前言
本文开头首先介绍一下编译文件使用所使用的动态链接和静态链接的差异,再详细讲解一下动态链接的过程。一般使用的二进制程序都是动态链接的,因为其文件更小,节省内存,所以重心是放在动态链接上。[1]
静态和动态链接文件的差异
在 Linux/Unix 系统里,可执行文件(ELF 格式居多)可以分为两种:
- 静态链接:所有依赖的库代码在编译时都被复制到可执行文件里,运行时不依赖外部库。
- 动态链接:可执行文件只包含“符号引用”,运行时由动态链接器(
ld.so/ld-linux.so)把需要的库加载到进程内存空间,然后把函数地址解析好。
动态链接的好处是:
- 节省内存(多个进程共享同一个
.so库副本); - 节省磁盘空间;
- 更新库更方便(比如升级
libc.so,所有程序都能受益)。
编译后文件的差异
动态链接一般比静态链接的文件大。静态链接其将库函数都写在了ELF文件中,所以编译后的文件比较大。动态链接只是将要用到的库函数标记一下,用到的时候直接调用,并没有直接写入到ELF文件中。
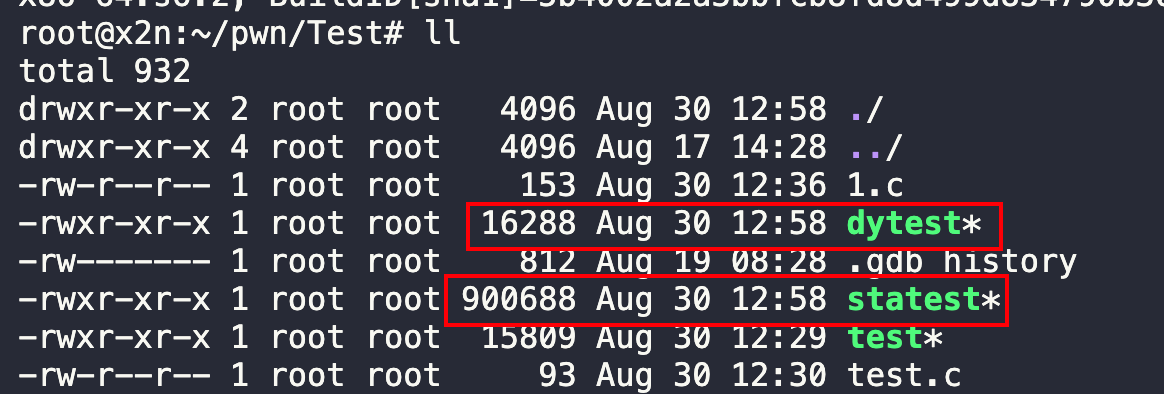
同样的文件1.c文件:
静态编译:
1 | gcc -fno-pie --static -o statest 1.c |
动态编译:
1 | gcc -fno-pie -no-pie -o dytest 1.c |
区别

静态的文件是明显比动态的大的。
动态链接的大致过程
可执行文件如何调用动态库函数?
流程大概分 编译期 和 运行期 两个阶段。
(1)编译/链接阶段
- 源代码中调用库函数(如
printf("hello\n");)。 - 编译器编译时,并没有把
printf的实现放进来,而是生成一个 符号引用。 - 链接器 (
ld) 把可执行文件和动态库的“符号表”关联,但不填充具体地址。 - 在可执行文件中,会生成 PLT(Procedure Linkage Table) 和 GOT(Global Offset Table) 用于后续跳转。
📌 举例:
在 main 里调用 printf,编译器会让它跳转到 plt[printf],而不是直接去 libc.so。
(2)运行阶段
运行时由动态链接器负责,流程是这样的:
- 加载 ELF
- 当你执行一个程序,内核的
execve会加载 ELF 文件,看到它依赖哪些共享库(在 ELF 的.dynamic段里)。 - 内核加载程序本体后,把动态链接器(
ld.so)也加载到进程空间。内核只负责加载程序本体和动态链接器,具体的共享库查找/加载工作由ld.so完成
- 当你执行一个程序,内核的
- 动态链接器查找库
- 动态链接器会在系统目录(如
/lib,/usr/lib)或LD_LIBRARY_PATH指定的路径里找到libc.so等库文件。 - 然后把这些库映射(
mmap)到进程内存。
- 动态链接器会在系统目录(如
- 符号解析与重定位
- 可执行文件中函数调用是通过 PLT 表。
- 第一次调用某个库函数时,程序跳转到
plt[func],plt会间接跳到got[func]。 got[func]最开始指向动态链接器的一个“解析函数”(resolver)。- 动态链接器(
ld.so)查找真正的符号地址(比如printf在libc.so的偏移),然后回写到got[func]。 - 之后的调用就可以直接通过
got跳到printf,不再需要解析。
这种机制称为 Lazy Binding(延迟绑定),好处是只解析真正用到的符号,提高启动速度。
如果用 LD_BIND_NOW=1 ./a.out,则会启用 Eager Binding,一开始就解析所有符号。
关键数据结构
- PLT(Procedure Linkage Table):保存一段“跳板”代码,程序调用库函数时跳到这里。
- GOT(Global Offset Table):保存函数或全局变量的实际地址。
- 动态链接器
ld.so:运行时负责加载库、解析符号、做重定位。
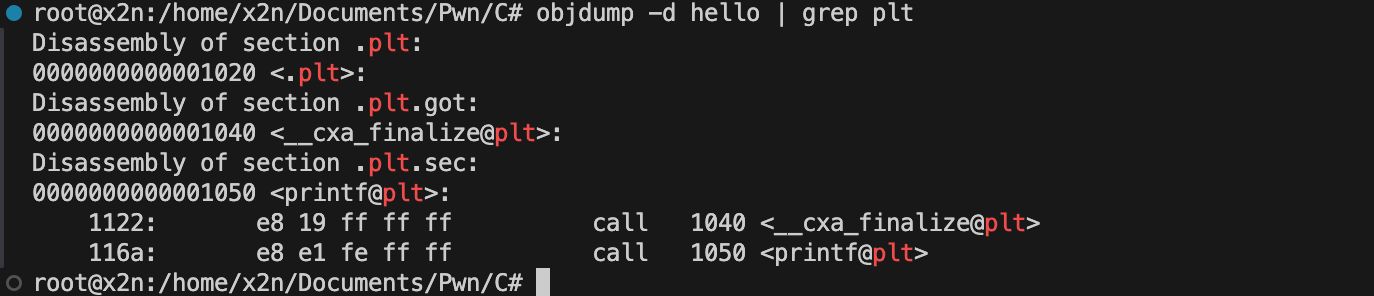
动态链接调用printf实际案例
1 |
|
编译:
1 | gcc -fno-builtin-printf hello.c -o hello |
查看依赖:
1 | ldd hello |

查看反汇编:
1 | objdump -d hello | grep plt |
运行时第一次调用 printf:
main -> printf@pltplt通过got里的入口跳到动态链接器 resolver- resolver 找到 libc.so 的
printf实际地址,更新got - 后续
printf调用直接跳到 libc.so 里的实现
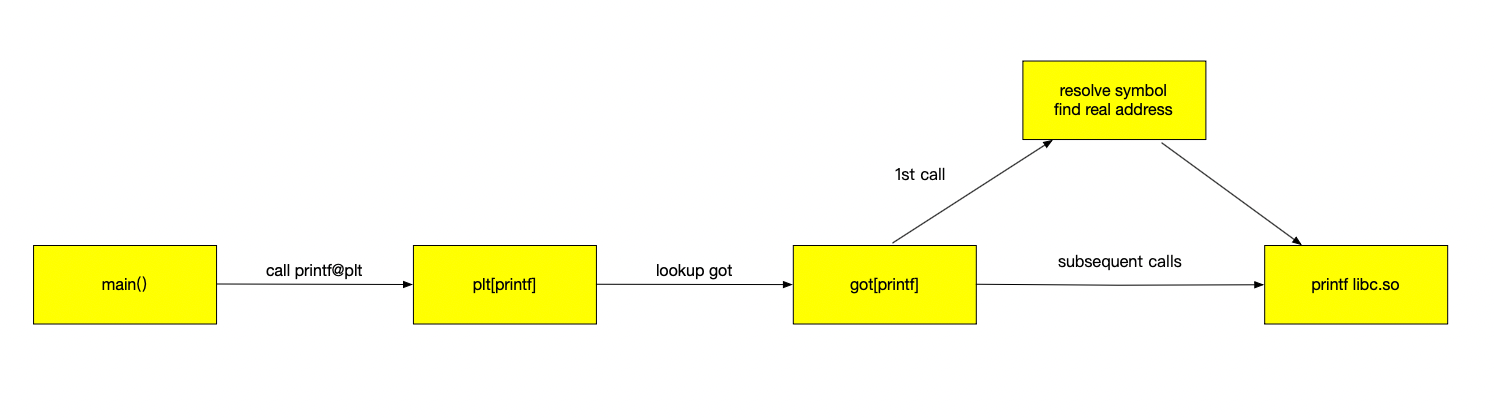
总结
动态链接的可执行文件调用库函数的核心机制是:
- 编译时 不嵌入库代码,只保留符号引用,生成 PLT/GOT 表。
- 运行时 动态链接器加载
.so,解析符号,把真实地址写入 GOT。 - 程序通过 PLT -> GOT -> 实际函数地址 的链路完成调用。
动态链接过程中相关结构
下面这些结构是只有动态链接的程序才有具有。
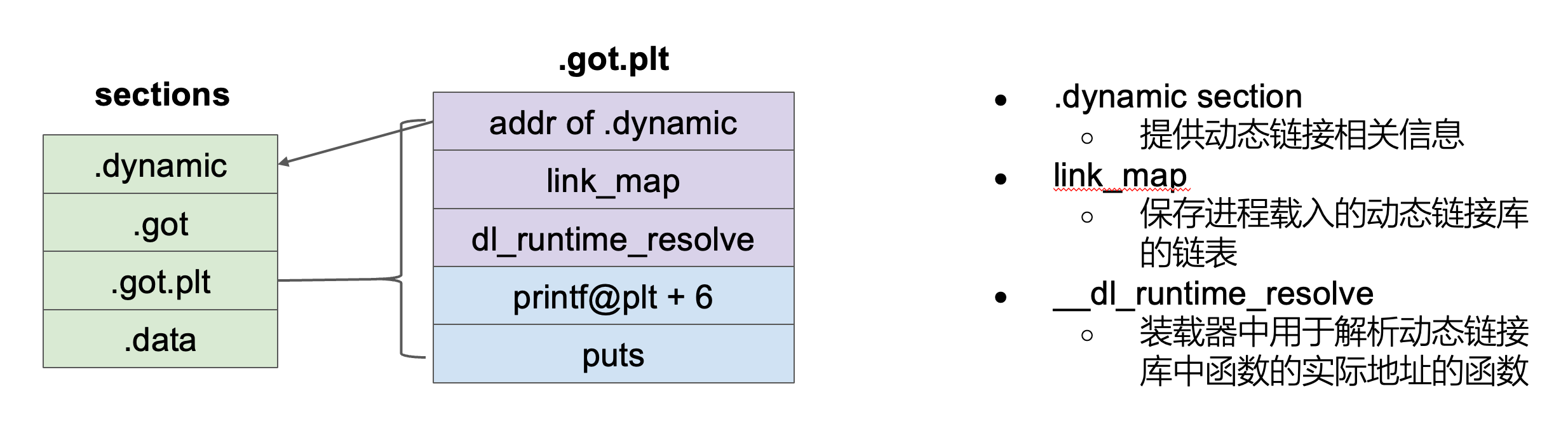
.dynamic section的作用
- 存储动态链接相关的信息
.dynamic包含一系列Elf32_Dyn或Elf64_Dyn结构体,每个结构体称为一个 动态条目(dynamic entry),用来告诉动态链接器如何处理这个 ELF 文件。 - 内容示例(常见的动态条目):
DT_NEEDED:依赖的共享库(比如 libc.so)DT_STRTAB:字符串表地址(函数名、库名等)DT_SYMTAB:符号表地址DT_PLTGOT:指向 .got.plt 的指针DT_INIT/DT_FINI:初始化函数、结束函数的地址DT_REL/DT_RELA:重定位表DT_DEBUG:调试相关的结构(gdb 用)
- 和 GOT/PLT 的关系
动态链接器(ld.so)在装载 ELF 时,会读取.dynamic段,根据里面的条目去解析符号、重定位 GOT/PLT 表项,从而在运行时将函数地址填充到.got.plt中。
换句话说:
.dynamic是一张“说明书”,告诉动态链接器要加载哪些库、符号表在哪、重定位信息在哪。- 动态链接器根据
.dynamic提供的这些信息,去修正(fixup).got.plt,使得程序调用外部函数时能找到正确的地址。
(这里的“修正”就是指,动态链接器在运行时 把函数的真实地址写入到对应的 .got.plt 表项中,替换掉原本的占位符,这里其实就是修之后,函数调用就可以直接跳转到目标函数的真实地址,而不需要再经过动态解析流程。)
.got.plt 的作用
.got.plt 的全称是 Global Offset Table for the Procedure Linkage Table,也就是 PLT 专用的 GOT 表。
.got.plt 属于 .got 表的一部分,而不是 .plt。⚠️⚠️⚠️(注意!!!)
它本质上还是 Global Offset Table (GOT),只不过是 GOT 里专门留给 PLT 使用的那部分。
主要作用
这部分通常被单独命名为 .got.plt,但它实际上还是 .got 段中的一个子区间。
-
存放动态链接函数的地址
-
程序调用外部库函数(比如
printf、puts)时,真正的函数地址在编译时是未知的。 -
.got.plt就是用来存放这些函数在运行时的真实地址。
-
-
支持延迟绑定(Lazy Binding)
- 一开始
.got.plt表项指向的是 PLT 的下一条指令(即plt+6),会触发动态链接器去解析函数地址。 - 当第一次调用某个函数时,动态链接器(
ld.so)会解析符号,找到函数在共享库中的实际地址,然后把地址写回.got.plt表项。 - 后续再次调用该函数时,程序直接从
.got.plt里取到真实地址,不需要再调用动态解析器。
- 一开始
流程示例
以 printf() 调用为例:
- 程序调用
printf@plt→ 跳到.plt段。 .plt里第一步会查.got.plt里对应的表项。- 如果是第一次调用,表项指向
__dl_runtime_resolve(动态解析函数)。 - 动态链接器解析
printf的真实地址。
- 如果是第一次调用,表项指向
- 动态链接器把解析出的
printf地址写回.got.plt。 - 下次再调用
printf@plt,直接跳转到.got.plt里的真实地址,不再触发解析。
👉 总结一句话:
.got.plt 就是一张“跳转表”,用来存放外部函数在运行时的真实地址。它配合 .plt 实现了 延迟绑定,让程序在第一次调用时解析地址,后面就能直接调用。
动态解析整个动态链接的过程
假设代码中调用了一个在动态链接库中名为foo的函数,下面使用图演示
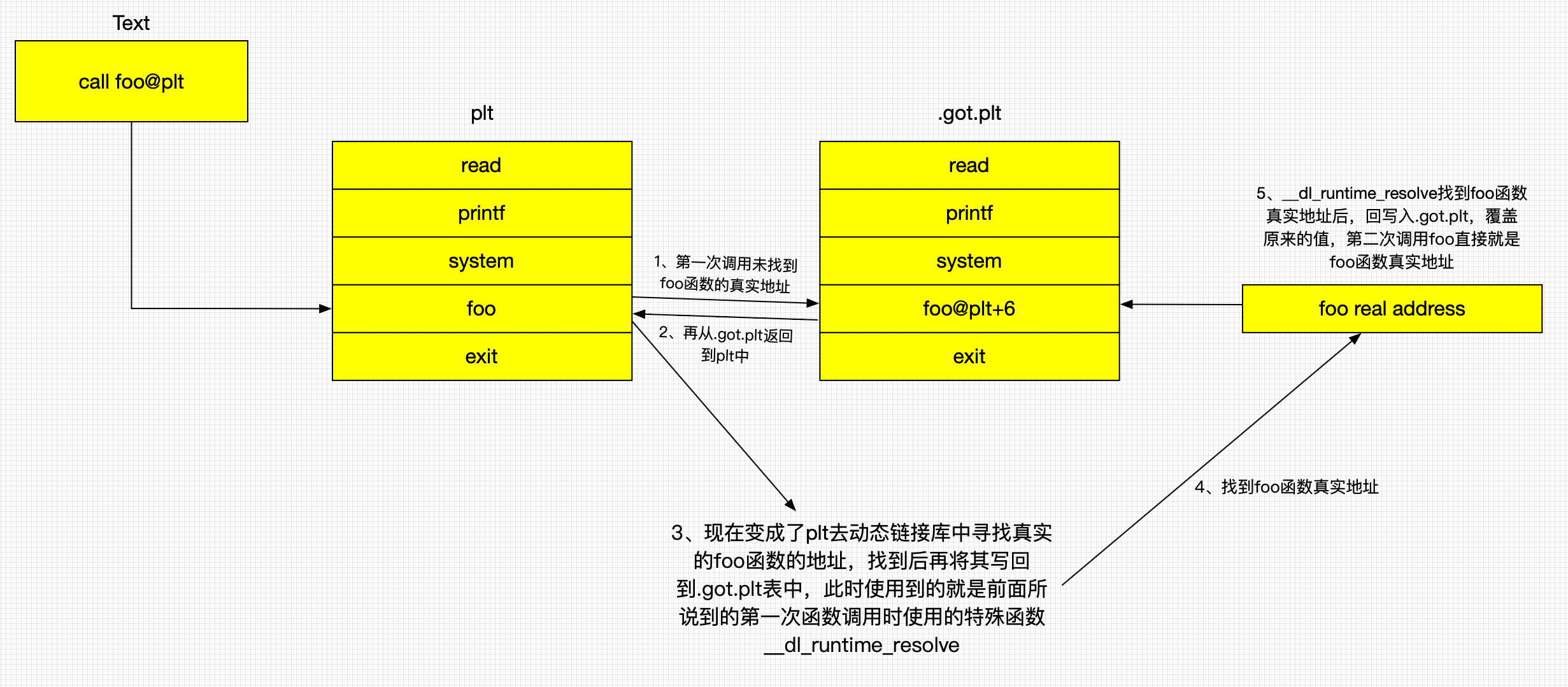
进程首次调用foo
这里的.text就是用户写的代码,foo就是我们代码中调用的动态链接库的代码,plt是程序中代码段里的一个保存了解析函数真实地址的一个节[2],plt0是plt最开始的两段指令。.got.plt里面保存的数组,它存放的位置是数据段。
首先是.text代码段调用foo函数。
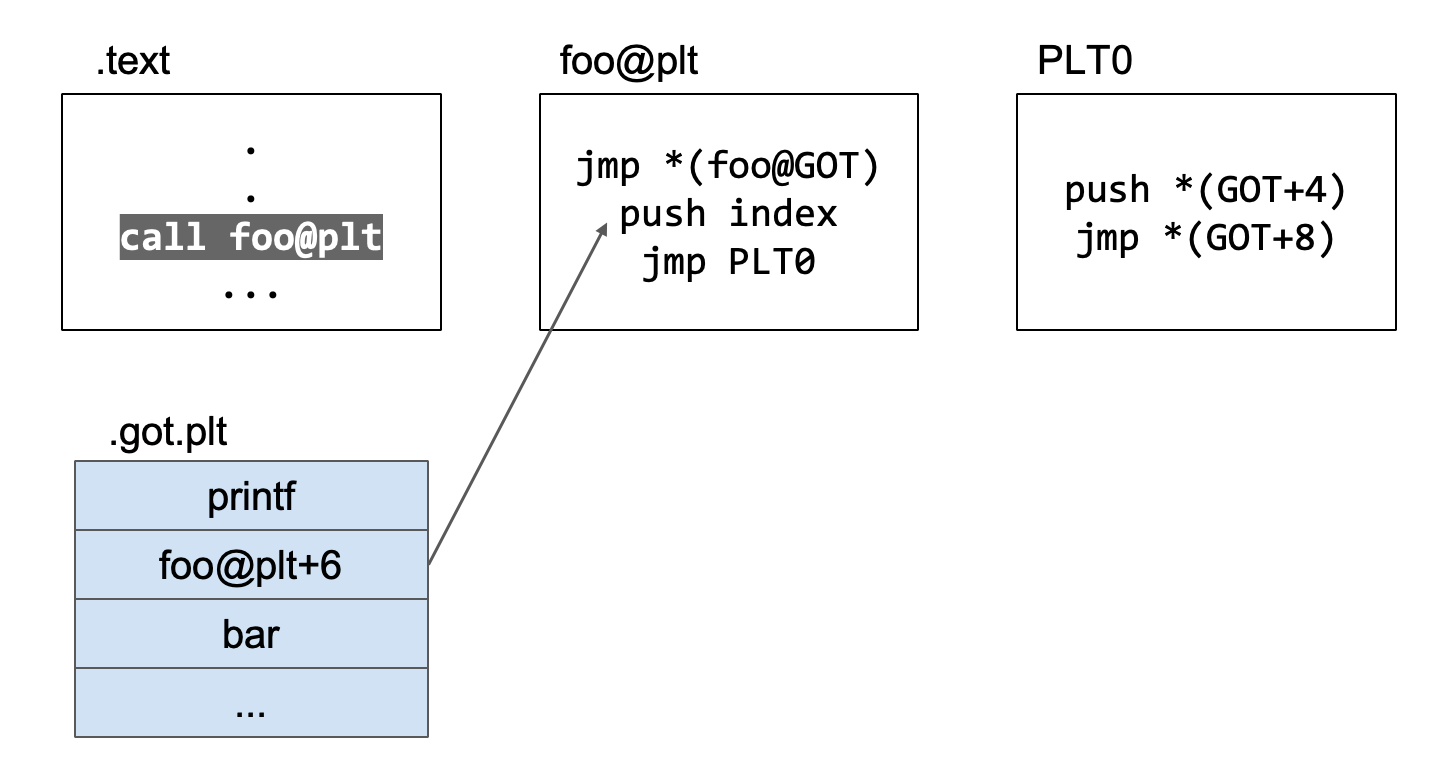
跳转到.plt中的foo表项
跳转到.plt中的foo表项,.plt中的代码立即跳转到.got.plt中记录的地址。
现在执行jmp *(foo@GOT),跳转到.got.plt的foo@GOT的位置处。
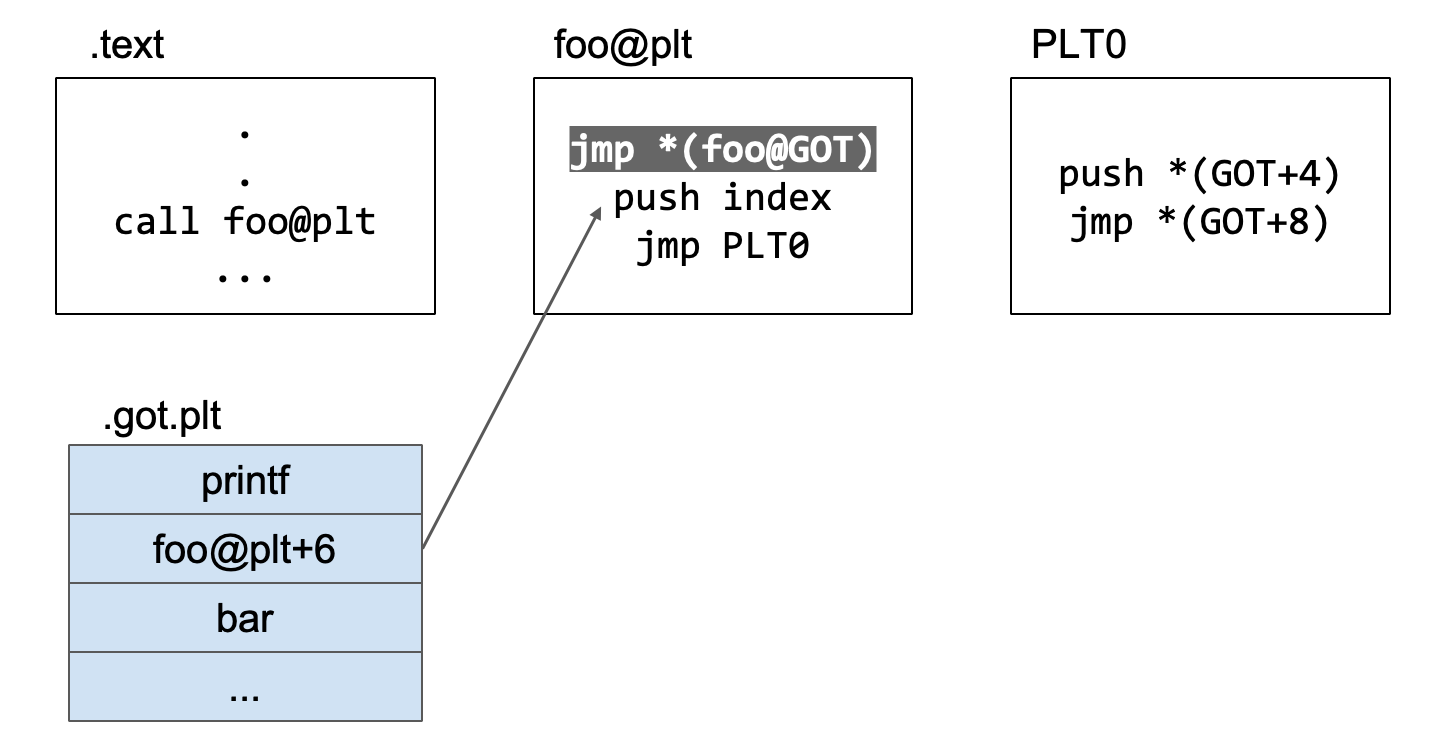
.got.plt中记录的地址
但是foo@GOT里面的内容是foo@plt+6,这个是plt表项下面的代码,又跳回到了plt,并且是跳到了jmp的下面的一行代码。
这里解释一下foo@plt+6,这里的6是6个字节,因为jmp *(foo@GOT)刚好是6个字节,所以说plt+6刚好是跳过了jmp指令了,直接执行push index。
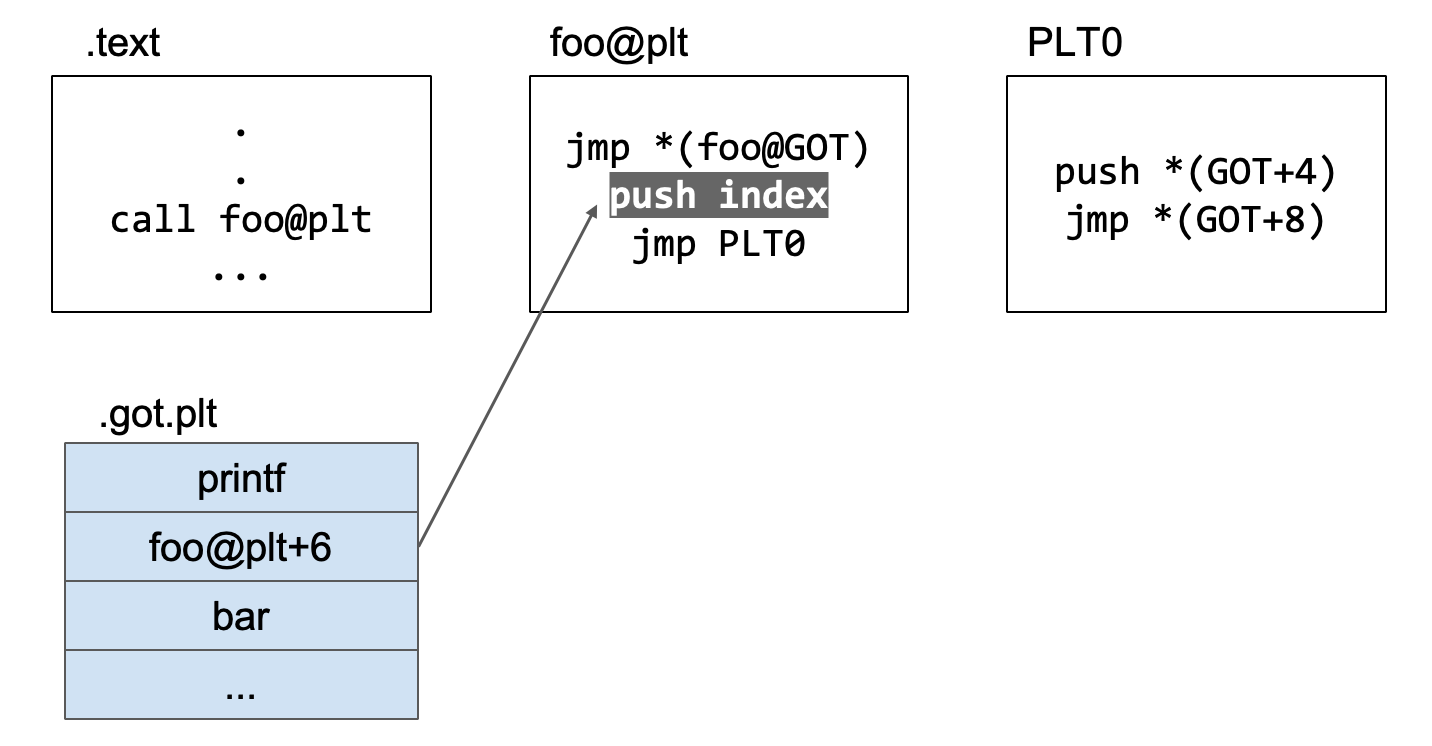
回到.plt,解析foo的实际地址
接下来就是连续要执行的4个汇编代码
1 | push index |
首先是push index,这里的index指的是调用的第index个外部函数,比如小结的开头,我们演示的图片中是调用了foo函数,foo函数在plt中对应调用的函数是第4个,那么index就是0x4。
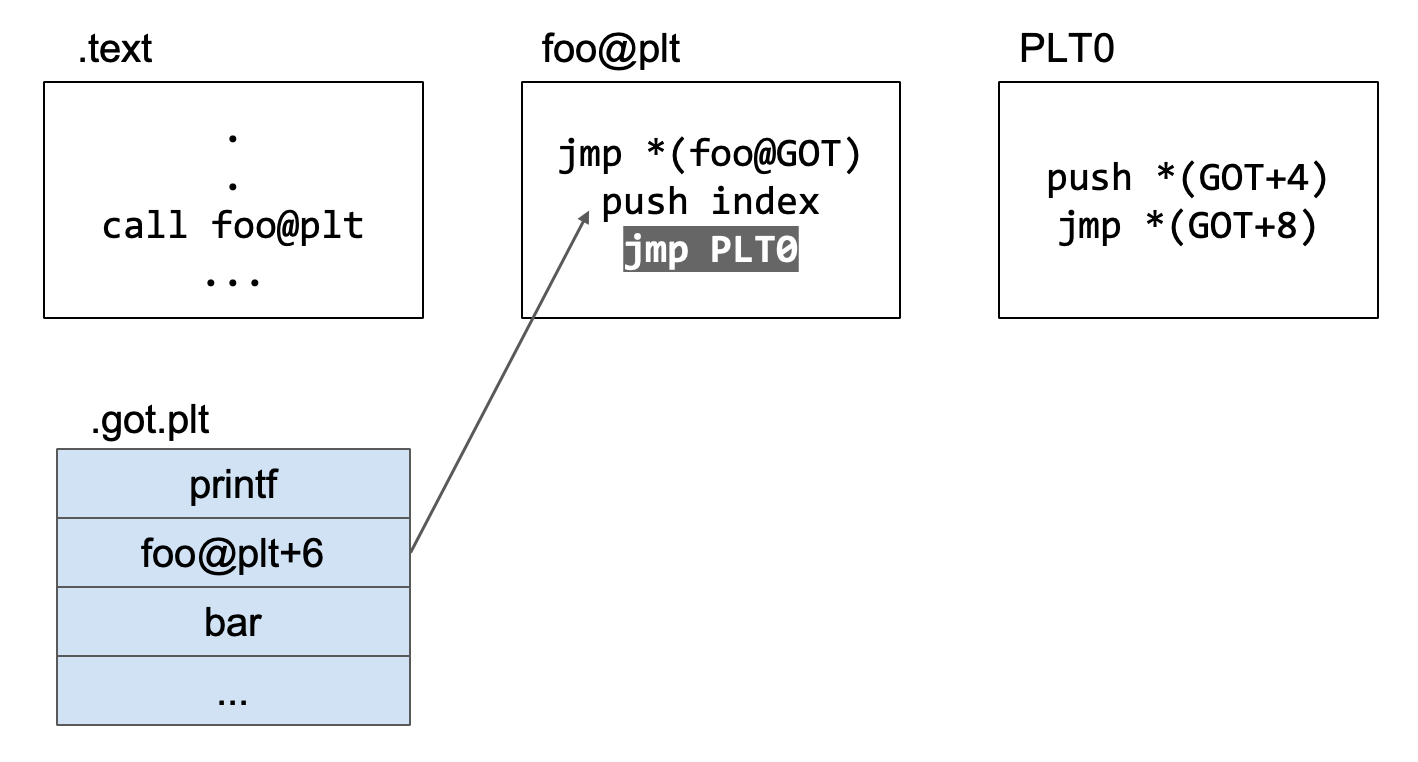
再执行jmp PLT0跳转到PLT0。
开始执行push *(GOT+4)。前面说过,一个可执行文件可能会引用不止一个动态链接库,这个汇编代码的作用就是去定位动态链接库,去哪一个动态链接库中去找我们调用的foo函数。
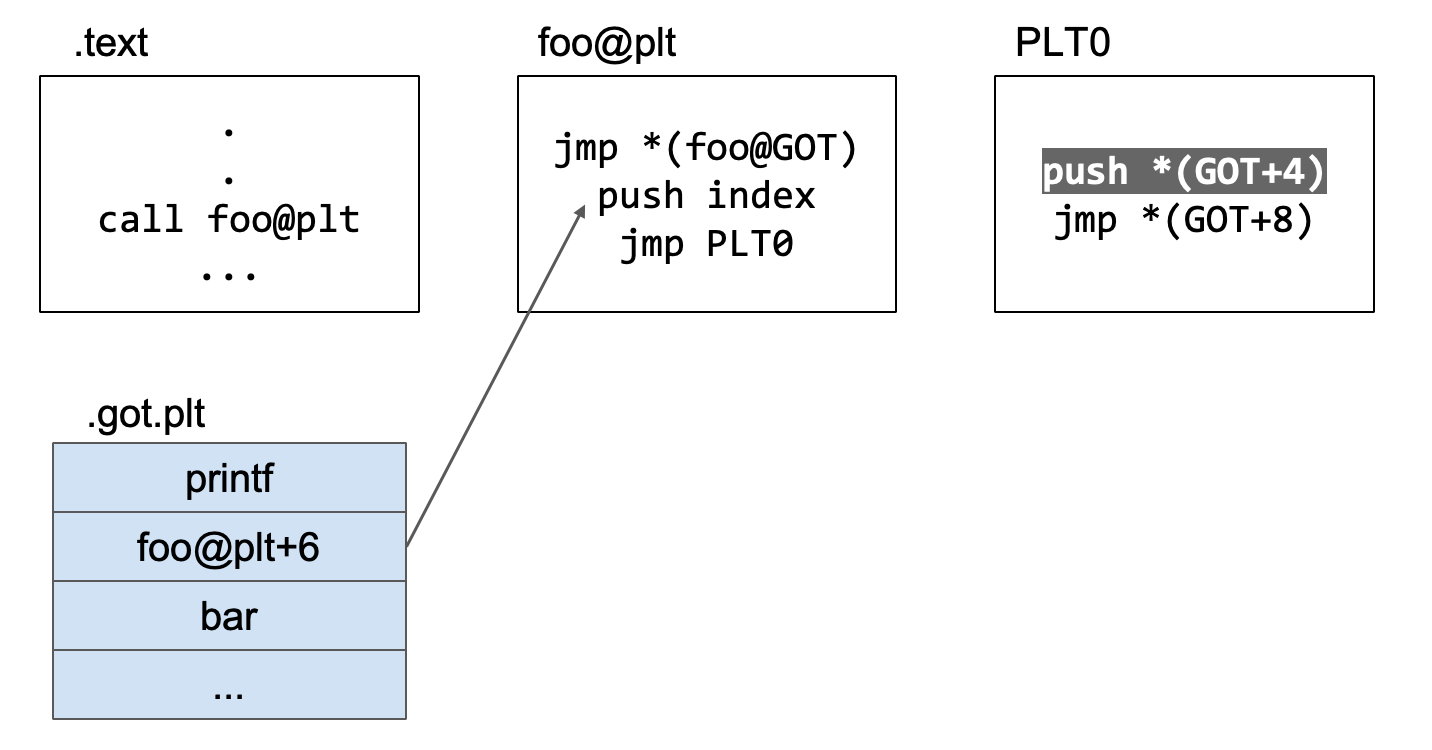
再执行jmp *(GOT+8)代码。前面已经执行了push index和push *(GOT+4),这两个是为后续解析foo函数真实地址函数提供的参数,接下来就是跳转到解析函数真实地址的函数的位置,即执行jmp *(GOT+8)。
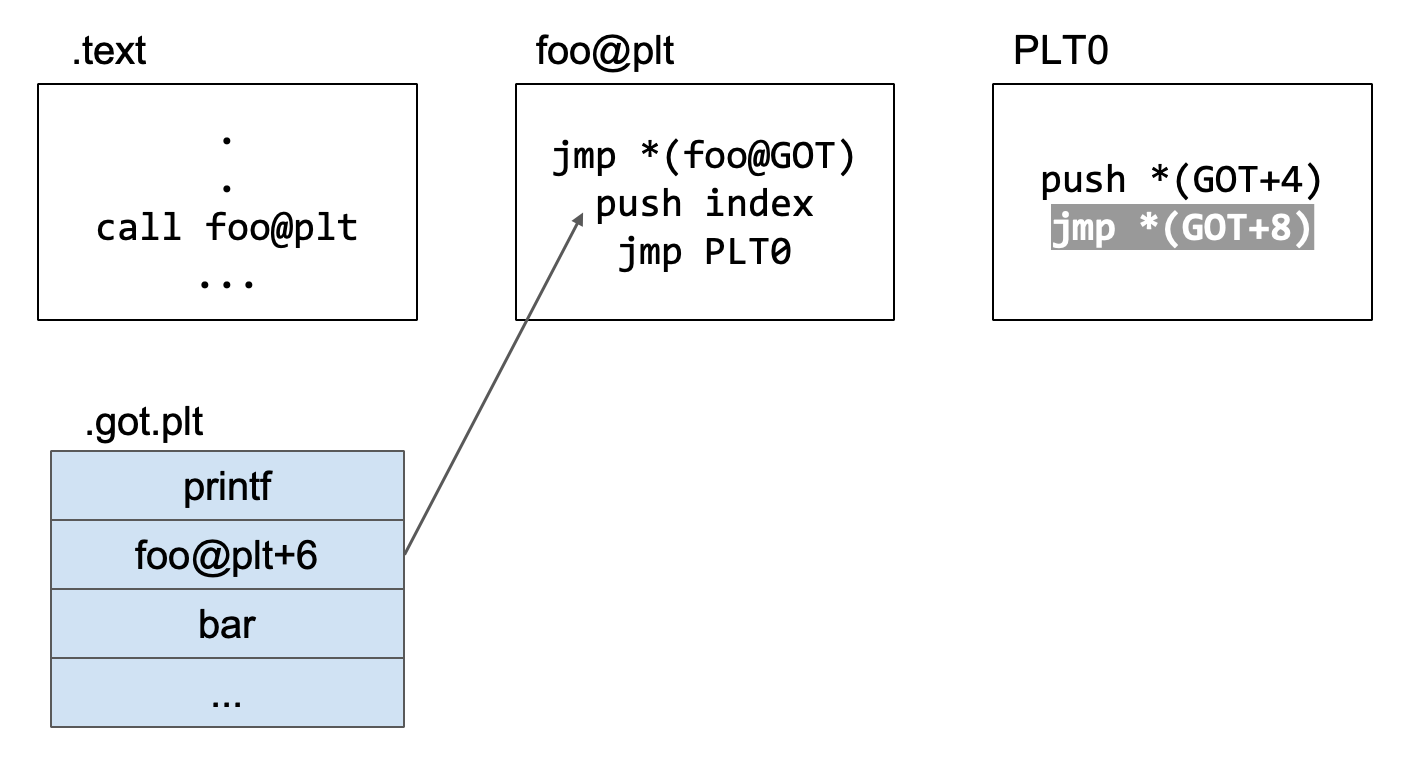
解析foo的真正地址填入.got.plt中
这个解析foo函数真实地址的函数是__dl_runtime_resolve,__dl_runtime_resolve函数解析出foo函数的真正地址,填入到.got.plt中。
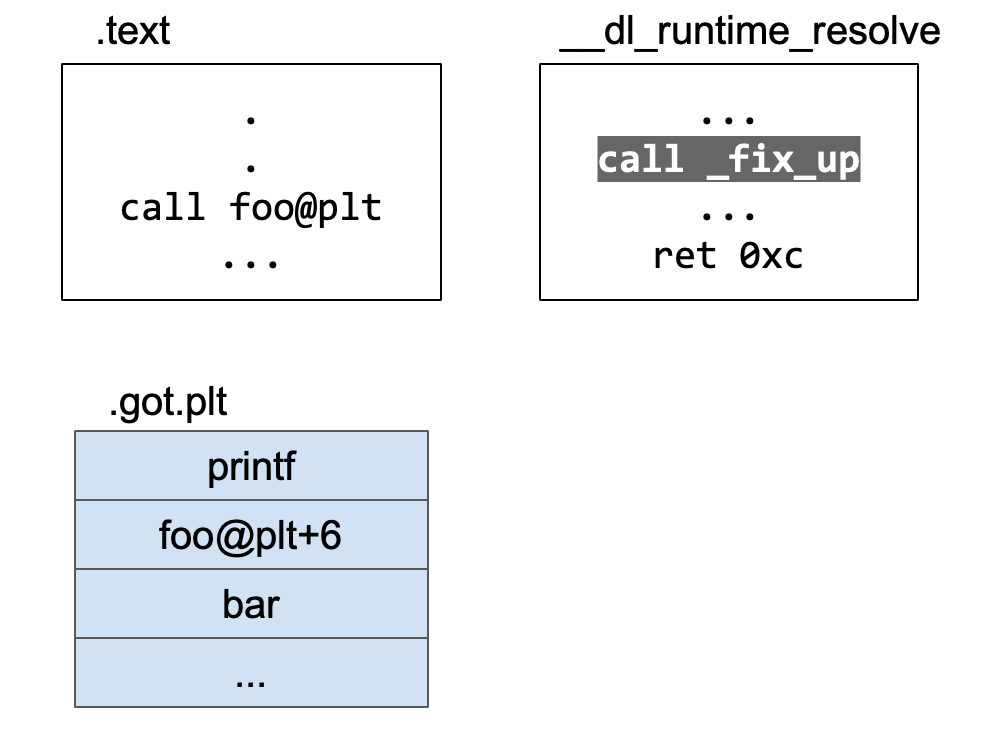
此后 .got.plt 中保存的是 foo 的真实地址
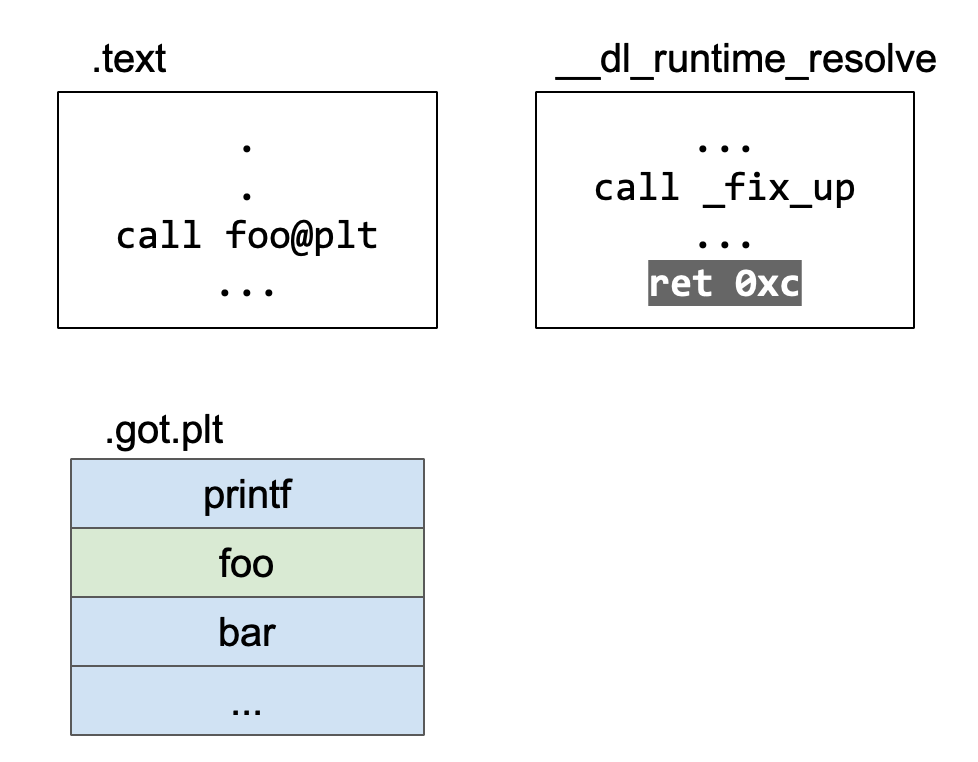
第二次调用foo
call foo@plt到plt然后直接跳转到.got.plt中存放foo函数真实地址的地方。
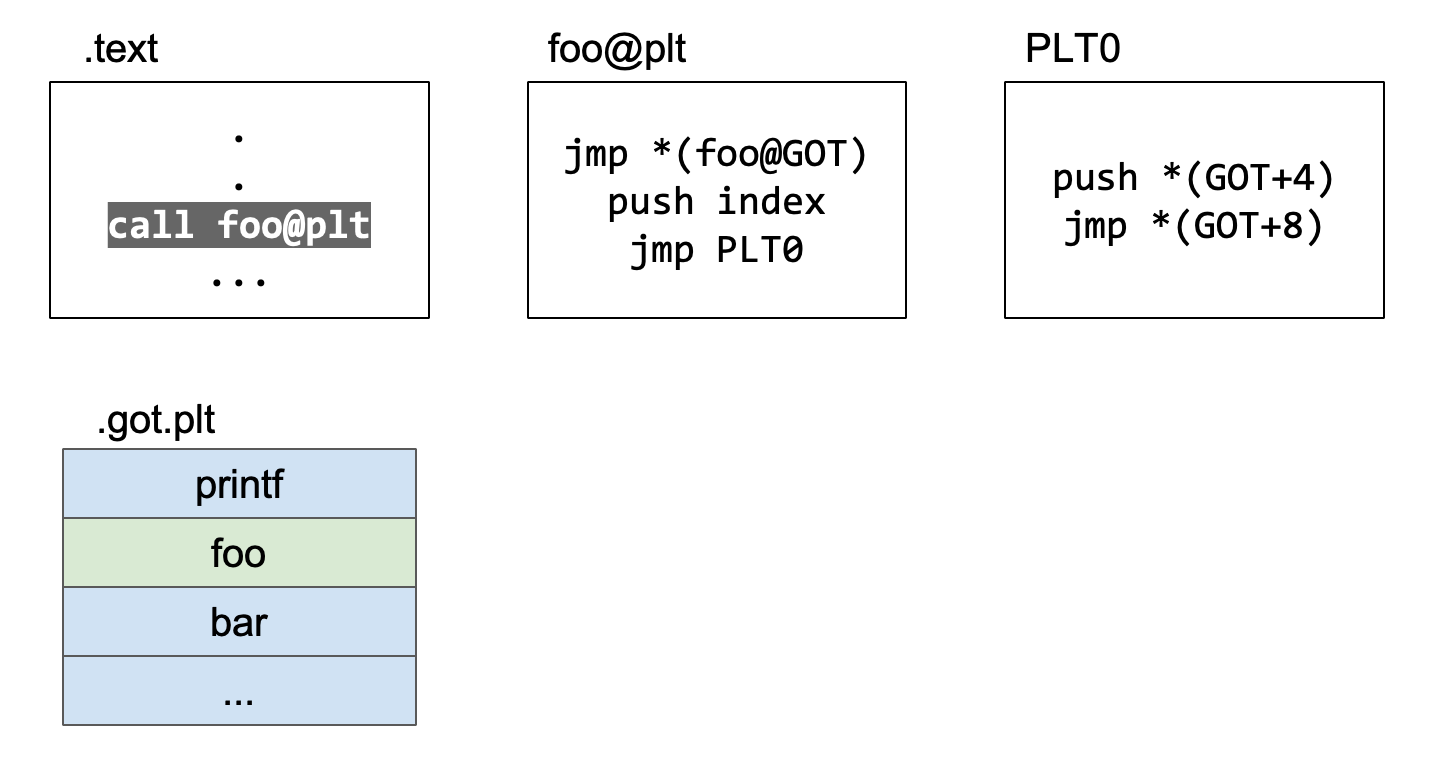
直接自.got.plt跳转到foo的真实地址,没有了第一次的解析地址过程。
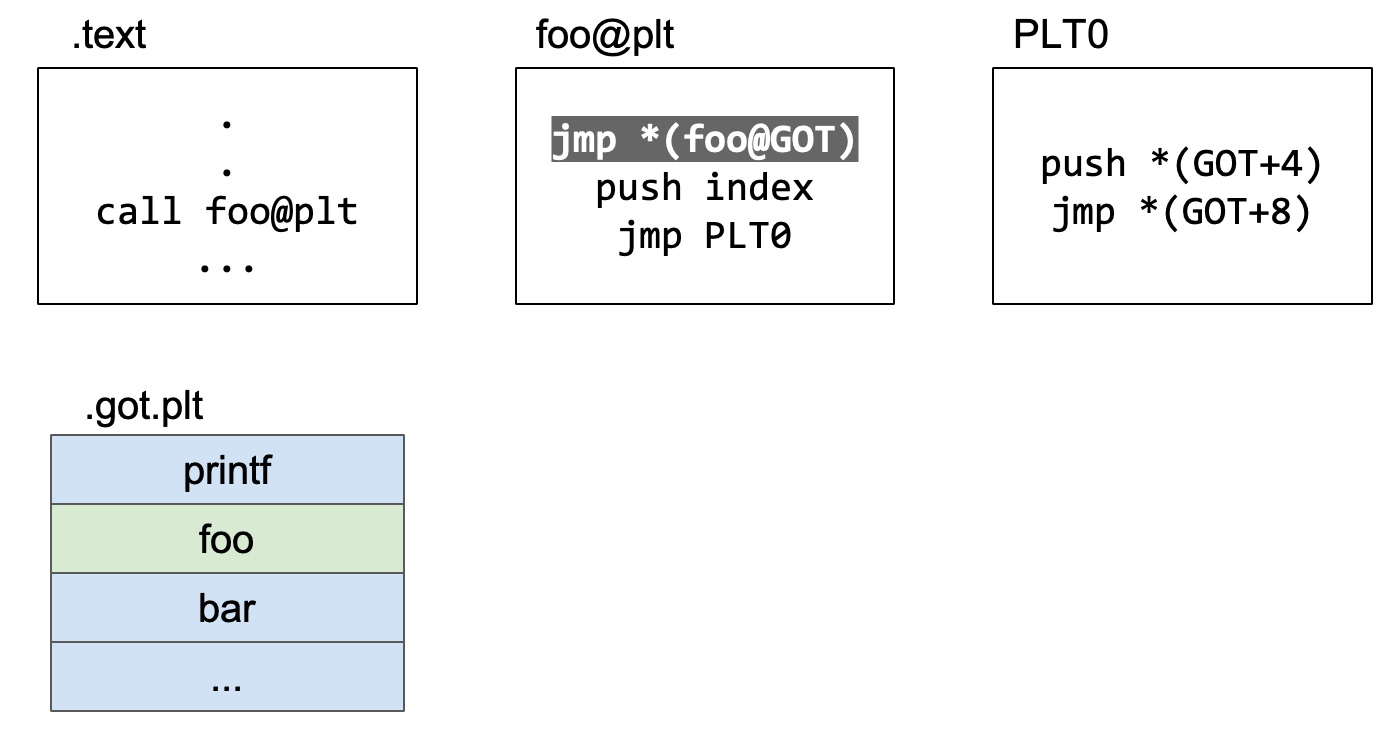
整个完整流程总结
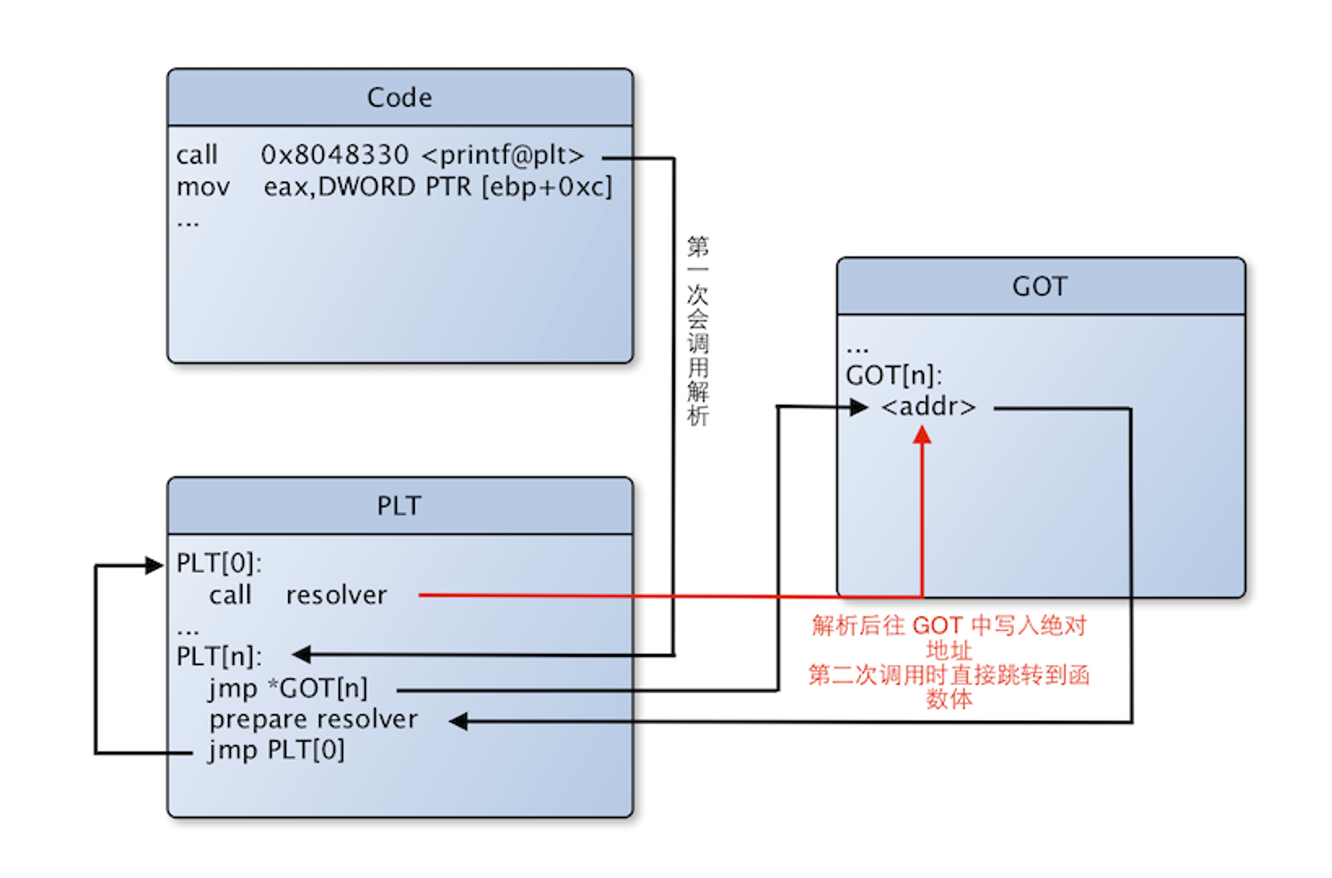
真实代码演示动态链接的过程
测试的dylink.c代码:
1 |
|
使用以下命令编译成可执行文件。
1 | gcc -no-pie -fno-pie -g -Wl,-z,lazy -Wl,--no-as-needed -fcf-protection=none -o link dylink.c |
上面命令执行的参数的意义:
-
固定地址(非 PIE),容易调试和做漏洞利用。
-
含调试信息(
-g)。 -
启用延迟绑定(PLT/GOT 可观察和利用)。
-
保留所有链接库(即使没用到)。
-
禁用 CET(Control-flow Enforcement Technology)(没有
endbr64,PLT 恢复成传统样子)。
可执行文件中的plt和got
使用gdb对编译的可执行文件进行查看,查看plt和got中的内容:
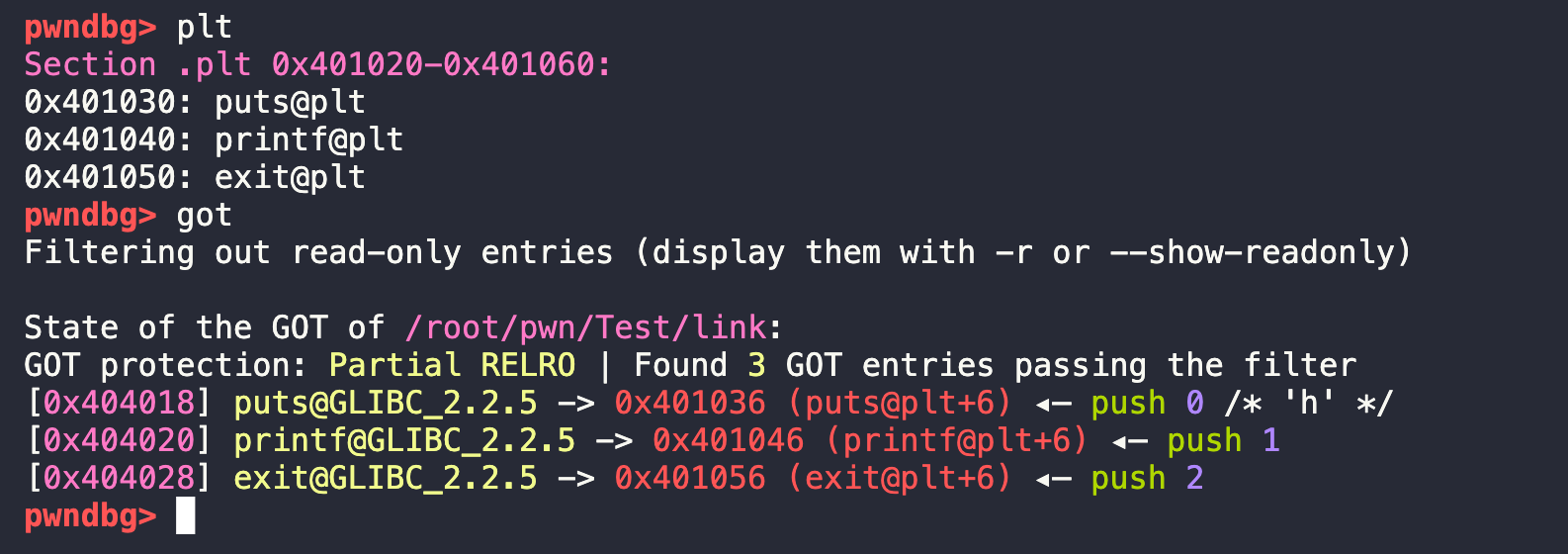
再详细查看plt,x 0x401030查看0x401030中的内容,x/20查看20个,每行是16个字节,刚好16个字节就是一个函数的plt表项目、

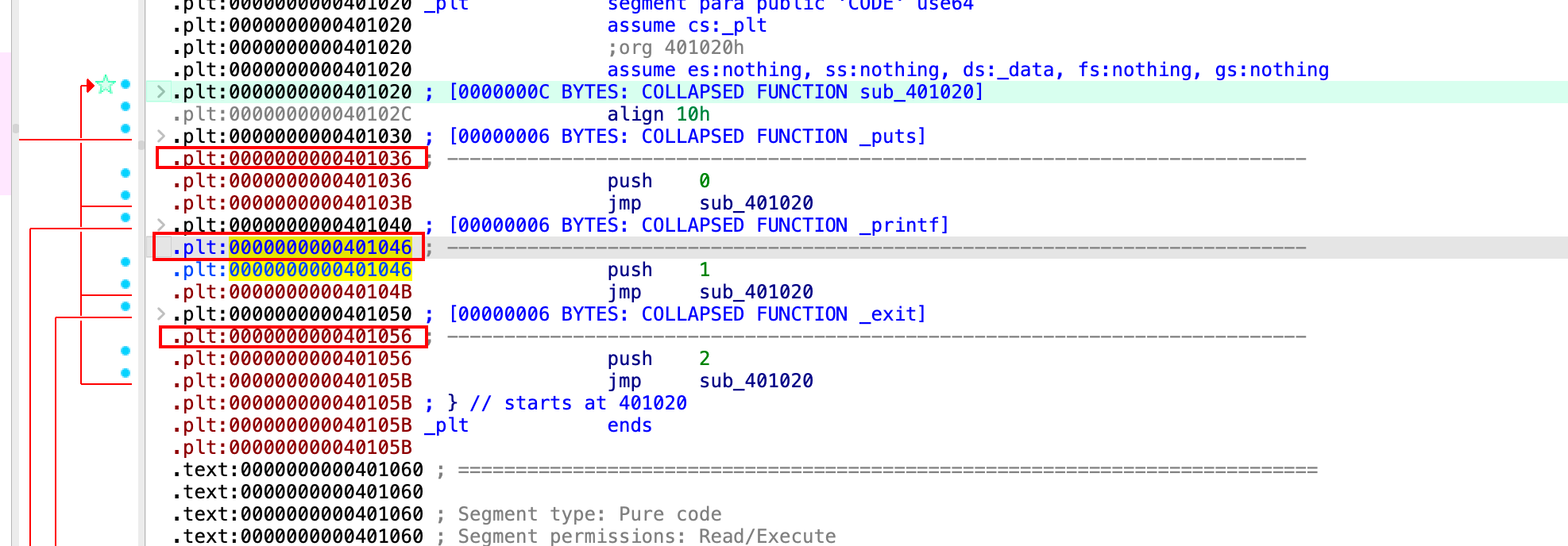
使用IDA pro查看link可执行文件,和gdb中的一样,一个表项16个字节,0x10 = 0x401056 - 0x401046。这个内容是属于代码段。
这里就对应了我们前面说到的汇编代码:
1 | push index |
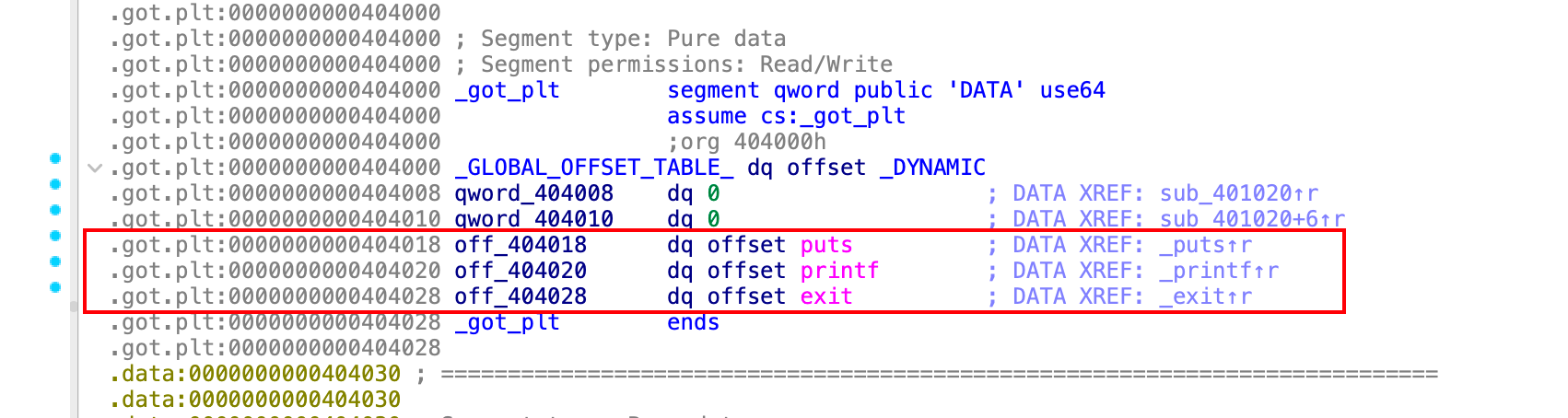
下面这个是数据段的.got中的.got.plt,其中对应了调用的三个函数puts、printf和exit。
在.got表项中是一个数组,从图中地址可以看出,每个函数占用的字节是8字节。我们这里是64位的地址,所以需要8字节来表示地址,8*8=64位刚好。所以,这里的每个表项的实际内容,就是函数在动态链接库中的真实地址。
gdb动态调试查看.got.plt的变化
调试可执行文件
1 | gdb link |
此时还没执行到puts函数,所以和前面说的一样.got.plt中是plt+6还没有真实的地址,要看第一次调用puts,把真实的地址修正,写入到.got.plt对应的puts函数的位置。
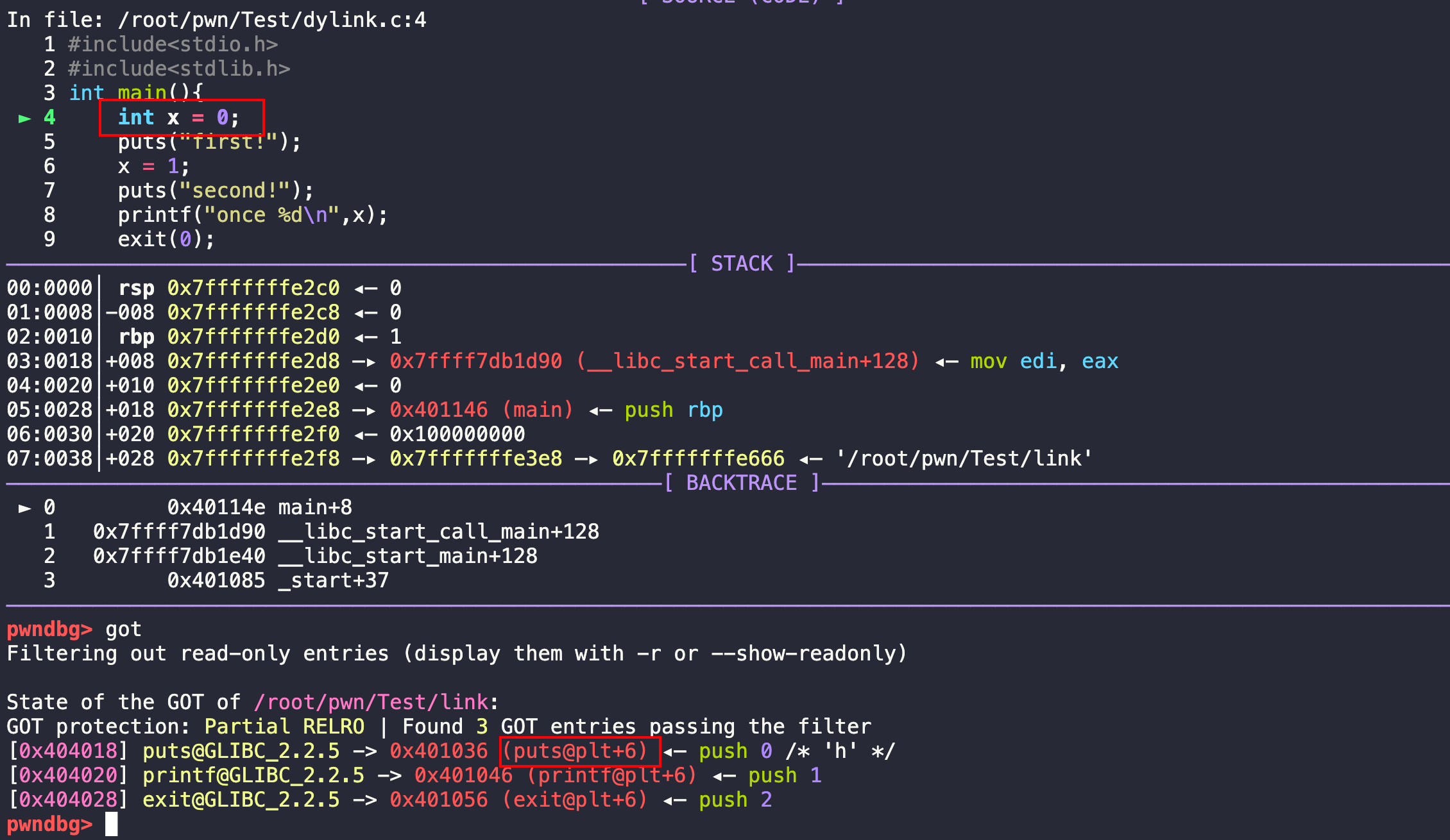
n,执行下一步。执行完puts以后,成功把动态链接库中的puts的真实地址写入到了.got.plt中puts函数对应的表项。后续调用就直接走.got.plt中的真实地址。
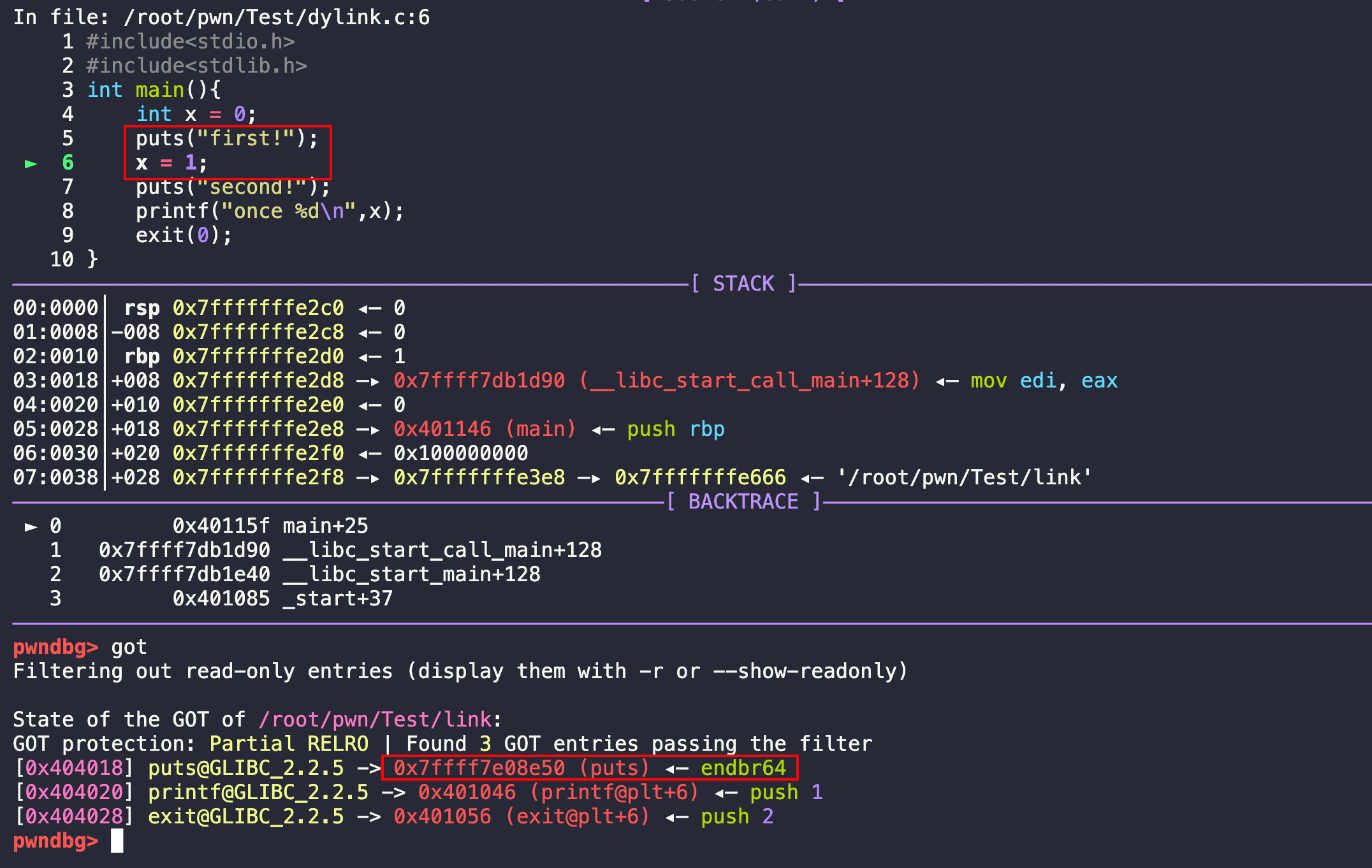
那么我们查看一下这个真实地址,x/20x 0x7ffff7e08e50,然后也可以看一看汇编代码disass 0x7ffff7e08e50。
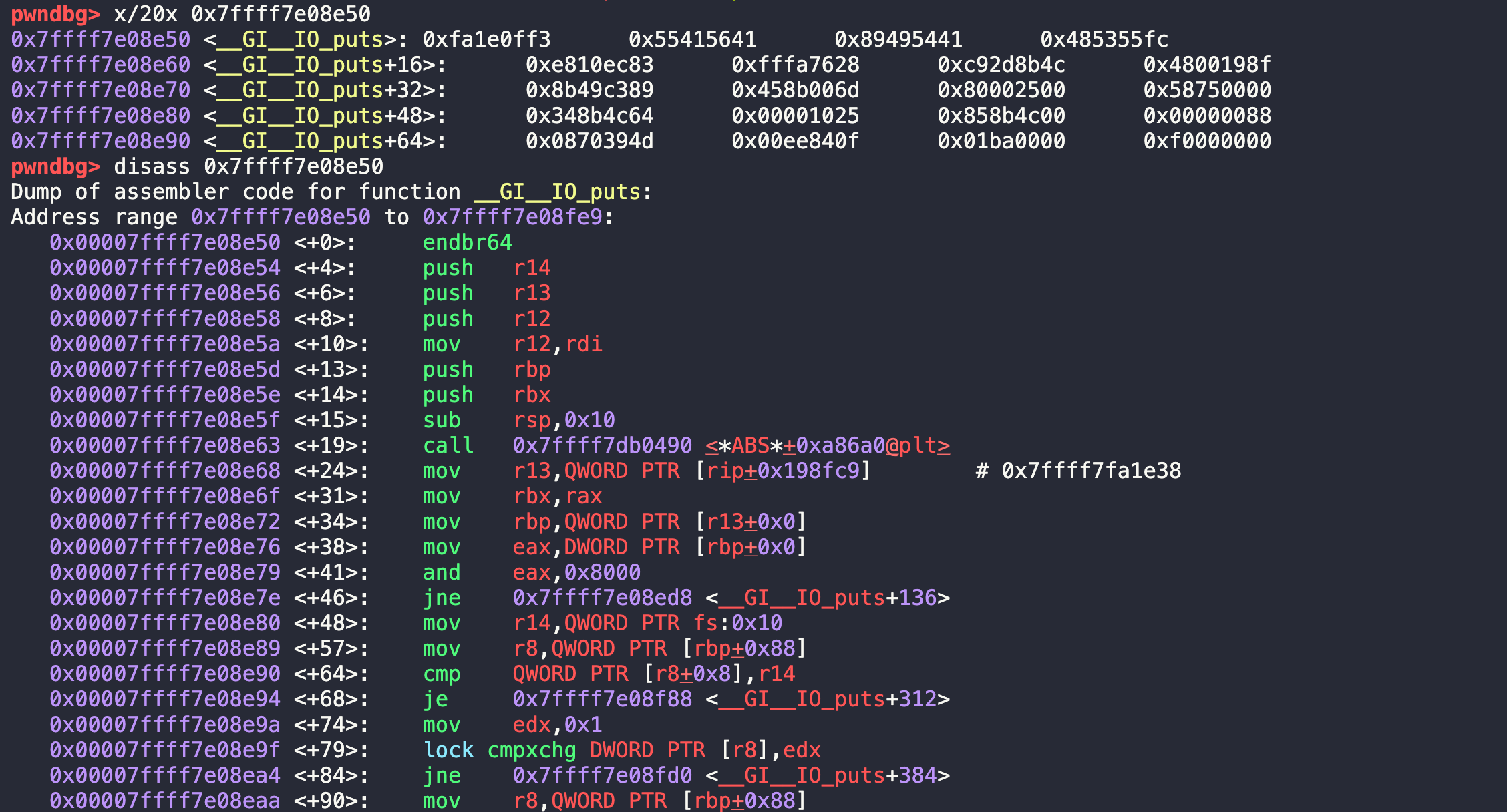
对于还没有写入真实地址的printf,我们也可以看其反汇编的代码disass 0x401046,就是前面IDA pro中的内容。

继续执行,执行完了第二个puts。
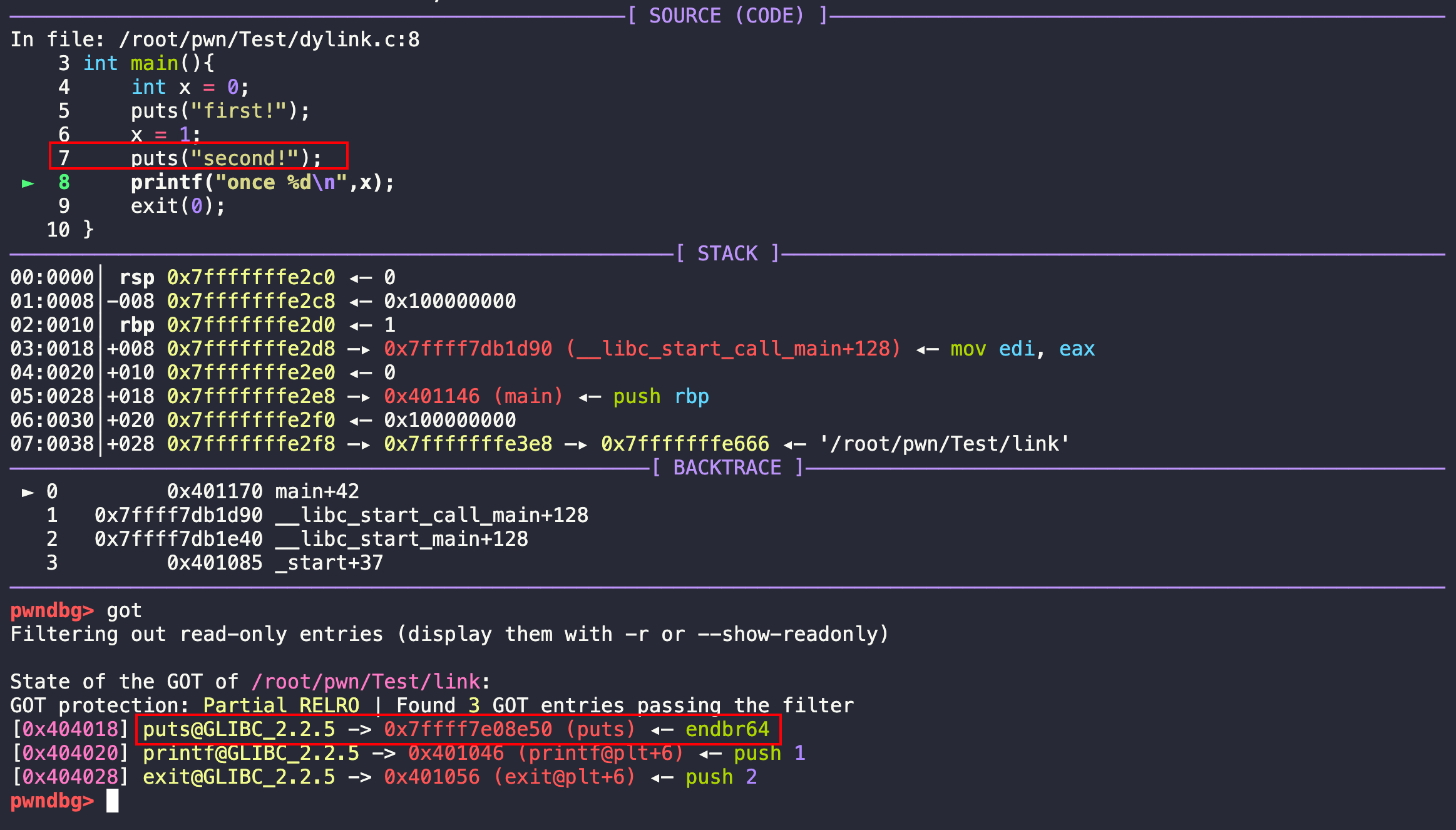
n,再继续执行。写入了printf的真实地址。
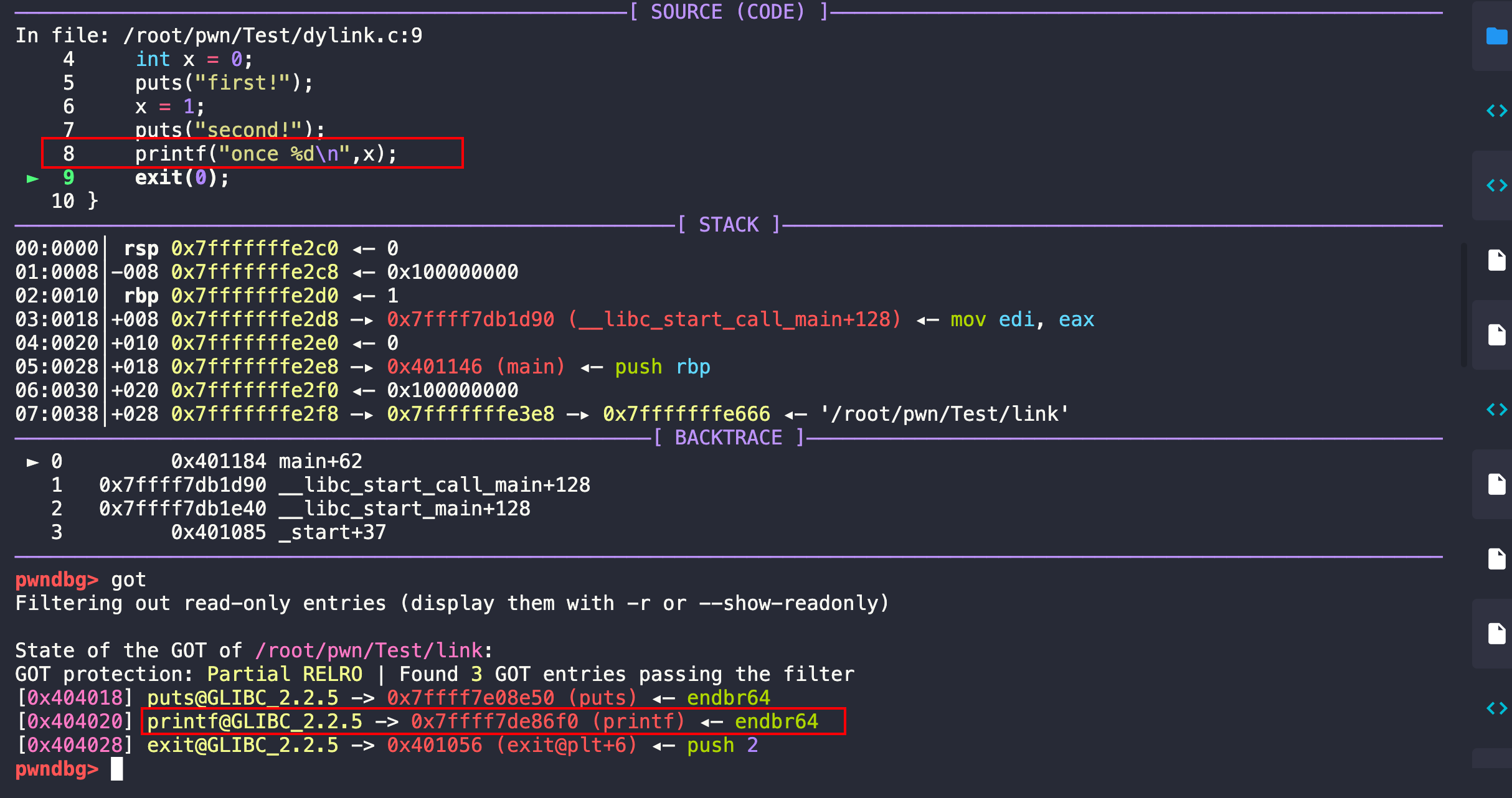
再n就执行到了exit(0),程序就结束了。