别 |
| AlexNet (2012) | 引入 ReLU + Dropout,引爆深度学习 |
| VGG (2014) | 小卷积核(3×3)堆叠,结构简洁 |
| ResNet (2015) | 残差连接,解决深层网络退化问题 |
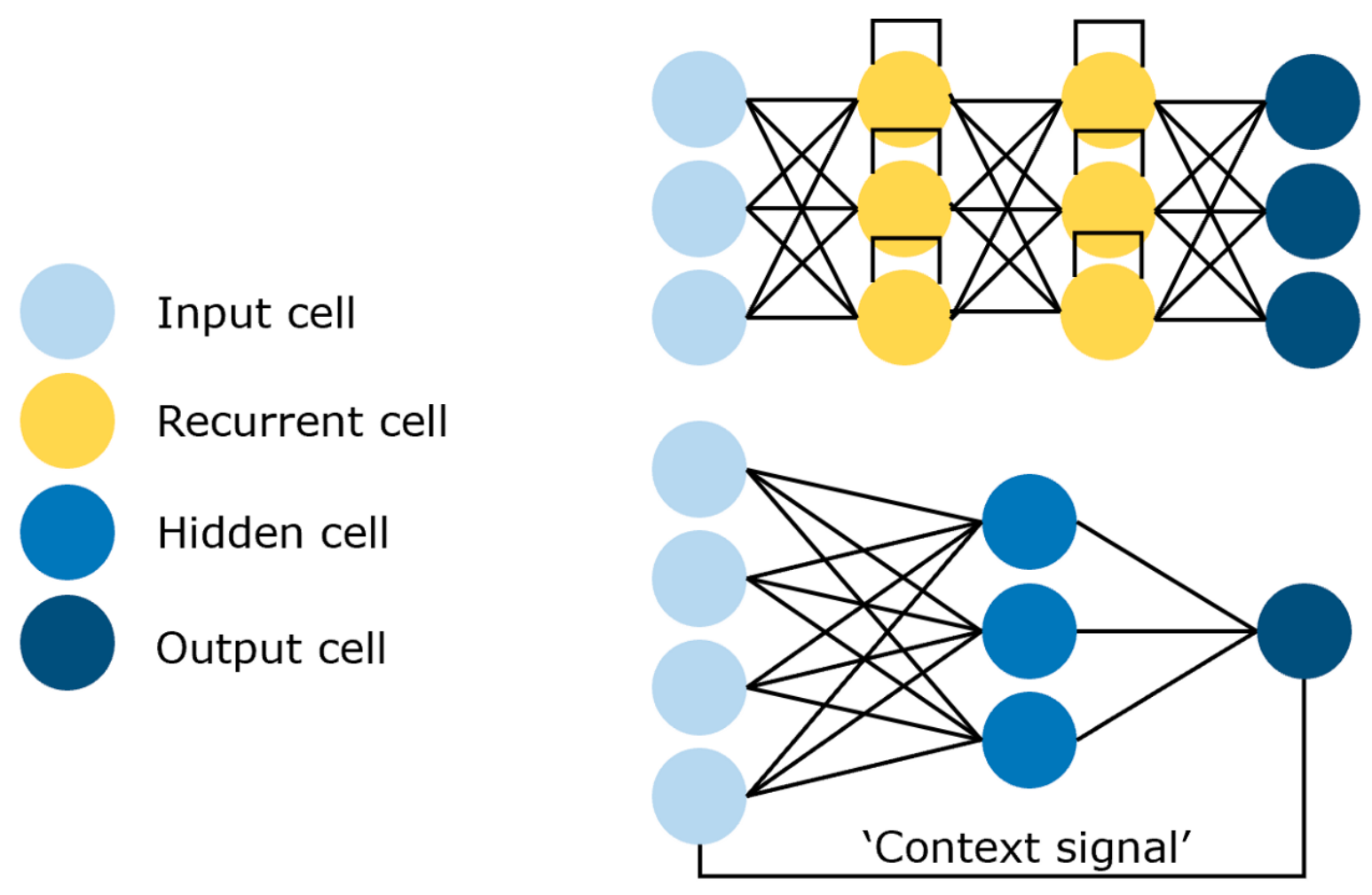
6. 循环神经网络(Recurrent Neural Network,RNN)
📌 描述
适用于序列数据(如句子、语音、时间序列),具有“记忆”能力:当前输出依赖当前输入 + 历史状态。
🎯 用途
- 自然语言处理(NLP)
- 语音识别
- 股票价格预测
🔄 直观理解
读句子“我今天吃了___”时,你会根据前面的词(“我”、“今天”、“吃了”)预测下一个词(“饭”)。RNN 就像一个带记忆的小盒子,每步更新内部状态。
📐 数学表达(单层 RNN)
对时间步 $ t $:
✅ 符号解释
| 符号 | 含义 |
|---|---|
| $ \mathbf{x}_t $ | 当前时刻输入 |
| $ \mathbf{h}_t $ | 当前隐藏状态(“记忆”) |
| $ \mathbf{W}_{hh} $ | 隐藏状态自循环权重 |
| $ \sigma $ | 激活函数(常用 tanh) |
⚠️ 问题:长序列时梯度会消失或爆炸 → 前面信息学不到。
🔑 改进模型
| 模型 | 特点 |
|---|---|
| LSTM | 引入遗忘门、输入门、输出门,精准控制记忆 |
| GRU | 简化版 LSTM,只有重置门和更新门,更快 |
7. 生成对抗网络(Generative Adversarial Network,GAN)
📌 描述
由两个网络组成:
- 生成器 G(Generator):造假者,生成假数据
- 判别器 D(Discriminator):警察,判断真假
两者对抗训练,最终 G 能生成以假乱真的数据。
🎯 用途
- 图像生成(人脸、艺术画)
- 风格迁移(照片 → 油画)
- 数据增强(生成更多训练样本)
- 超分辨率(低清 → 高清)
🎭 直观比喻
- G:造假币的人
- D:验钞警察
G 不断改进假币,D 不断提升识别能力,最终 G 的假币连 D 都分不清。
📐 数学原理(极小极大博弈)
目标函数:
✅ 符号解释
| 符号 | 含义 |
|---|---|
| $ \mathbf{x} $ | 真实数据(如真实人脸) |
| $ \mathbf{z} $ | 随机噪声(如从正态分布采样) |
| $ G(\mathbf{z}) $ | 生成器造出的假数据 |
| $ D(\cdot) $ | 判别器输出“是真数据”的概率(0~1) |
🔁 训练方式:交替优化
- 固定 G,训练 D(更好分辨真假)
- 固定 D,训练 G(更好骗过 D)
理想状态:$ D(G(\mathbf{z})) \approx 0.5 $ → 假数据和真数据无法区分。
🧩 代表模型
| 模型 | 特点 |
|---|---|
| DCGAN | 用 CNN 实现 G 和 D,图像质量大幅提升 |
| StyleGAN | 可控制生成人脸的风格(发型、肤色等) |
| CycleGAN | 无需配对数据,实现风格转换(马 ↔ 斑马) |
⚠️ 挑战:训练不稳定、模式崩溃(只生成少数样本)
✅ 总结对比
| 网络 | 适用数据 | 核心特点 | 典型任务 |
|---|---|---|---|
| FNN | 通用向量 | 全连接、无记忆 | 简单分类、回归 |
| CNN | 图像/网格 | 卷积 + 池化 | 图像识别、检测 |
| RNN | 序列 | 隐藏状态传递 | NLP、语音、时序预测 |
| GAN | 任意(需生成) | 对抗训练 | 图像生成、风格迁移 |