前言
本章节主要介绍pwn学习中涉及到的基础知识部分[1]。
程序的编译与链接
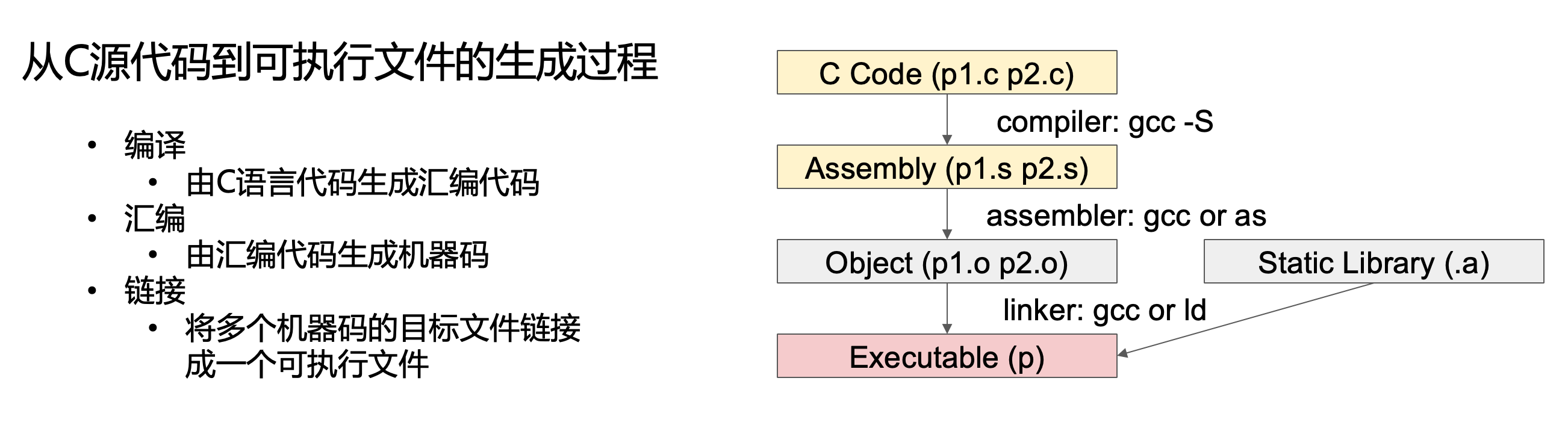
C语言代码 —> 会变代码 —> 机器码

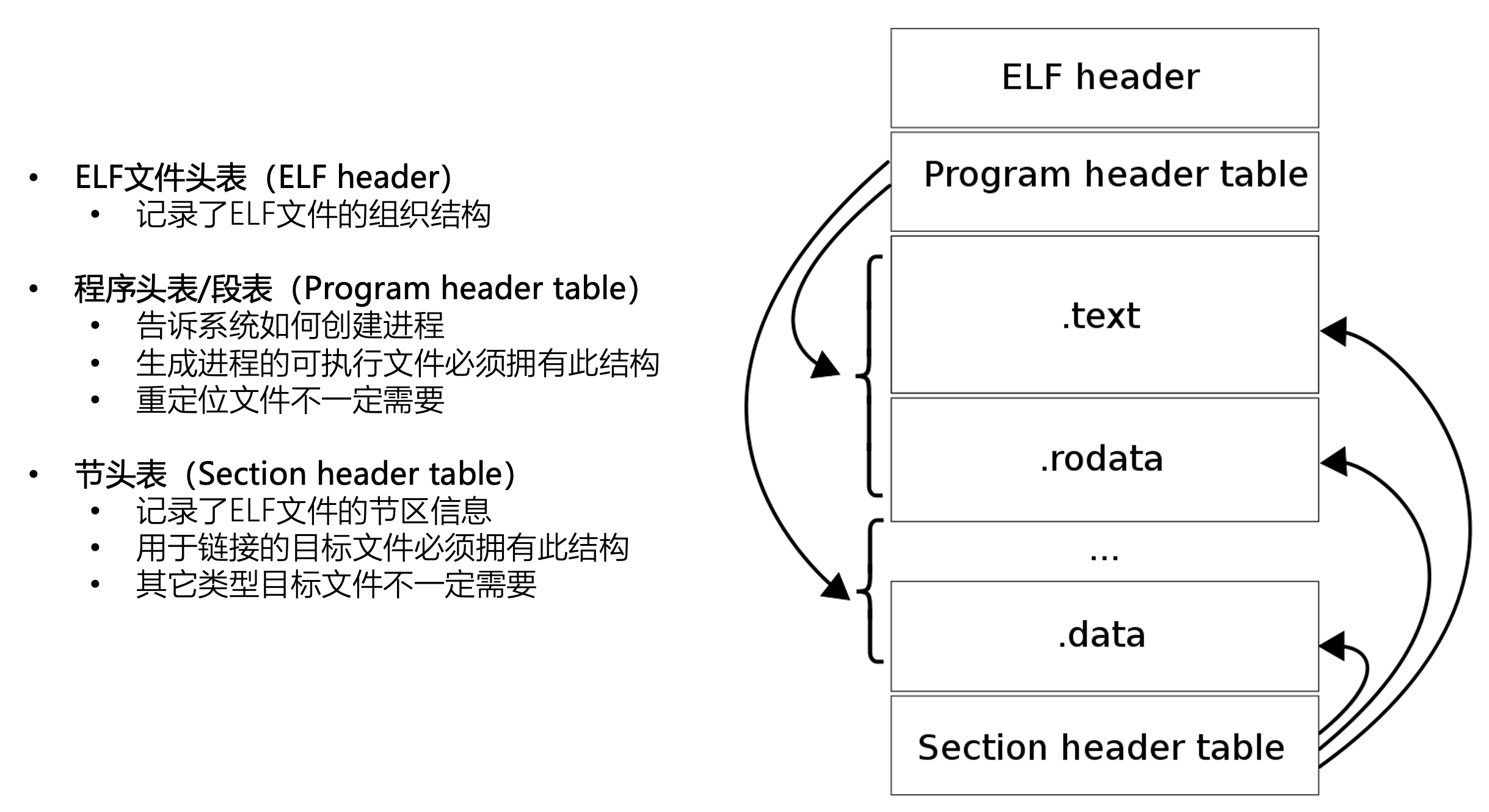
Linux下的可执行文件格式ELF
可执行文件分类:PE、ELF

可执行文件的组成
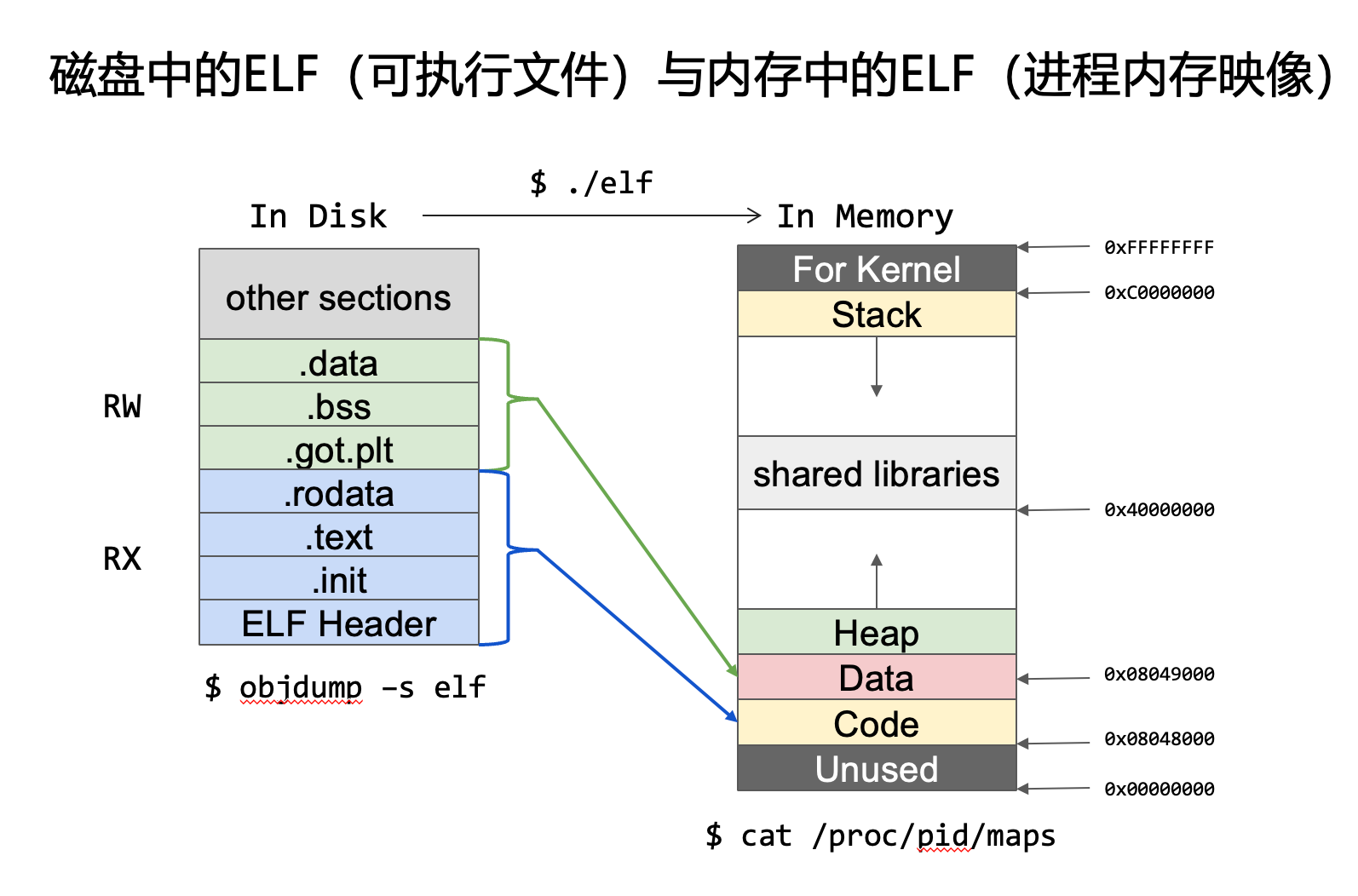
可执行文件的映射
栈在内存(stack)中是自高地址向低地址增长,堆(heap)是低地址向高地址增长。这个要牢记!!📢
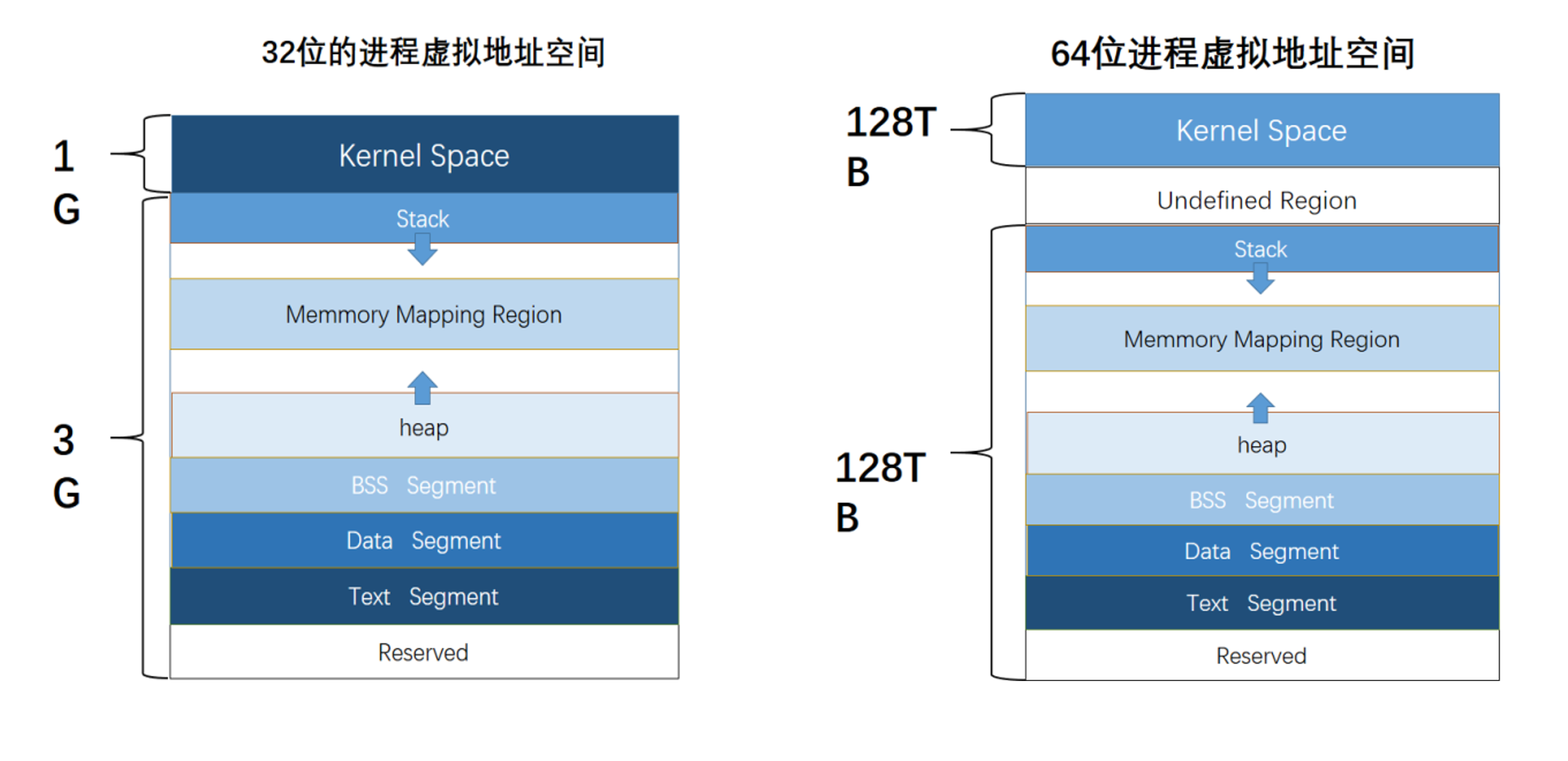
进程虚拟地址空间
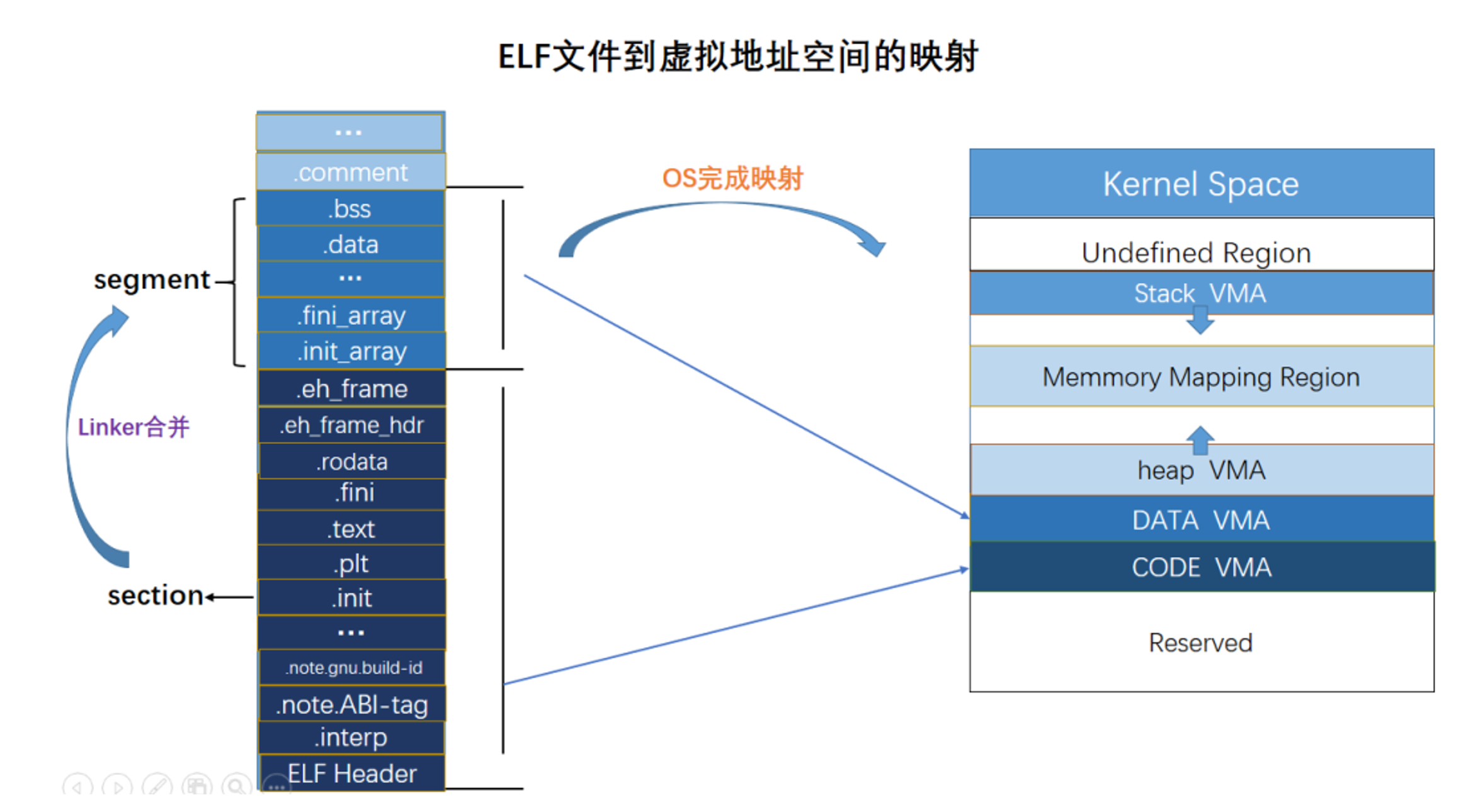
ELF文件到虚拟地址空间的映射
32位和64位进程虚拟地址空间
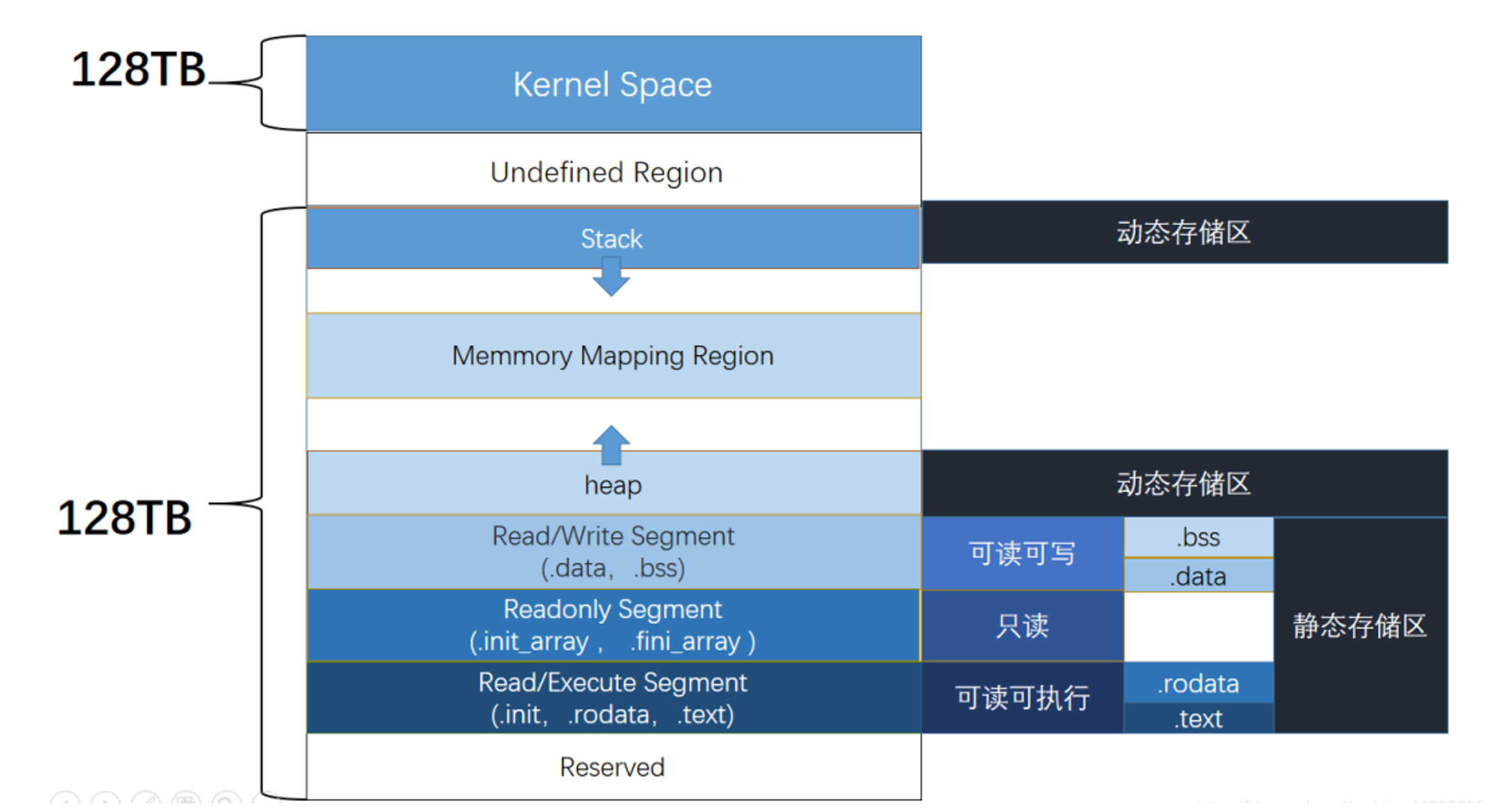
段segment与节section

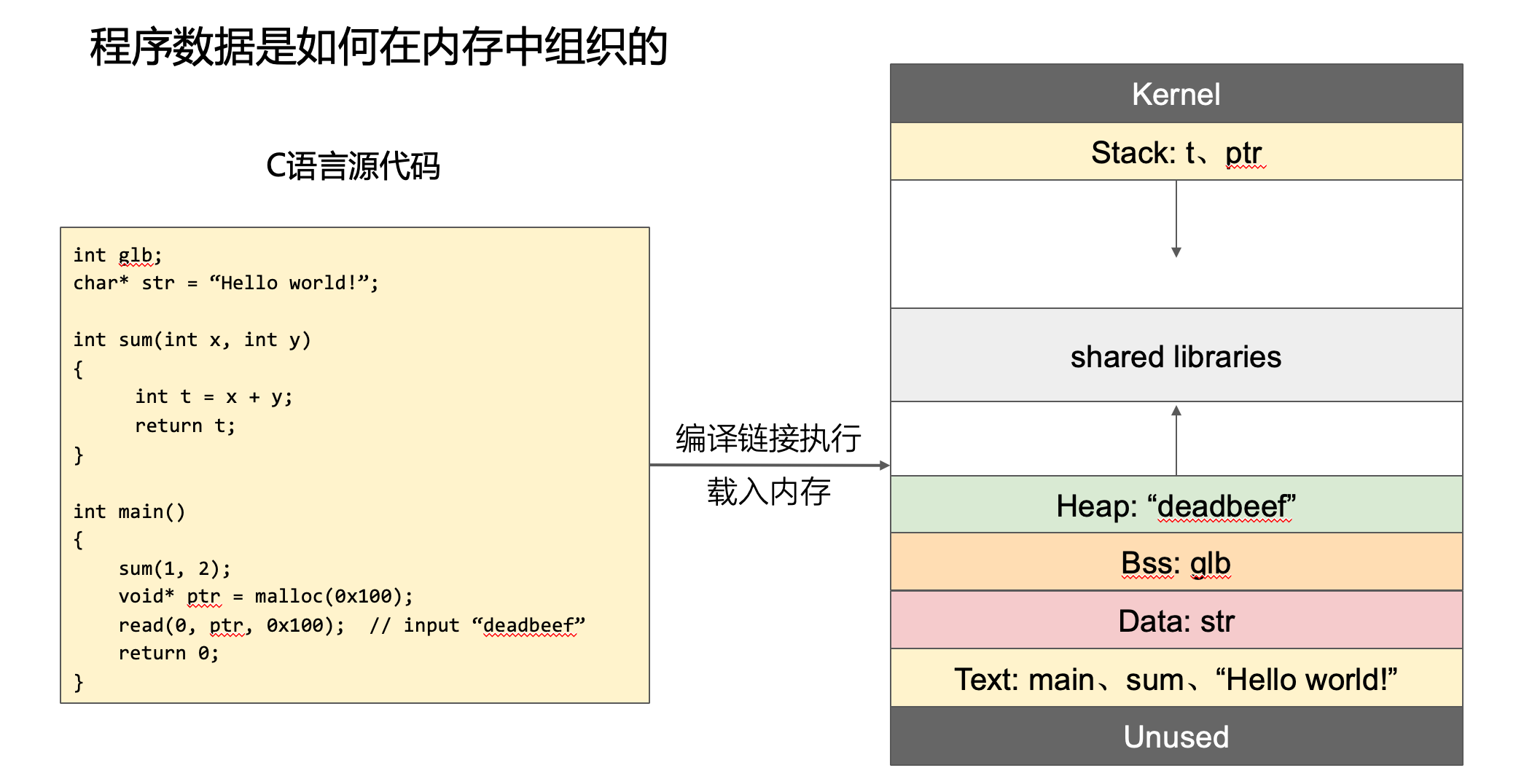
程序的编译与链接
大端序和小端序
对于十六进制0x0A0B0C0D的数据是,数据从右到左,左高位,右低位。
- 小端序⚠️
数据低位存放低地址,数据高位存放高地址
- 大端序⚠️
数据低位存放高地址,数据高位存放低地址

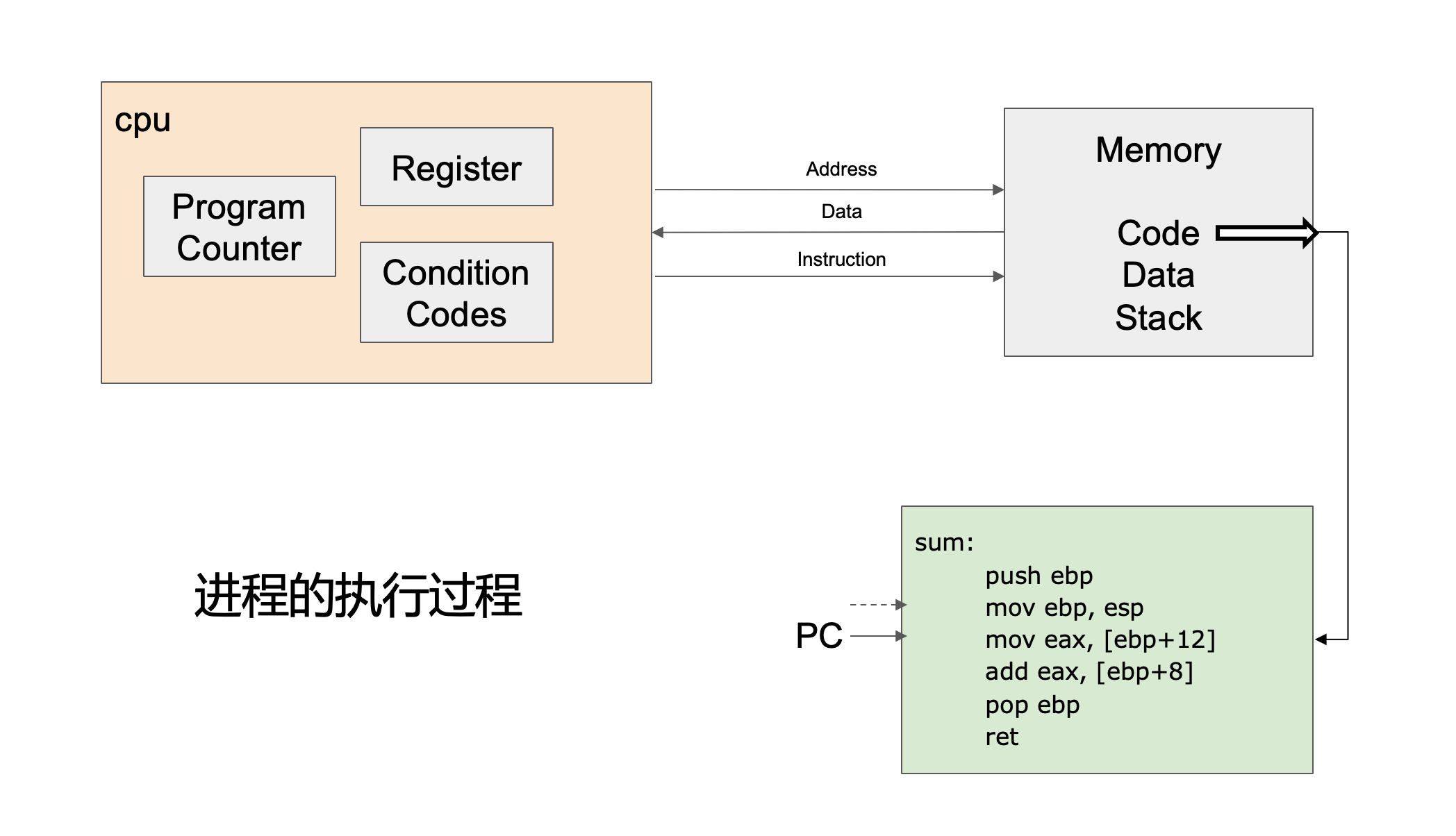
进程的执行过程
CPU的组成部分:
- Program Counter(PC,程序计数器)
保存下一条要执行的指令的地址⚠️。CPU会根据PC去内存中取指令。
- Register(寄存器)
CPU内部的高速寄存器,用来临时保存数据、地址等。
- Condition Codes(条件码寄存器)
保存上一次运算的状态(比如结果是否为零、是否溢出、是否为负数,在分支或判断)
Memory(内存):
- Code(代码区):存放程序的指令。
- Data(数据区):存放全局变量、静态变量等。
- Stack(栈区):存放函数调用的局部变量、参数、返回地址等。
指令执行流程:
-
程序计数器 (PC) 指向下一条要执行的指令地址。
-
CPU 根据 PC 从内存的 代码区 取出指令。
-
CPU 执行这条指令,可能涉及寄存器运算、内存访问、条件跳转。
-
PC 自动更新,指向下一条指令。
-
循环往复,直到程序结束。
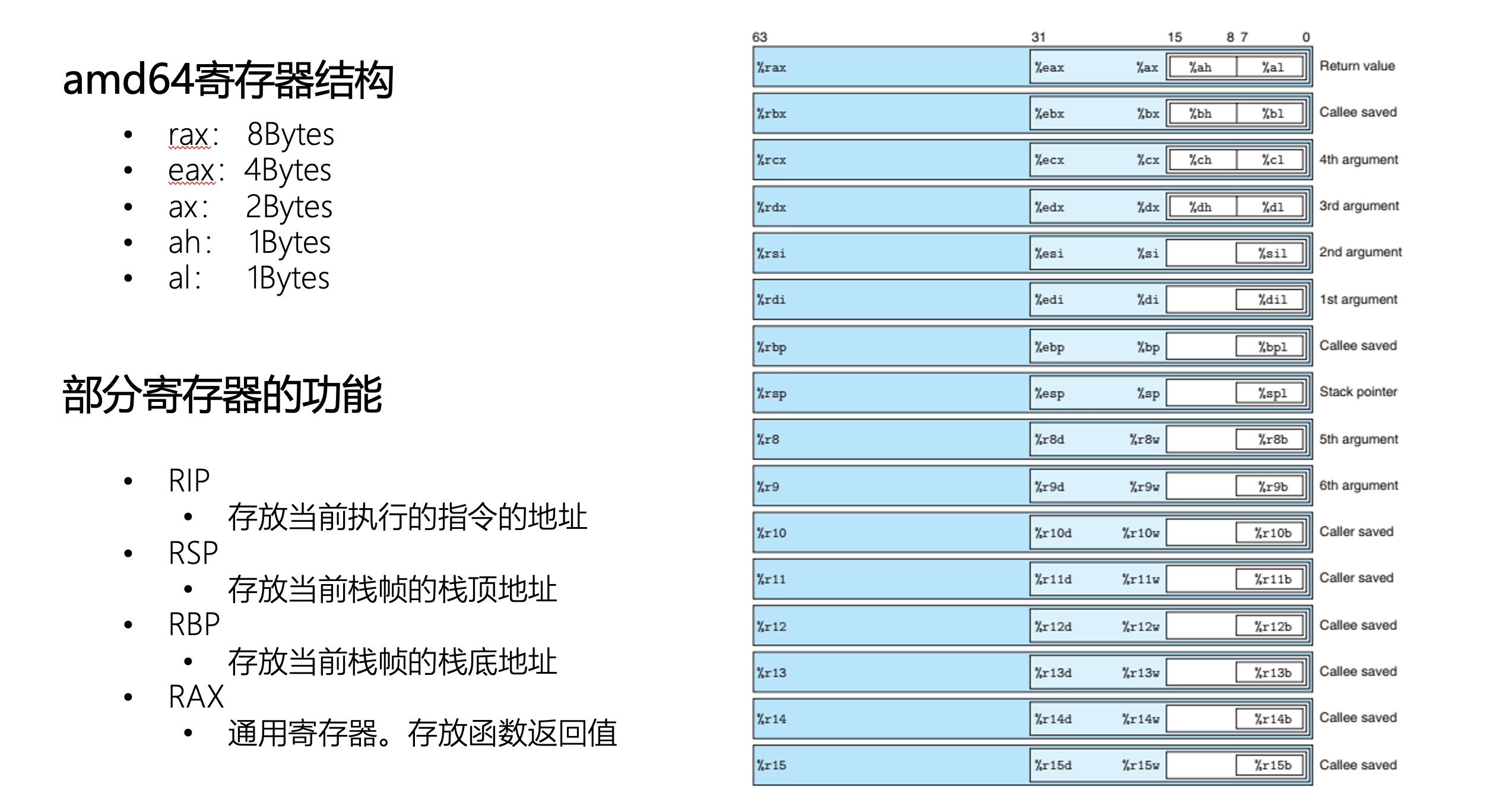
amd64寄存器
在 AMD64(即 x86-64 架构)里,每个寄存器有不同的访问方式:
- rax: 64位(8字节) → 全寄存器
- eax: 32位(4字节) → rax 的低 32 位
- ax: 16位(2字节) → eax 的低 16 位
- ah: 8位(高8位) → ax 的高字节
- al: 8位(低8位) → ax 的低字节
👉 也就是说,rax 是“大哥”,eax、ax、ah、al 都是它的不同切片。
例如:
1 | rax = 0x1234567890ABCDEF |
寄存器的功能:
常见的一些专用寄存器:
- RIP
程序寄存器,存放当前执行指令的地址。
在 x86-64 中,指令执行时 RIP 会自动增加。
- RSP(Stack Pointer)
栈顶指针,存放当前栈顶地址,方便访问局部变量和参数。
- RBP(Base Pointer)
栈基址指针,存放当前栈帧的基底地址,方便访问局部变量和参数。
- RAX
通用寄存器,函数返回值默认存放在RAX。
例如:int add(int a,int b)的返回值会放在RAX。
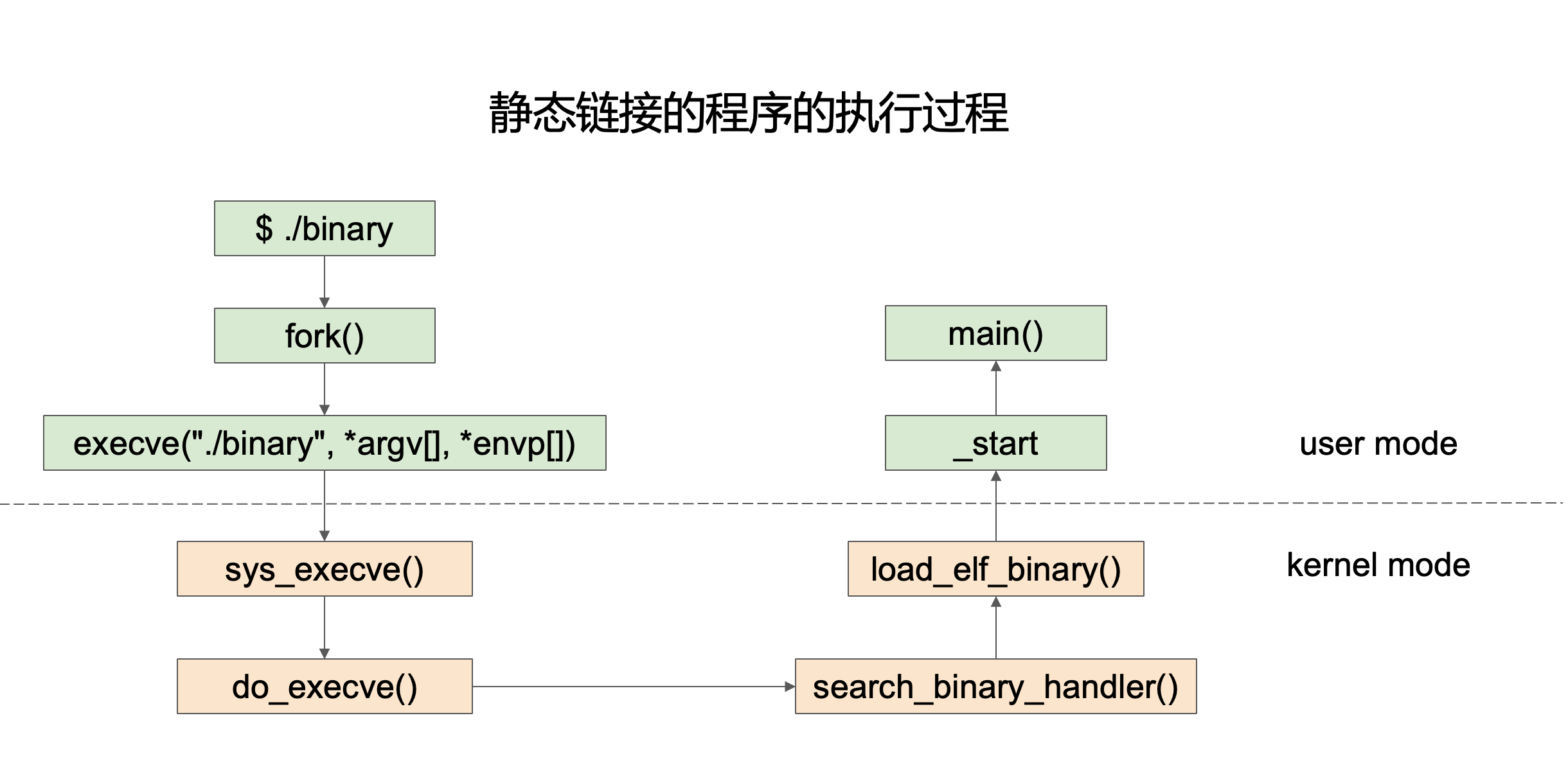
静态链接程序的执行过程
这里解释一下整个过程
- 用户输入命令
用户在shell输入./binary来运行一个可执行文件binary。
- fork()
-
shell 会先调用 fork() 创建一个子进程。
-
子进程将来会用来执行
./binary,而父进程(shell)继续等待。
- execve()
在子进程中,调用:
1 | execve("./binary", argv[], envp[]); |
argv[]:命令行参数envp[]:环境变量
👉 这一步是关键,它会用新的可执行文件 替换掉子进程当前的进程映像。简单理解,就是把原来进程里面的东西用新进程的内容覆盖掉,这样这个进程执行的就是新的内容。
举个例子:
1 |
|
输出:
1 | before exec |
解释:
"before exec"是旧进程打印的。- 调用
execve后,进程的映像被替换成/bin/ls。 - 所以
"after exec"永远不会打印出来,因为原来的main已经不存在了。
- 进入内核态
调用 execve() 后,程序切入 内核态,由内核来完成实际的加载工作:
(1)sys_execve()
- 内核提供的系统调用接口,处理用户传入的参数。
(2)do_execve()
- 内核进一步处理 exec 请求,准备加载二进制文件。
(3)search_binary_handler()
- 根据文件格式(比如 ELF, a.out, 脚本等),找到对应的“处理器”。
- 如果是 ELF 文件,就会调用
load_elf_binary()。
(4)load_elf_binary()
- 这是 ELF 文件的加载器。
- 它会把可执行文件的代码段、数据段等映射到进程的虚拟地址空间里,设置入口点,准备栈(参数、环境变量)。
- 返回用户态
内核完成加载后,CPU 的控制权转回 用户态,并从程序的入口点 _start 开始执行。
- _start
-
_start是 C 运行时库 (crt) 提供的入口函数(不是用户写的)。 -
它负责:
-
初始化运行环境(堆、栈、全局变量)
-
调用
main(argc, argv, envp) -
等
main()返回后调用exit()结束进程
-
- main()
最终,用户写的 main() 被调用,程序正式运行。
整体的流程如下:
1 | 用户输入命令 → shell fork子进程 → execve → 内核加载 ELF → 内核返回用户态 → 执行 _start → 调用 main() |
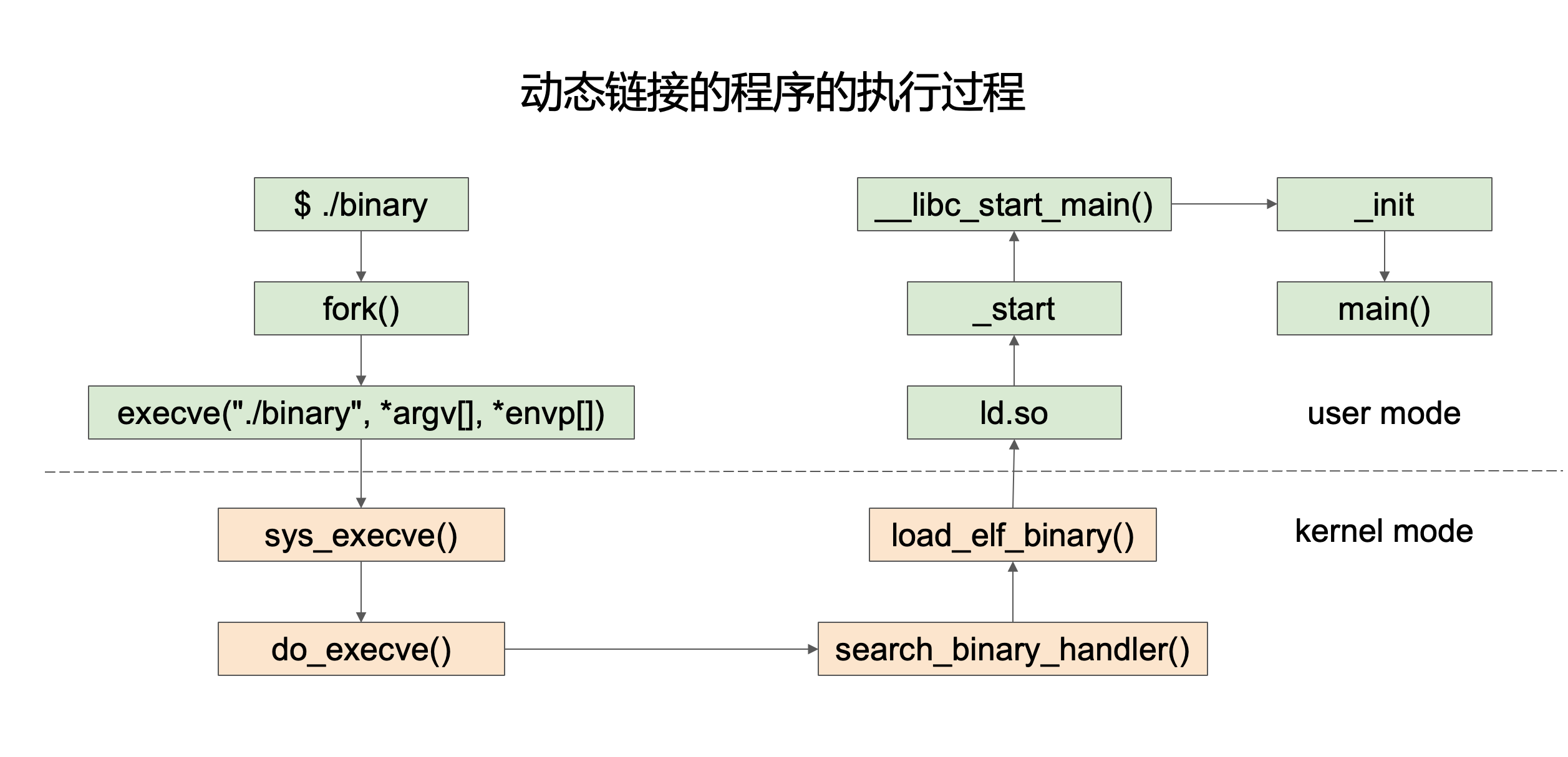
动态链接程序的执行过程
下面介绍一下动态链接的程序在Linux上从执行到main函数,主要经历四大步骤,涉及用户Shell、操作系统内核、动态连接器和C库的四个角色的接力协作。
可以想象成一场四人接力赛:
第一棒:用户Shell(发令枪)
- 接收命令:你在终端里输入
./binary并按下回车。 - 创建子进程 (
fork):Shell 会复制一个自己出来,创建一个新的子进程。 - 请求加载程序 (
execve):这个新的子进程会立刻请求操作系统内核:“请把我清空,然后用./binary这个新程序来替换我。” 这个请求是通过execve系统调用完成的,它也是从用户态进入内核态的“大门”。
交接:Shell 把接力棒(控制权)通过系统调用交给了内核。
第二棒:Linux内核(场地准备员)
- 检查文件:内核接手后,读取
binary文件。它会识别出这是一个 ELF 格式的文件,并发现文件里有一个特殊的“便签”,上面写着:“我需要一个解释器(Interpreter)来帮我运行,它的名字是ld-linux.so”。 - 加载入内存:内核明白了,这个程序不是“独立选手”。于是,它将两样东西加载到内存里:
- 你的程序
binary。 - 那个叫做
ld-linux.so的动态链接器。
- 你的程序
- 设定入口:内核完成加载后,把起跑点设置在动态链接器的入口,而不是你的程序的入口。
交接:内核准备好场地和两位选手(你的程序和链接器)后,把接力棒交给了动态链接器。
第三棒:动态链接器 ld.so (后勤组装员)
- 分析依赖:动态链接器是第一个在用户态运行的代码。它开始检查你的
binary,看它到底依赖了哪些共享库(比如最常见的libc.so,里面有printf、malloc等函数)。 - 加载依赖库:它在系统中找到这些
.so共享库文件,并将它们也加载到程序的内存空间里。 - 地址重定位 (Relocation):这是最关键的一步。你的程序在调用
printf时,并不知道它在内存的哪个具体地址。链接器的工作就是修复所有这些“临时地址”,把它们指向刚刚加载进来的libc.so中printf函数的真实地址。这个过程就像是把所有分散的零件组装起来。
交接:链接器把所有零件都组装好、连接好之后,把接力棒交给了你的程序。
第四棒:C语言运行时库(最后的准备)
程序入口 (_start):链接器将控制权交给程序的正式入口 _start。这不是 main 函数,而是 main 函数的“热场”代码,由 C 运行时库提供。
环境初始化 (__libc_start_main):_start 会调用 C 库里的一个准备函数(__libc_start_main),这个函数会进行调用 main 函数前的最后准备,比如:
- 设置命令行参数
argc和argv。 - 确保标准输入/输出可用。
- 注册程序退出时需要运行的清理函数。
调用 main:万事俱备,__libc_start_main 函数正式调用我们自己写的 main() 函数。
x86&amd64汇编简述
下面我们介绍一下x86&amd64的汇编代码

数据传输指令
MOV(Move)
功能: MOV 指令用于将数据从一个位置复制到另一个位置。这是汇编中最基本、最频繁使用的指令之一。
语法: MOV Destination, Source
解释: 这条指令会把 Source(源)操作数的值复制到 Destination(目标)操作数。源操作数可以是立即数(一个具体的数值)、寄存器或内存地址;目标操作数可以是寄存器或内存地址。值得注意的是,MOV 只是“复制”,源操作数的值在操作后并不会改变。
示例:
MOV EAX, 10; 将立即数 10 移动到 EAX 寄存器。MOV EBX, EAX; 将 EAX 寄存器中的值复制到 EBX 寄存器。MOV [ESI], AL; 将 AL 寄存器(EAX的低8位)中的值存入 ESI 寄存器所指向的内存地
LEA(Load Effective Address)
功能: LEA 指令用于将一个内存地址的有效地址(偏移量)加载到目标寄存器中,而不是加载该地址处的数据。
语法: LEA Destination, [Source]
解释: 这条指令看起来和 MOV 有点像,但它们有本质区别。MOV 操作的是数据,而 LEA 操作的是地址。它主要用来进行地址计算,并且计算结果存放在目标寄存器中。它不会访问内存去读取数据。因为这个特性,它也经常被巧妙地用来执行一些不涉及内存访问的算术运算。
示例:
LEA EAX, [EBX + ECX*4 + 100]; 计算地址EBX + ECX*4 + 100,然后将计算出的地址值(一个整数)存入 EAX 寄存器。这个过程不读取内存。MOV EAX, [EBX + ECX*4 + 100]; 这条MOV指令则会计算同样的地址,然后访问这个内存地址,并将该地址处的数据加载到 EAX 寄存器。
算术与逻辑运算指令
ADD/SUB (Add/Subtract)
- 功能: 这两个指令分别用于执行加法和减法运算。
- 语法:
ADD Destination, SourceSUB Destination, Source
- 解释:
ADD:将Destination和Source的值相加,结果存回Destination。 (Destination = Destination + Source)SUB:从Destination中减去Source的值,结果存回Destination。 (Destination = Destination - Source)
- 示例:
ADD EAX, 15; EAX = EAX + 15SUB EBX, ECX; EBX = EBX - ECX
CMP(Compare)
功能: CMP 指令用于比较两个操作数,但它不保存结果,而是根据比较结果来设置CPU中的标志寄存器(Flags Register)。
语法: CMP Operand1, Operand2
解释: 该指令的功能类似于 SUB 指令(Operand1 - Operand2),但它不会将结果存回 Operand1。它只是根据运算结果来更新标志位,如零标志位(ZF)、符号标志位(SF)和溢出标志位(OF)等。后续的条件跳转指令(如 J[Condition])会根据这些标志位的状态来决定是否跳转。
示例:
CMP EAX, EBX; 比较 EAX 和 EBX 的值。- 如果
EAX == EBX,则ZF(零标志位)被设为1。 - 如果
EAX < EBX,则SF(符号标志位)通常会被设为1(表示结果为负)。 - 如果
EAX > EBX,则ZF和SF都为0。
- 如果
堆栈操作指令
堆栈(Stack)是一个后进先出(LIFO, Last-In, First-Out)的数据结构。前面我们也说过,栈在内存中是从高地址向低地址增长的。
PUSH(Push on Stack)
功能: 将一个操作数压入栈顶。
语法: PUSH Source
解释: 这个指令会先将栈顶指针(ESP)减去一个单位(通常是4字节,取决于操作数大小),然后在新的栈顶地址处存入 Source 的值。
示例:
PUSH EAX; 将 EAX 寄存器的值(4字节)压入堆栈。
POP(Pop from Stack)
功能: 从栈顶弹出一个数据到目标操作数。
语法: POP Destination
解释: 这个指令会先将栈顶的数据复制到 Destination,然后将栈顶指针(ESP)加上一个单位(通常是4字节)。
示例:
POP EBX; 从栈顶弹出一个值到 EBX 寄存器。
控制流指令
这些指令用来改变程序的执行流程,而不是按顺序执行。
JMP(Jump)
功能: 无条件跳转。执行该指令后,程序的执行流会立即跳转到指定的目标地址。
语法: JMP Target
解释: 这条指令会直接修改指令指针寄存器(EIP)的值为 Target 的地址,从而改变程序的执行路径。
示例:
JMP MyLabel; 跳转到名为 MyLabel 的代码行。
J[Condition] (Conditional Jump)
功能: 条件跳转。这类指令会先检查标志寄存器中的特定标志位,只有当条件满足时,才会执行跳转。
语法: J<condition> Target
解释: 这类指令通常紧跟在 CMP 或其他会影响标志位的指令之后。[Condition] 代表了不同的跳转条件。
常见示例:
JE(Jump if Equal) /JZ(Jump if Zero): 如果相等(ZF=1)则跳转。JNE(Jump if Not Equal) /JNZ(Jump if Not Zero): 如果不相等(ZF=0)则跳转。JG(Jump if Greater) /JNLE(Jump if Not Less or Equal): 如果(有符号数)大于则跳转。JL(Jump if Less) /JNGE(Jump if Not Greater or Equal): 如果(有符号数)小于则跳转。JGE(Jump if Greater or Equal): 如果(有符号数)大于或等于则跳转。JLE(Jump if Less or Equal): 如果(有符号数)小于或等于则跳转。JA(Jump if Above): 如果(无符号数)大于则跳转。JB(Jump if Below): 如果(无符号数)小于则跳转。
CALL(Call a Procedure)
功能: 调用一个子程序(或函数)。
语法: CALL Target
解释: CALL 指令做了两件事:
- 将
CALL指令的下一条指令的地址压入堆栈。这个地址被称为“返回地址”,以便子程序执行完毕后能回到正确的位置继续执行。 - 无条件跳转到
Target指定的子程序地址。
示例:
CALL MyFunction; 调用 MyFunction 函数。
RET(Return from Procedure)
功能: 从子程序返回。
语法: RET
解释: RET 指令与 CALL 相对应。它从栈顶弹出一个地址到指令指针寄存器(EIP),使程序跳转回调用该子程序时的下一条指令处继续执行。
示例: 通常是子程序的最后一条指令。
LEAVE
功能: 销毁当前函数的栈帧,常用于函数返回前。
语法: LEAVE
解释: LEAVE 指令是一个高级指令,它等效于以下两条指令的组合:
MOV ESP, EBP; 将栈顶指针(ESP)恢复到栈底指针(EBP)的位置,相当于释放了为函数局部变量分配的栈空间。POP EBP; 从栈中弹出旧的 EBP 值,恢复调用者的栈帧。LEAVE指令通常与ENTER指令配对使用,用于简化函数进入和退出的代码,在高级语言编译成的汇编代码中非常常见。它后面紧跟着的往往就是RET指令。
参考
【XMCVE 2020 CTF Pwn入门课程】https://www.bilibili.com/video/BV1854y1y7Ro?p=3&vd_source=40fffae7c3c0198962dc9cf9689a1a8a ↩︎