什么是堆(heap)?
从操作系统和虚拟内存管理的视角来看,堆是一个被动的内存资源。
定义与位置
- 物理形态:进程虚拟地址空间 (Virtual Address Space) 中的一个特定段 (Segment)。
- 内存布局: 通常位于 Data Segment (.bss) 的末端之后,Stack Segment 之前(低地址在前,高地址在后)。
- 生长方向: 向上生长 (Upward Growth),即从低地址向高地址扩展。
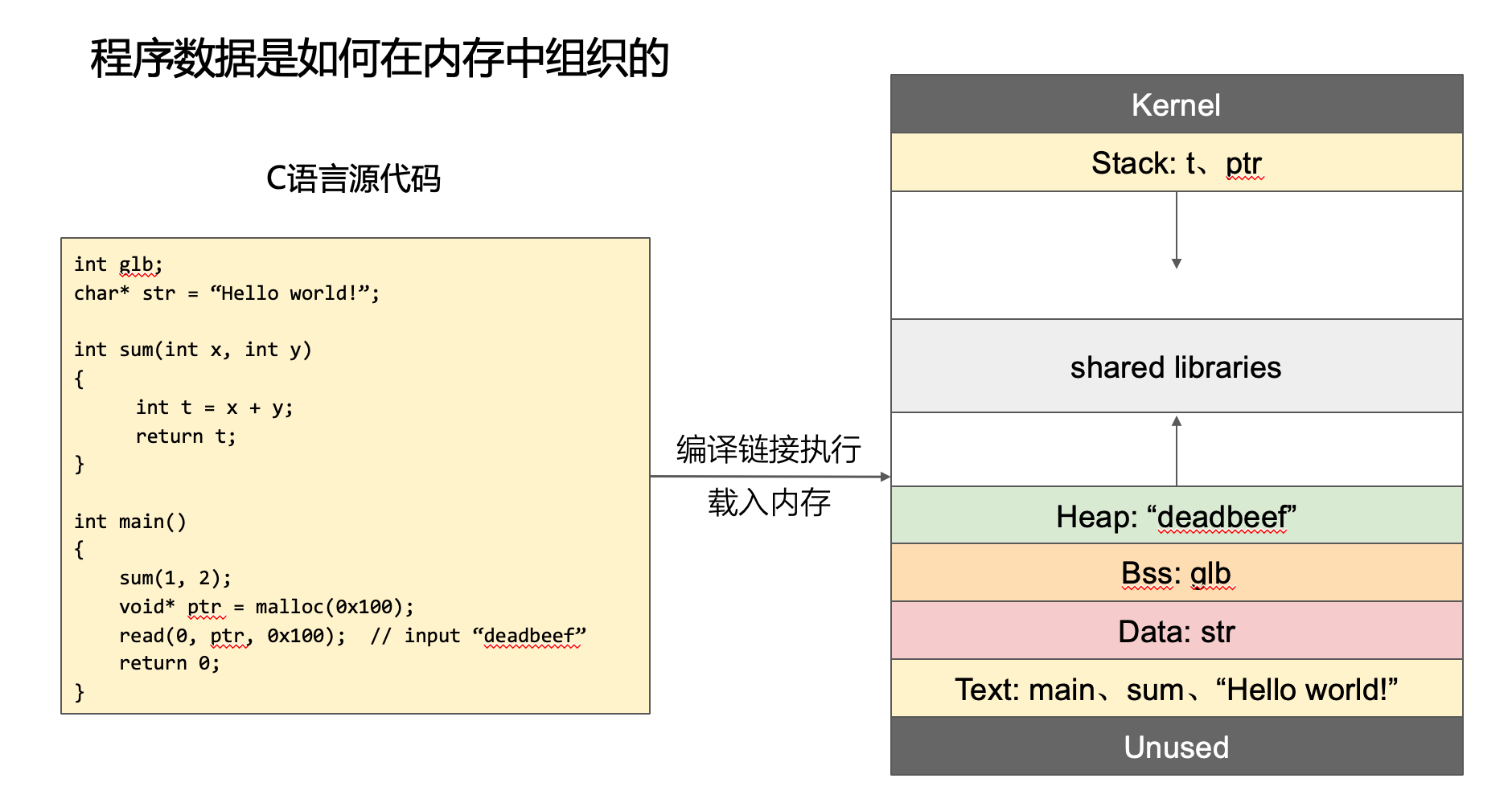
边界控制
堆的大小并非固定,而是由内核维护的边界指针控制:
- Program Break (
brk): 定义了堆段的当前顶部(End of Heap)。 - 扩展机制: 进程通过
brk()或sbrk()系统调用提升 Program Break 的位置,从而向内核申请更多的物理页映射到该虚拟地址范围。 - Mmap 区域: 对于超大块内存(大于阈值
M_MMAP_THRESHOLD),通常不使用brk扩展的主堆,而是使用mmap()在堆栈中间的文件映射区分配独立段。
什么是堆管理器(The Heap Manager)?
堆管理器是一个主动的软件算法,属于用户态运行时库(User-space Runtime Library,如 Linux 下的 glibc ptmalloc)的一部分。
各种堆管理器:
-
dlmalloc:General purpose allocator
-
ptmalloc2:glibc
-
jemalloc:free BSD and Firefox
-
tcmalloc:Google
-
libumem:Solaris
核心职责
它是应用程序与操作系统内核之间的中间层 (Abstraction Layer)。
- 对下 (Kernel): 通过
brk/mmap系统调用,以“页 (Page, 4KB)”为单位向内核批发大块内存。 - 对上 (Application): 提供
malloc/free标准接口,实现“任意字节大小”的精细化分配与回收。
内部数据结构 (以 glibc 为例)
堆管理器不视内存为连续的字节流,而是将其格式化为特定的数据结构:
- Chunk (堆块): 内存管理的最小单元。
- 包含 Metadata (元数据):
size,prev_size,flags (AMP),fd/bk指针。 - 包含 User Data (用户数据):
malloc返回的实际载荷。
- 包含 Metadata (元数据):
- Bins (空闲链表): 用于索引 Free Chunks 的指针数组(Fastbin, Smallbin, Largebin, Unsorted Bin)。
- Arena (分配区): 用于多线程并发控制的独立内存池,每个 Arena 维护自己的一套 Bins 和 Top Chunk。
交互流程
1、初始化: 程序启动,堆管理器初始化数据结构(Arena/Bins)。
2、申请 (Malloc):
- 用户请求
malloc(size)。 - 堆管理器 检索 Bins 寻找合适的 Free Chunk。
- 若无,堆管理器 切割 Top Chunk。
- 若 Top Chunk 不足,堆管理器 调用系统调用 (
sbrk) 扩展 堆 的边界。
3、释放 (Free):
- 用户请求
free(ptr)。 - 堆管理器 并不立即将内存归还给操作系统(不缩小 堆 的
brk)。 - 堆管理器 将该 Chunk 标记为空闲,合并相邻空闲块,并将其挂入 Bins,留作后用(缓存复用)。
Allocated Chunk和Free Chunk
在 Glibc 的内存分配器(ptmalloc)中,内存并非是一块平坦的画布,而是由无数个被称为 Chunk (堆块) 的微小单元拼接而成的。
理解 Chunk 结构的核心挑战在于:复用 (Reuse)。为了节省内存,同一个内存偏移位置,在“使用中”和“空闲中”代表着完全不同的含义。
Allocated Chunk(已分配堆块)
当用户调用 malloc 拿到一个指针时,他在内存中实际拥有的是一个 Allocated Chunk。
设计思想
- 用户视角:只关心存储数据的区域。
- 管理器视角:只需要知道这个块多大(Size),以及前一个块是否在使用(以便决定未来释放时是否合并)。
- 空间优化:如果前一个块也在使用中,当前块的
prev_size空间是闲置的。ptmalloc 允许前一个块借用这 8 字节来存它的用户数据。
内存结构图解
1 | [ 内存低地址 ] |
字段解释
“含Header“,是说size的大小,包括用户申请的内存+Header头(8字节size和8字节prev_size),这才是真正的size的大小。
-
Offset 0x00 (
prev_size): 仅当前一个块是 Free 状态时,这里才记录前一个块的大小。否则,这里存的是前一个块的数据。 -
Offset 0x08 (
size): 当前块的大小。低 3 位被留作标志位。 -
Offset 0x10 (
User Data): 用户指针指向这里。
Free Chunk(空闲堆块)
当 chunk 被释放 (free) 后,它失去了存储用户数据的义务。原本用于存数据的地方,现在被堆管理器征用,用来存储链表指针,以便将这个空闲块串起来。
根据所属 Bin(垃圾回收桶)的不同,Free Chunk 的结构有明显的变体。
标准Free Chunk(Small / Unsorted Bin)
这是最标准的空闲块结构,使用双向链表维护。
1 | [ 内存高地址 ] |
Fastbin / Tcache Chunk (小块特例)
为了极致的性能,Fastbin 和 Tcache 采用单向链表。它们不需要 bk 指针。
1 | [ 内存高地址 ] |
Large Bin Chunk(大块堆)
Large Bin 存储较大的块,且同一 Bin 内的块大小不一。为了提高检索效率(Best-fit 算法),除了标准的 fd/bk 双向链表外,还额外增加了 fd_nextsize/bk_nextsize 指针,形成第二层跳表。
1 | [ 内存高地址 ] |
核心标志位(Flag)详解
在所有 Chunk 的 size 字段(Offset +0x08)中,由于对齐原因,最低的 3 个比特位 (Bits 0-2) 永远不会被用到大小计算中。glibc 利用它们存储当前 Chunk 的属性。
| 掩码 (Mask) | 标志 (Flag) | 全称 | 详细状态定义 |
|---|---|---|---|
| 0x1(001) | P | PREV_INUSE | 最重要的标志位。 ● 1 (Set): 表示物理相邻的前一个 Chunk 正在使用中 (Allocated)。此时当前块的 prev_size 字段无效(可能存着前一个块的数据)。● 0 (Cleared): 表示物理相邻的前一个 Chunk 是空闲的 (Free)。此时 prev_size 记录前块大小,Heap Manager 会利用它找到前块头部并进行合并。 |
| 0x2(010) | M | IS_MMAPPED | ● 1 (Set): 当前 Chunk 是通过 mmap() 系统调用直接分配的独立内存映射,不属于 Main Heap。 ● 0 (Cleared): 当前 Chunk 属于常规 Heap (通过 brk 扩展)。 |
| 0x4(100) | A | NON_MAIN_ARENA | ● 1 (Set): 当前 Chunk 属于子线程的分配区 (Thread Arena)。 ● 0 (Cleared): 当前 Chunk 属于主分配区 (Main Arena)。 |
Allocated与Free的视图切换
对于同一个内存地址 0x55555555a010 (即 Header 之后的第一个字):
- 当 Chunk Allocated 时:
- 这里是
User Data(buf[0]…buf[7])。 - 权限: 用户可读写。
- 这里是
- 当 Chunk Free (Small Bin) 时:
- 这里是
fd指针。 - 权限: 堆管理器读写,用户(理论上)不可访问。
- 这里是
- 当 Chunk Free (Large Bin) 时:
- 这里是
fd指针,且+0x10处变成了fd_nextsize。
- 这里是
同一块内存在不同生命周期扮演不同角色。
GDB调试查看
以最简单的c语言程序展示堆:
1 |
|
编译后,使用gdb调试查看。
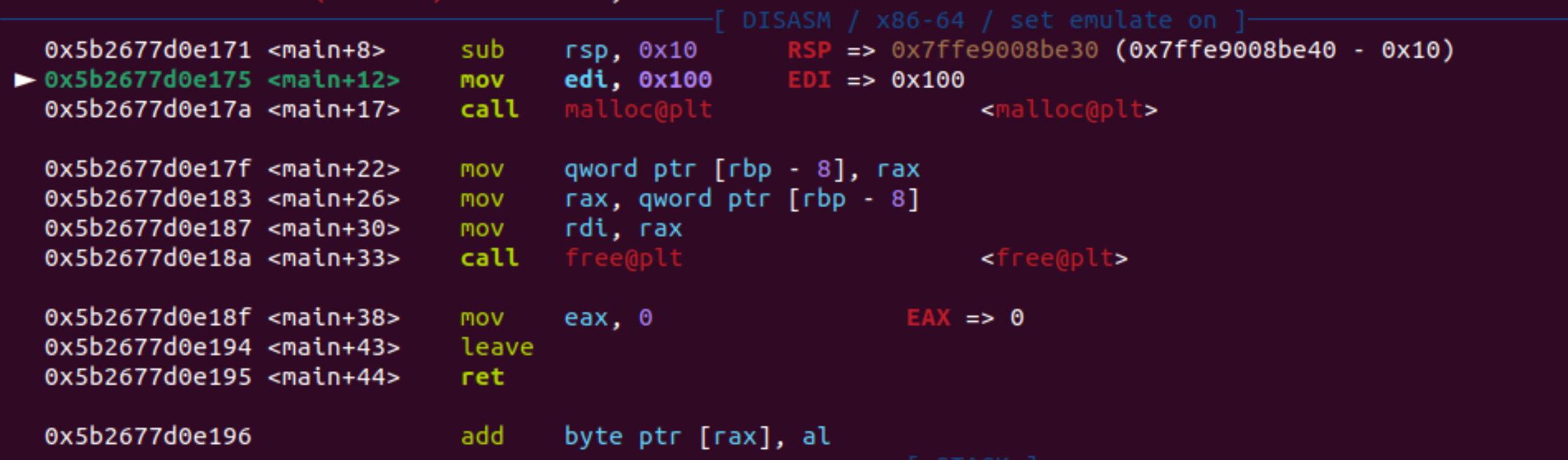
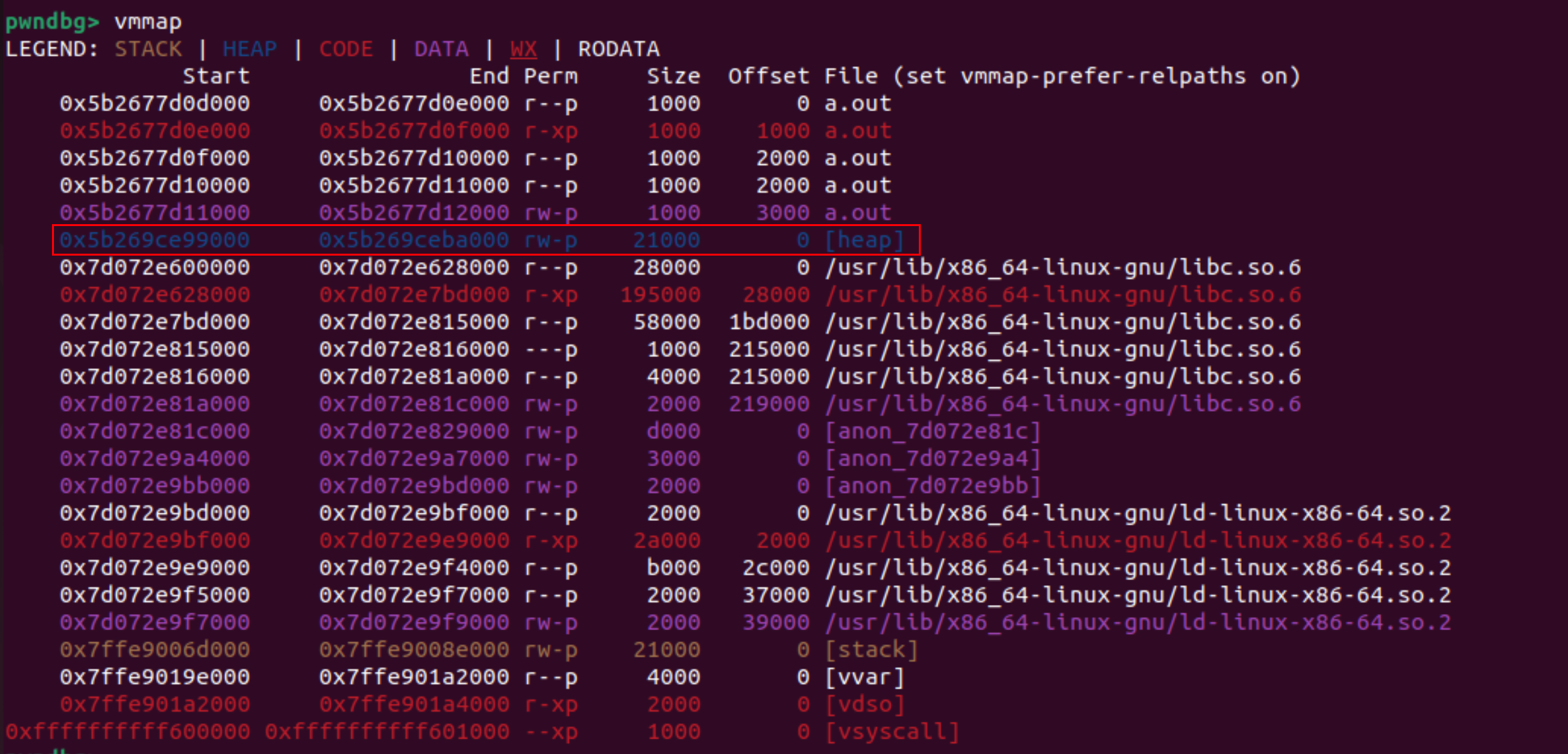
在未进行执行malloc()的时候查看进程的虚拟内存。此时,发现还没有heap数据。
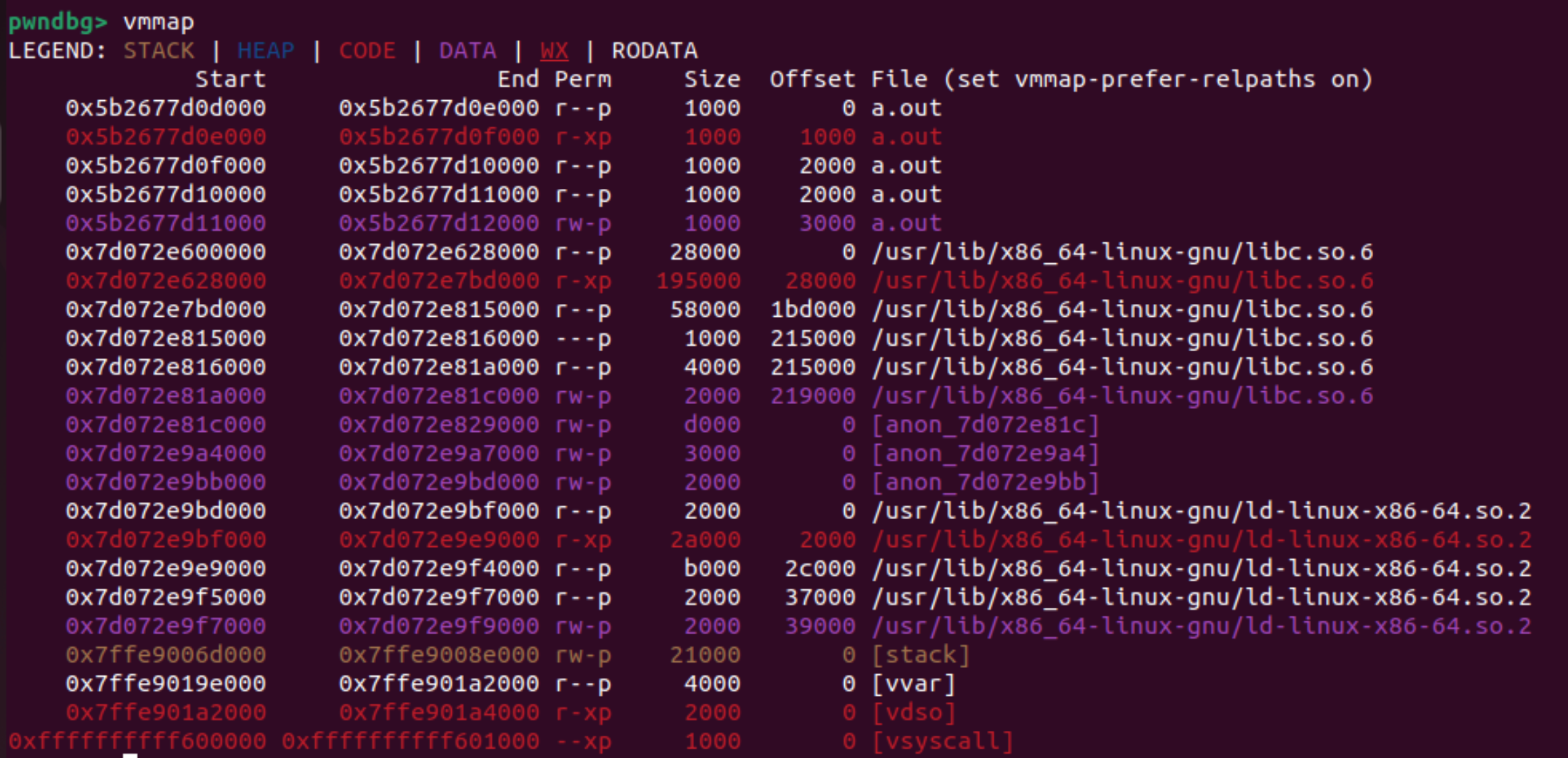
执行malloc()后。
发现存在了heap数据,heap位置占据的大小为0x21000。
 此时查看heap。
此时查看heap。
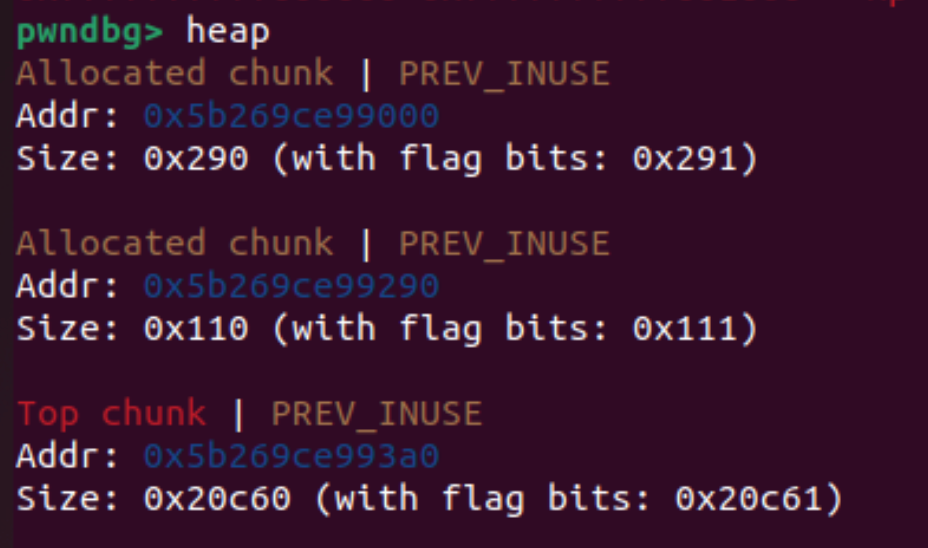
发现了有一个allocated chunk,带上flag大小为0x111。
**为什么是0x111?**回想前面C语言代码,malloc(0x100),用户申请了0x100大小的内存。又因为size的大小是包括prev_size和size的,这两个分别是8字节(64位),0x10字节。又因为size后三位是flag位,为001,0x1。
所以size的大小就是0x111。
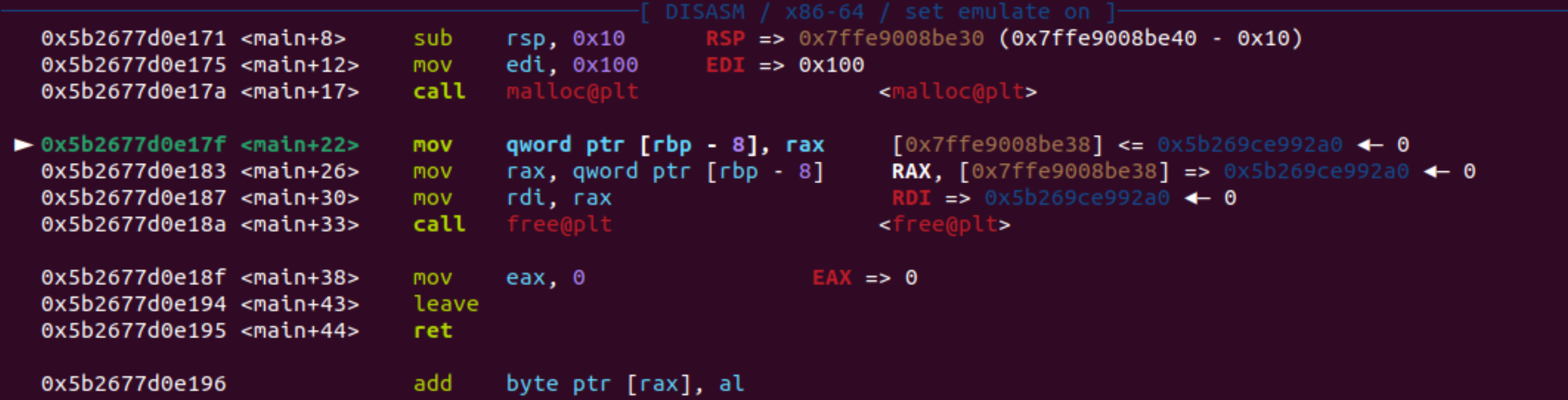
继续,上图还能看到chunk的起始地址Addr: 0x5b269ce99290
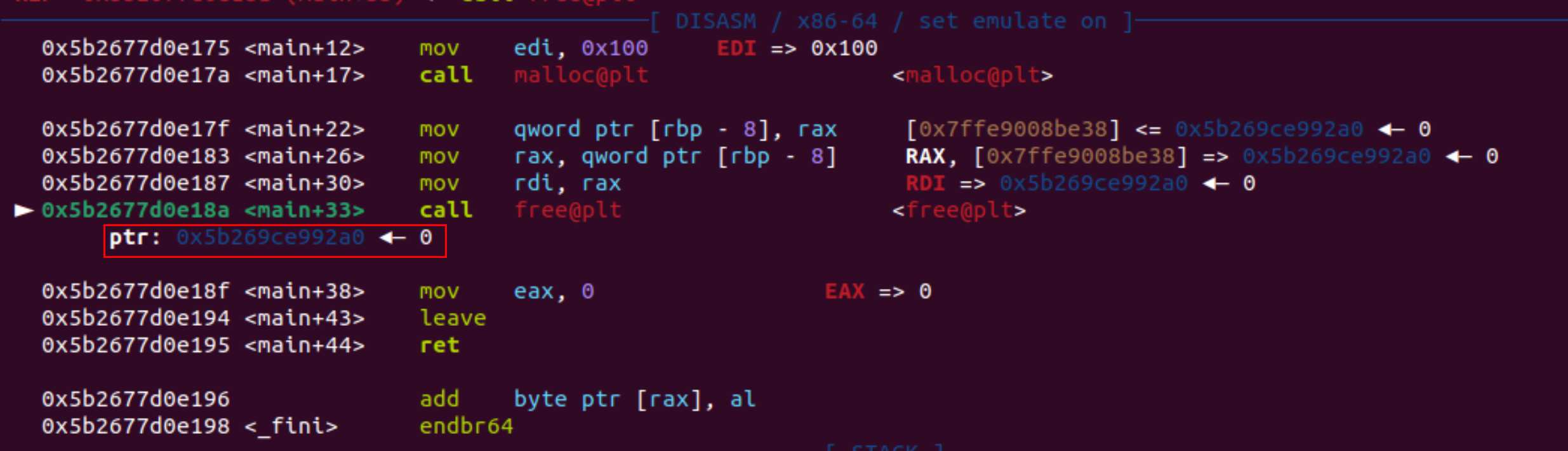
调试看到ptr变量指向的地址为0x5b269ce992a0,刚好差了0x10!!,16字节,这是为什么?
prev_size + size = 0x10字节
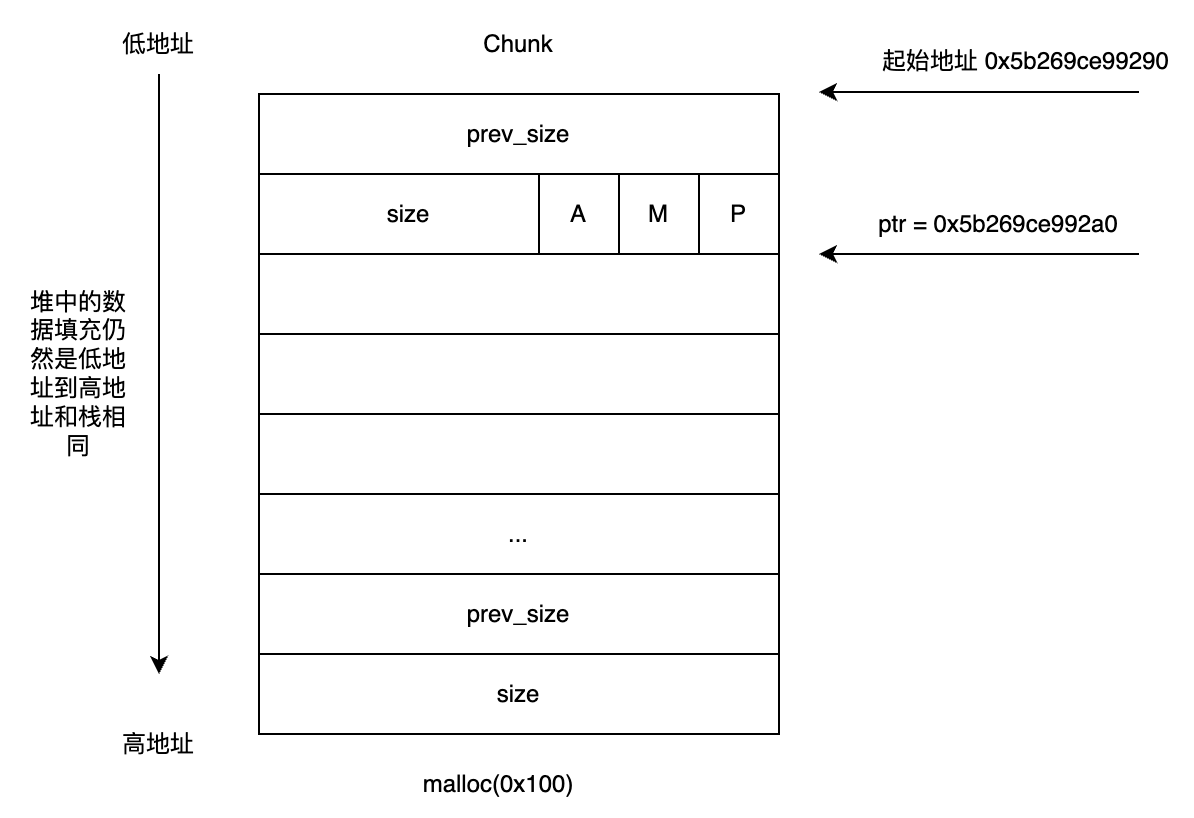
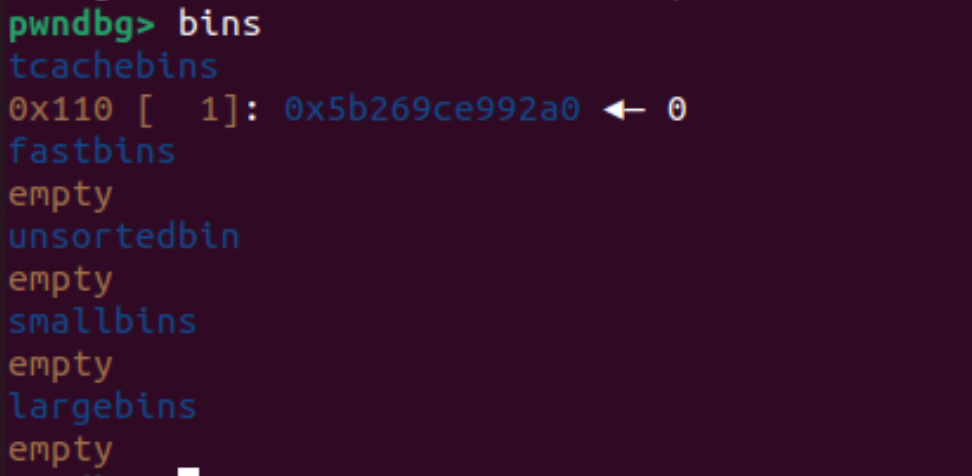
继续执行,过free()函数。
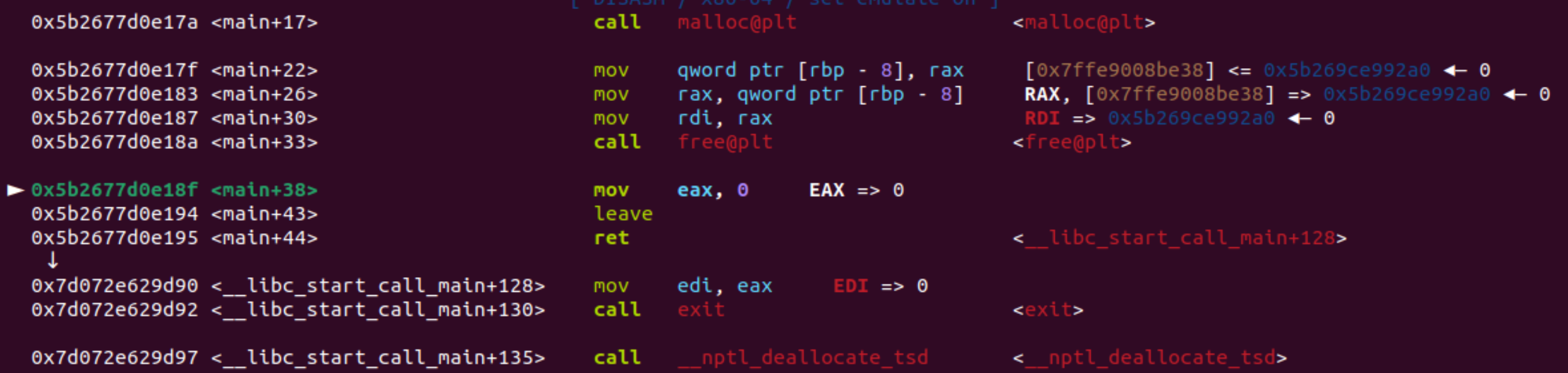
发现chunk被放到了tcachebins中。
什么是堆溢出?
堆溢出 (Heap Overflow) 是指程序向堆内存(Heap)中的缓冲区写入数据时,超出了该缓冲区原本申请的大小,导致数据覆盖了**相邻堆块(Chunk)**的内容。
与栈溢出(Stack Overflow)不同,堆溢出的破坏力不仅在于覆盖数据,更在于破坏了堆分配器(如 glibc 的 ptmalloc)维护的管理结构(Metadata)。
💡 核心逻辑: 在堆内存中,用户数据和管理数据是混在一起的。一旦溢出,攻击者就能通过篡改管理数据,欺骗分配器在进行
malloc或free操作时,执行攻击者预期的内存读写操作。
堆块(Chunk)的结构
在 Linux (glibc) 环境下,堆内存是以 Chunk 为单位进行管理的。理解 Chunk 的结构是利用漏洞的前提。
一个 allocated(已分配)或 free(空闲)的 chunk 在内存中的布局大致如下:
1 | struct malloc_chunk { |
-
prev_size: 如果物理相邻的前一个 chunk 是空闲的,这里记录它的大小(用于合并)。 -
size: 当前 chunk 的大小。因为堆块大小通常 8/16 字节对齐,低 3 位被用来存储状态标志(如PREV_INUSE表示前一个块是否在使用)。 -
fd/bk: 双向链表指针。只有当 Chunk 被释放(Free)后,这两个位置才会被填入数据,用于指向链表中的前后节点。
堆溢出漏洞的成因
堆溢出通常源于对用户输入长度的检查缺失。
例如代码:
1 | void vulnerable_function(char *input) { |
内存发生了什么?
当 input 长度过长时,数据会越过 chunk_A 的边界,直接覆盖 chunk_B 的头部(prev_size 和 size),甚至覆盖 chunk_B 的 fd/bk 指针。
利用原理:从覆盖到劫持(Exploitation)
攻击者的最终目标通常是实现 任意地址写 (Write-What-Where Primitive)。
破坏数据(Data Corruption)
这是最直接的利用方式。如果相邻块 chunk_B 中存储了关键变量(如认证标志 is_admin、函数指针 func_ptr),直接覆盖它们即可改变程序逻辑。
劫持控制流(Unlink Attack)
这是堆利用的精髓。通过篡改空闲块的 fd 和 bk 指针,利用 free() 函数中的脱链(Unlink)操作来修改内存。
Unlink宏的简化逻辑:
1 | /* P 是正在被 Unlink 的块 */ |
攻击步骤:
- 伪造指针:利用溢出,将
chunk_B的fd改为target_addr - 24,bk改为expected_value。 - 触发Free:当程序调用
free()并触发合并操作时,执行 Unlink。 - 效果:程序会将
expected_value写入target_addr。
实际场景:修改 GOT 表,将 free 或 puts 的地址改为 system 函数的地址。
下面就是对于逻辑的详细解释:
1. 场景还原
想象有三个空闲的堆块连在一起:BK<——>P<——>FD
BK (Backward): 后继堆块。
P (Current): 当前堆块。
FD (Forward): 前驱堆块。
**Unlink的目的:**把 P 从链表中拿走,让 BK 和 FD 直接连接在一起。
2. 代码逐行深度解析
在 64 位系统中,一个 malloc_chunk 结构体的前两个字段 prev_size 和 size 各占 8 字节。
fd指针位于偏移 0x10 (16) 处。bk指针位于偏移 0x18 (24) 处。
我们详细的一行一行来看:
第1&2行:获取邻居
1 | FD = P->fd; // 读取 P 的偏移 +16 处的值,赋给 FD |
正常情况下:FD 指向前驱堆块的起始地址,BK 指向后驱堆块的起始地址。
攻击视角:如果你通过堆溢出覆盖了 P 的头部,你可以把 P->fd 和 P->bk 改成任意数值(任意地址)。
第3行:修改前驱(The Write)
1 | FD->bk = BK; |
- 实际意思:找到指针
FD指向的地址,加上bk字段的偏移(24),向这个位置写入BK的值。 - 实际的计算操作:
*(FD + 24) = BK - 攻击利用:
- 假设你想向内存地址
Target_Addr写入数据。 - 你可以控制
FD的值为Target_Addr - 24。 - 那么
FD + 24就变成了Target_Addr - 24 + 24=Target_Addr。 - 程序就会把
BK的值写到Target_Addr里。
- 假设你想向内存地址
第4行:修改后继(The Side Effect)
1 | BK->fd = FD; |
-
实际意思:找到指针
BK指向的地址,加上fd字段的偏移(16),向这个位置写入FD的值。 -
实际的计算操作:
*(BK + 16) = FD -
注意:这是一个“副作用”,程序会崩溃。在早期的 Unlink 攻击中,这会破坏
Target_Addr附近的数据,或者需要我们构造一个可写的区域来承载这个写入,防止程序崩溃。
漏洞利用存在的矛盾点!
这里解释一下前面这个副作用!
作为攻击者:我们通常把 BK 视为一个 “值”(比如我想把 is_admin 改成 1,那 BK 就是 1;或者我想把 GOT 表改成 shellcode 地址,那 BK 就是 shellcode 的起始地址)。
作为程序逻辑:Unlink 宏把 BK 视为一个 “合法的堆块指针”。它必须是一个指向可写内存的地址。
场景一:直接 Crash (Segmentation Fault)
假设你想把内存中某个变量 target 的值改成 1。
- 你构造
FD = &target - 24。 - 你构造
BK = 0x00000001。
执行过程:
- 第一步(攻击成功):
FD->bk = BK。target变成了1。到这里很完美。
- 第二步(副作用爆发):
BK->fd = FD。- 程序试图执行:
*(0x00000001 + 16) = FD。 - 程序试图往内存地址
0x00000011写入数据。 - 崩溃! 操作系统会报段错误(Segfault),因为
0x11不是一个合法的用户可写内存地址。
- 程序试图执行:
结论: 简单的改小数值(如置 1,置 0)在 Unlink 攻击中很难实现,因为小数值加 16 依然是无效地址。
场景二:破坏数据 (Data Corruption)
假设你想劫持 GOT 表,把 free 函数的地址改成你的 Shellcode 地址(假设 Shellcode 在堆上,地址是 0xHeapAddr)。
- 你构造
FD = &GOT_free - 24。 - 你构造
BK = 0xHeapAddr。
执行过程:
- 第一步(攻击成功):
FD->bk = BK。GOT_free变成了0xHeapAddr。下次调用free就会跳到 shellcode。
- 第二步(副作用爆发):
BK->fd = FD。- 程序执行:
*(0xHeapAddr + 16) = FD。 - 程序把
FD的值(也就是&GOT_free - 24这个巨大的指针数值)写进了你的 Shellcode 的第 16 到 24 字节的位置。
- 程序执行:
后果: 你的 Shellcode 本来写得好好的机器码,中间突然被“脏数据”覆盖了 8 个字节。当 CPU 执行到这里时,指令错乱,程序崩溃。
攻击者如何去解决这个矛盾点呢?
为了应对崩溃的情况,攻击者必须精心构造BK,满足两个条件:
(1)BK 指向的区域必须是“可写”的(防止 Segfault)。
(2)被破坏的那 8 个字节不能影响后续执行。
解决方案A:使用”跳板“指令(Short Jump)
这是针对 Shellcode 被破坏的经典解法。
既然我们知道 Shellcode 的第 16-24 字节会被覆盖掉,那我们就不要在那儿放重要的代码。
构造 Shellcode 的布局:
1 | Offset 0: JMP Offset 30 <-- 第一条指令就是“跳”! |
原理: 当程序跳转到 Shellcode (BK) 时,第一条指令直接跳过了“被污染区域”,完美避开了副作用造成的破坏。
解决方案B:指向无用数据的可写段**
如果我们不是为了执行 Shellcode,只是为了修改某个函数指针(比如指向 libc 中的 system 函数),而 system 函数的地址我们没法改(它是代码段,不可写)。这时候怎么办?
这在传统 Unlink 中很难办到(因为 BK 必须指向可写内存)。所以传统的 Unlink 更多用于:
(1)堆上的 Shellcode 执行(堆本身可写)。
(2)修改指向堆内的指针。
如果必须指向不可写区域(如代码段),攻击者通常不会使用 Unlink,而是转向其他利用方式(如 Fastbin Attack 或 Tcache Poisoning,因为它们对反向指针的检查没那么严格)。
总结
所谓“构造一个可写的区域来承载这个写入”,意思就是:
我知道你要往
BK + 16这个地方写脏数据,所以我特意把BK设置在一个允许你写脏数据的地方(可写内存),而且我保证我不去执行脏数据那里的代码。
3.攻击复盘:如何实现”任意地址写“?
假设我们想把变量 Global_Var 的值修改为 0xDEADBEEF。
(1)溢出:我们通过溢出,控制了堆块 P。
(2)伪造 P->fd:我们将 P->fd 设置为 &Global_Var - 24。
(3)伪造 P->bk:我们将 P->bk 设置为 0xDEADBEEF (把它伪装成一个地址)。
(4)触发 Unlink:当 free(P) 发生时,执行逻辑:
FD = &Global_Var - 24BK = 0xDEADBEEFFD->bk = BK->*(&Global_Var - 24 + 24) = 0xDEADBEEF- 结果:
Global_Var = 0xDEADBEEF。
攻击成功!
4. 现代防御:Safe Unlink (glibc 2.23+)
glibc后来加上了一个非常简单的效验:
1 | if (P->fd->bk != P || P->bk->fd != P) { |
逻辑是: 既然 P 说 FD 是它的前驱,那么 FD 的后继(FD->bk)必须指向 P。如果不是,说明有人在撒谎(篡改了指针),程序直接崩溃。