前言
英语不错的师傅们,建议直接看英文原版,英文可能还更好理解一些。文章内容,大部分来自作者@jack_halon。该文章仅作为自己的学习笔记,如果有错误的地方,还希望师傅们批评指正。
V8是什么?
我们都知JavaScript,Javascript代码的执行依赖于JavaScript引擎,而V8就是JavaScript引擎中的一种。
目前实际有很多不同的JavaScript引擎在使用,例如:
- V8 - Google 的开源高性能 JavaScript 和 WebAssembly 引擎,用于 Chrome 浏览器。
- SpiderMonkey - Mozilla 的 JavaScript 和 WebAssembly 引擎,用于 Firefox。
- Charka - 微软开发的专有 JScript 引擎,用于 IE 和 Edge 浏览器。
- JavaScriptCore - 苹果公司为 Safari 浏览器内置的 WebKit JavaScript 引擎。
众所周知,JavaScript 是一种轻量级、 解释型 、面向对象的脚本语言。在解释型语言中,代码逐行执行,执行结果立即返回,因此无需在浏览器运行前将代码编译成其他形式。但出于性能方面的考虑,这通常会导致此类语言性能不佳。在这种情况下,就需要用到编译技术,例如即时编译(Just-In-Time ,JIT)。JIT 将 JavaScript 代码解析成字节码(机器代码的抽象形式),然后进行进一步优化,从而显著提高代码效率,使其运行速度更快。
虽然上述各种 JavaScript 引擎可能拥有不同的编译器和优化器,但它们的设计和实现方式几乎完全相同,都基于 EcmaScript 标准(也常与 JavaScript 互换使用)。EcmaScript 规范详细说明了浏览器应如何实现 JavaScript,以确保 JavaScript 程序在所有浏览器中都能以完全相同的方式运行。
JavaScript引擎的工作流程
那么,执行JavaScript代码之后,究竟发生了什么呢?下面提供了一张图标,该图标展示了JavaScript引擎的一般“流程”,也被称为编译管道[1](compilation pipeline of JavaScript engines)。
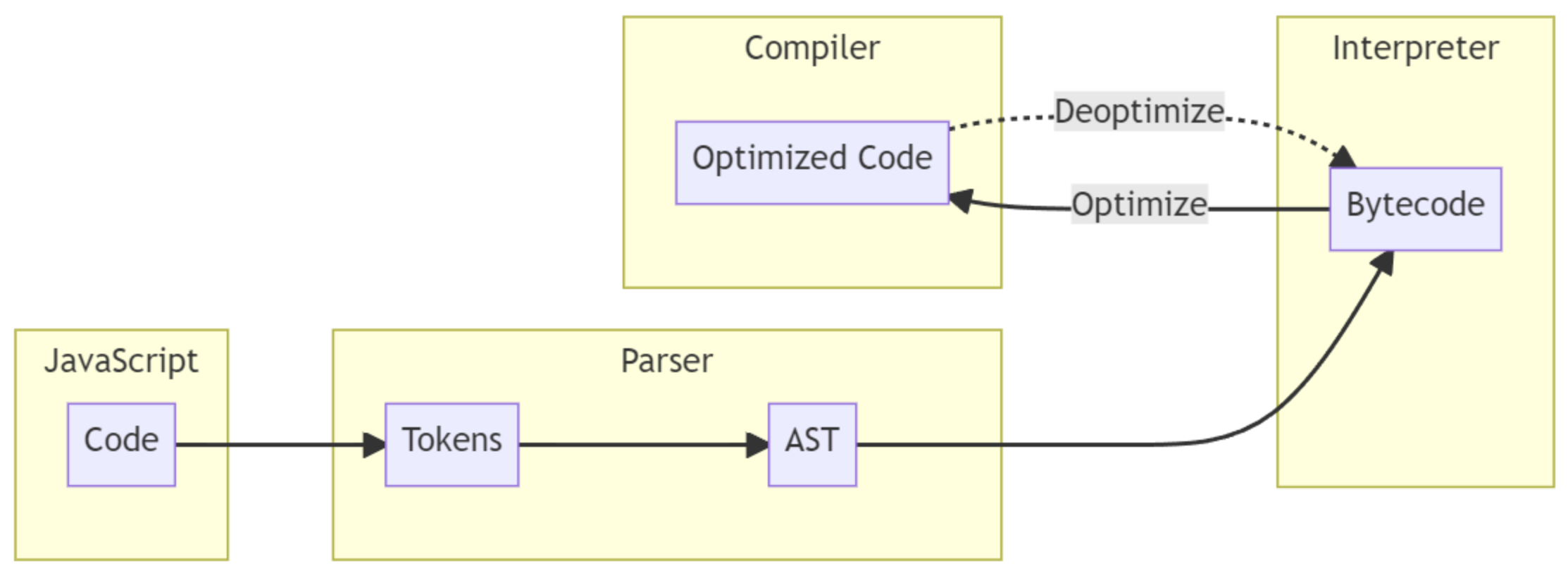
乍一看可能有点复杂,但别担心——其实并不难理解。那么,让我们一步一步地分解这个“流程”,并解释每个组成部分的作用。
-
**解析器(Parser):**执行 JavaScript 代码后,代码会被传递给 JavaScript 引擎,然后我们进入第一步,即解析代码。解析器会将代码转换为以下格式:
-
**词法单元(Tokens):**代码首先被分解成“词法单元(tokens)”,例如:Identifier, Number, String, Operator等。这被称为“词法分析(Lexical Analysis)”或“词法单元化(Tokenizing)”。
- 例如:
var num = 42被分解为var,num,=,42,然后每个“标记(token)”或项目都用其类型进行标记,因此在本例中将是:Keyword,Identifier,Operator,Number。
- 例如:
-
抽象语法树(Abstract Syntax Tree, AST):代码被解析成tokens后,解析器会将这些tokens转换成抽象语法树(AST)。这部分称为“语法分析(Syntax Analysis)”,顾名思义,它的作用是检查代码中是否存在语法错误。
-
例如:上面的代码样例,AST看起来像下面这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26{
"type": "VariableDeclaration",
"start": 0,
"end": 13,
"declarations": [
{
"type": "VariableDeclarator",
"start": 4,
"end": 12,
"id": {
"type": "Identifier",
"start": 4,
"end": 7,
"name": "num"
},
"init": {
"type": "Literal",
"start": 10,
"end": 12,
"value": 42,
"raw": "42"
}
}
],
"kind": "var"
}
-
-
-
**解释器(Interpreter):**AST生成后,会被传递给Interpreter,Interpreter会遍历AST并生成字节码(bytecode),字节码生成后,会被执行,然后 AST 会被删除。
V8的字节码,可以在这里找到。
下面就是
var num = 42;的字节码示例:1
2
3
4
5
6
7
8LdaConstant [0]
Star1
Mov <closure>, r2
CallRuntime [DeclareGlobals], r1-r2
LdaSmi [42]
StaGlobal [1], [0]
LdaUndefined
Return -
**编译器(Compiler):**Compiler会预先使用一种叫做“性能分析器(Profiler)”的工具来监控和观察需要优化的代码。如果存在所谓的“热点函数(hot function)”,Compiler会获取该函数并生成优化后(optimized)的机器代码来执行。否则,如果Compiler发现某个已优化的“hot function”不再被使用,它会将其“反优化(deoptimize)”回字节码。
谷歌的 V8 JavaScript 引擎的编译流程与之非常相似。不过,V8 包含一个额外的“非优化”编译器,该编译器于 2021 年新增。现在,V8 的每个组件都有特定的名称,它们如下:
- **Ignition:**V8 的快速底层寄存器解释器,用于生成字节码
- **SparkPlug:**V8 的新型非优化(non-optimizing) JavaScript 编译器,它通过迭代bytecode并为每个访问到的bytecode生成机器代码(machine code),从字节码进行编译。
- **TurboFan:**V8 的优化编译器(optimizing compiler),它使用更多、更复杂的代码优化功能将bytecode翻译成machine code。它还包含 JIT(Just-In-Time)编译功能。
综上所述,V8编译流程的概览如下:

现在,如果像编译器(compilers)和优化(optimizations)之类的概念或特性你现在还不太理解,也不用担心。这篇文章并不需要你完全理解整个编译流程,但你应该对引擎的整体工作原理有一个大致的了解。
在此之前,如果你想了解更多关于管道(pipeline)的信息,建议观看“JavaScript Engines: The Good Parts[2]”,以获得更好的理解。
目前,你只需要理解这个编译流程中的一点:解释器(interpreter)是一个“栈式机器(stack machine)”,或者说本质上是一个虚拟机(VM),bytecode就是在这个虚拟机中执行的。而对于Ignition(V8的interpreter)来说,它实际上是一个带有累加寄存器的“寄存器式机器(register machine)”。Ignition仍然使用栈,但它更倾向于将数据存储在寄存器中以提高速度。
建议阅读“Understanding V8’s Bytecode[3]”和“Firing up the Ignition Interpreter[4]”,以便更好的掌握这些概念。
JavaScript和V8内部机制
现在我们已经对 JavaScript 引擎及其编译器管道的结构有了一些基本的了解,是时候深入了解 JavaScript 本身的内部结构,看看 V8 如何在内存中存储和表示 JavaScript 对象,以及它们的值和属性。
如果你想利用 V8 以及其他 JavaScript 引擎中的漏洞,那么理解这一部分至关重要 。因为事实证明,所有主流引擎对 JavaScript 对象模型的实现方式都大同小异。
众所周知,JavaScript 是一种动态类型语言。这意味着类型信息与运行时值相关联,而不是像 C++ 那样与编译时变量相关联。因此,JavaScript 中的任何对象都可以在运行时轻松修改其属性。JavaScript类型系统定义了诸如 Undefined、Null、Boolean、String、Symbol、Number 和 Object(包括arrays和functions)等数据类型。
简单来说,这意味着什么?嗯,这通常意味着,与 C++ 不同,JavaScript 中的对象或基本类型,例如 var 可以在运行时改变其数据类型。例如,让我们在 JavaScript 中创建一个名为 item 新变量,并将其值设置为 42 。
通过在 item 变量上使用typeof运算符,我们可以看到它返回其数据类型——即 number 。
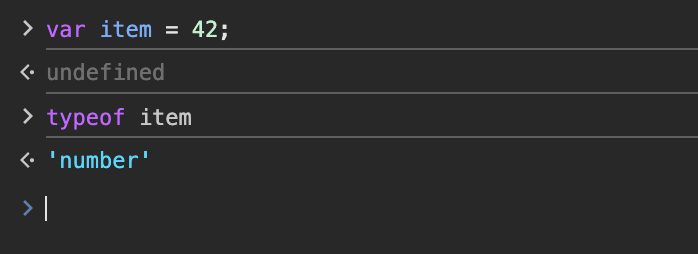
如果我们将 item 设置为字符串,然后检查它的数据类型,会发生什么情况?
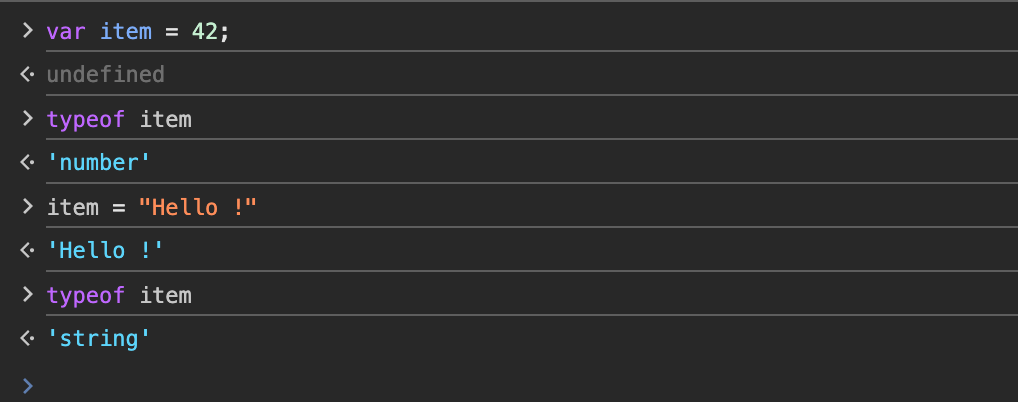
你看, item 变量现在被设置为 string 类型,而不是 number 类型。这就是 JavaScript 的“动态(dynamic)”特性。与 C++ 不同,如果我们尝试创建一个 int 或整数类型的变量,然后再尝试将其设置为字符串类型,就会失败——就像这样:
1 | int item = 3; |
虽然这在 JavaScript 中很酷,但它确实给我们带来了一个问题。V8 和 Ignition 是用 C++ 编写的,因此Interpreter和Compiler需要弄清楚 JavaScript 打算如何使用某些数据。这对于高效的代码编译至关重要,尤其是在 C++ 中,像 int 和 char 这样的数据类型占用的内存大小不同。
除了效率之外,这对于安全性也至关重要,因为如果Interpreter和Compiler错误地 “interpret”了 JavaScript 代码,导致我们得到的是一个字典对象(dictionary object)而不是数组对象(array object),那么我们就遇到了类型混淆漏洞(Type Confusion vulnerability)。
那么 V8 如何将所有这些信息与每个运行时值一起存储,引擎又是如何保持高效的呢??
在 V8 中,这是通过使用一种名为Map的专用信息类型对象来实现的(不要与Map Objects混淆了),它也被称为**“Hidden Classs”。有时你可能会听到Map被称为“Shape”**,尤其是在 Mozilla 的 SpiderMonkey JavaScript 引擎中。
V8 还使用一种称为指针压缩(pointer compression)或指针标记(pointer tagging)的内存技术来减少内存消耗,并允许 V8 将内存中的任何值表示为指向对象的指针。
但是,在我们深入研究所有这些功能的细节之前,我们首先必须了解什么是 JavaScript 对象以及它们在 V8 中是如何表示的。
Object Representation 对象表示
在 JavaScript 中,对象本质上是一组属性的集合,这些属性以键值对的形式存储——这意味着对象本质上类似于字典(dictionaries)。对象可以是数组(Arrays)、函数(Functions)、布尔值(Booleans)、正则表达式(RegExp)等等。
在JavaScript中,每个对象都关联着属性(properties),**属性可以简单地理解为定义对象特征的变量。**例如,一个新创建的car对象可以拥有诸如make、model和year之类的属性,这些属性有助于定义这辆car。你可以通过简单的点号运算符(例如objectName.propertyName)或方括号运算符(例如objectName['propertyName'])来访问对象的属性。
此外,每个对象的属性都映射到属性特性(property attributes),这些特性用于定义和解释对象属性的状态。下面展示了JavaScript对象中这些属性特性的示例。
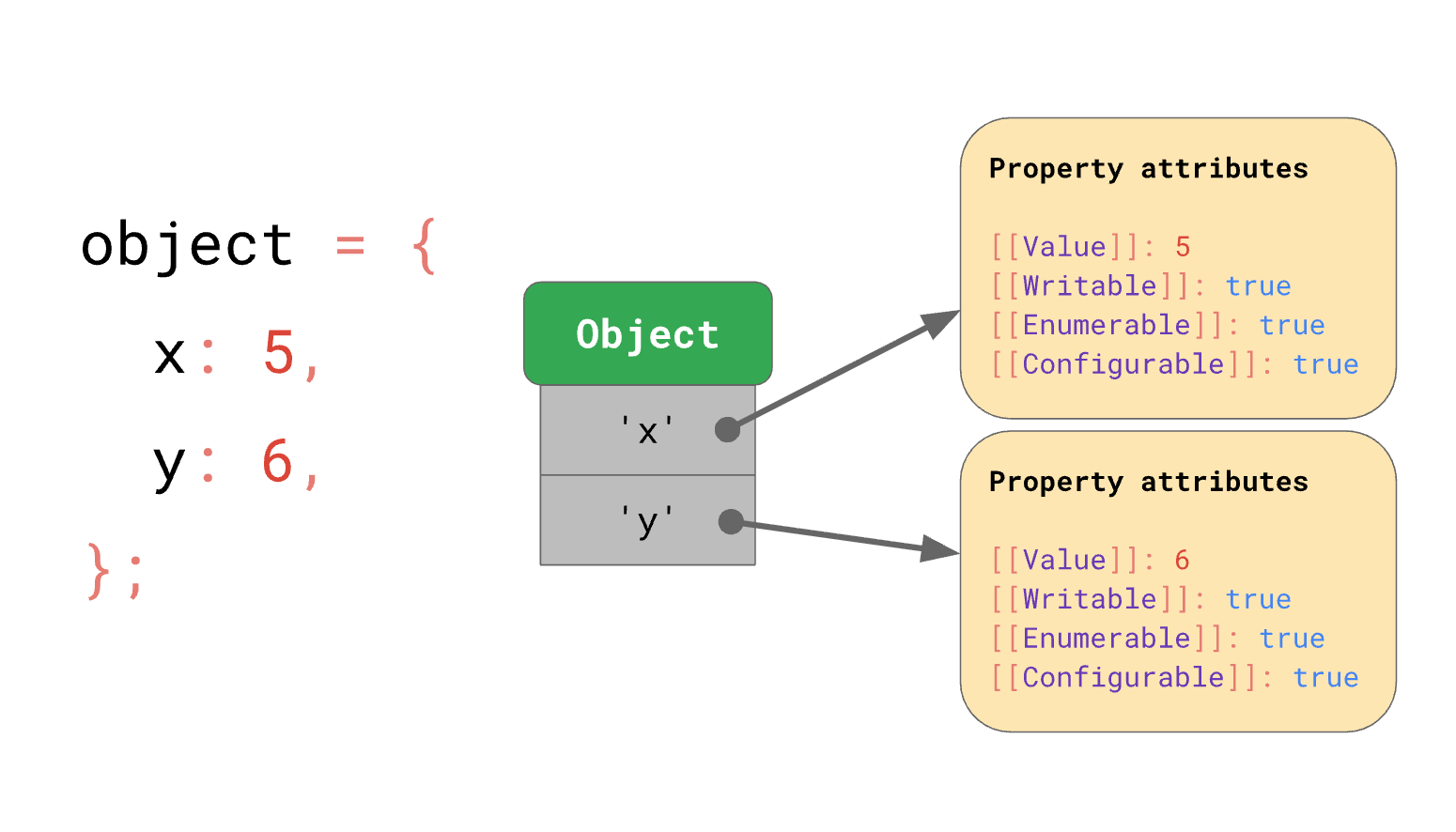
现在我们对对象有了一些了解,下一步是了解对象在内存中的结构以及它的存储位置。
每当创建一个对象的时,V8都会创建一个新的JSObject对象,并在堆上为其分配内存。该对象的值是指向JSObject,其结构中包含以下内容:
-
Map:指向HiddenClass对象的指针,详细说明对象的Shape或者结构。
-
**Properties:指向包含命名属性(named properties)**的对象的指针。
-
**Elements:**指向包含编号属性的对象的指针。
-
In-Object Properties:指向在对象初始化时定义的命名属性(named properties)的指针。
为了帮助更好的理解,下图详细说明了基本的V8 JSObject在内存中的结构。
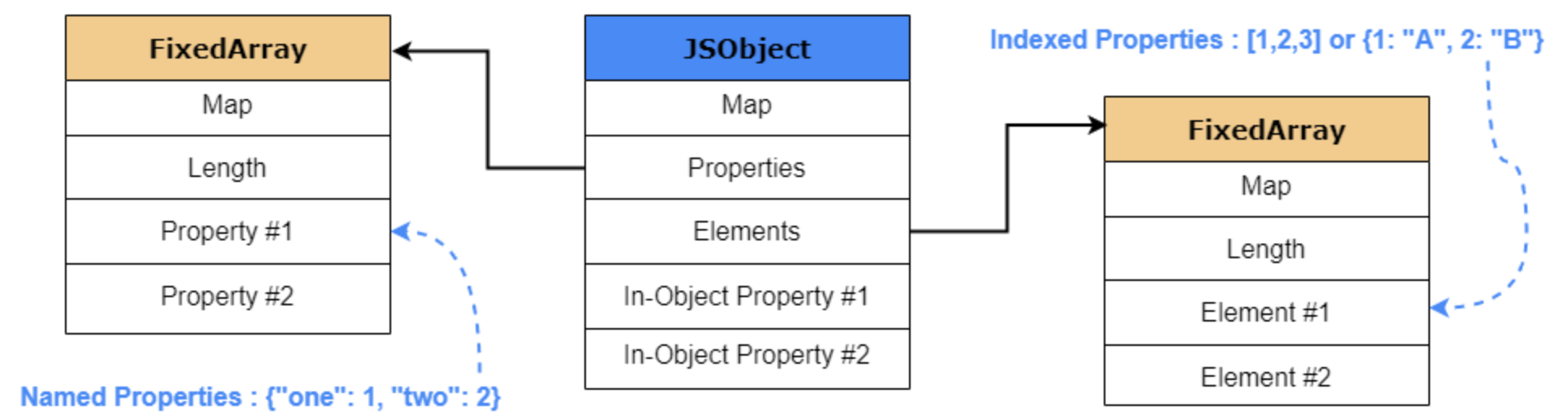
观察JSObject的结构,我们可以看到属性(Properties)和元素(Elements)分别存储在两个独立的FixedArray数据结构中,这使得添加和访问Properties或Elements更加高效。
Elements结构主要存储非负整数(non-negative)或数组索引(array-indexed)属性(keys),这些通常被称为元素(Elements)。
Properties结构,如果对象的Property键不是非负整数,例如string,则该属性将存储为内联对象属性(Inline-Object Property)或者存储在Elements结构中,有时也称为对象的属性后备存储(objects properties backing store)。
需要注意的是,虽然命名属性(named properties)的存储方式与数组元素类似,但它们在属性访问方面却并不相同。与元素不同,我们不能直接使用键(key)来查找命名属性(named properties)在属性数组中的位置;我们需要一些额外的元数据。如前所述,V8使用一个名为HiddenClass或Map特殊对象,该对象与每个JSObject相关联。这个Map存储了JavaScript对象的所有信息,从而使V8能够“动态(dynamic)”运行。
因此,在进一步了解JSObject结构及其属性之前,我们首先需要了解V8中的HiddenClass是如何工作的。
HiddenCLass(Map)and Shape Transitions
如前所述,我们知道 JavaScript 是一种动态类型语言。正因如此,JavaScript 中没有类的概念。在 C++ 中,如果你创建了一个类或对象,就无法像在 JavaScript 中那样动态地添加或删除它的方法和属性。在 C++ 和其他面向对象语言中,你可以将对象属性存储在固定的内存偏移量中,因为给定类的实例的对象布局永远不会改变,但在 JavaScript 中,对象布局会在运行时动态变化。为了解决这个问题,JavaScript 使用了一种称为“ 基于原型的继承 ”的机制,其中每个对象都引用一个原型对象(prototype object)或 “ shape ”,并继承其属性。
那么V8是如何存储对象的布局的呢?
这时就需要用到HiddenClass或Map了。HiddenClass的工作方式类似于固定对象布局,其中属性值(或指向这些属性的指针)可以存储在特定的内存结构中,然后通过固定的偏移量进行访问。这些偏移量由Torque生成,可以在V8的/torque-generated/src/objects/*.tq.inc目录中找到。这实际相当于对象的“shape”标识符,从而使V8能够更好地优化JavaScript代码并缩短属性访问时间。
如上文JSObject示例中所示,Map是对象中的另一种数据结构。该Map结构包含以下信息:
- 对象的动态类型,例如String、JSArray、HeapNumber等。
- V8中的对象类型列在/src/objects/objects.h文件中。
- 对象的大小(对象内部属性(in-object properties)等)
- 对象属性及其存储位置
- 数组元素类型
- 对象的Prototype或Shape(如果有的话)
为了帮助理解Map对象在内存中的结构,我在下图提供了一个较为详细的V8 Map结构图。更多关于结构的信息可以在V8的源代码中找到,具体位置在 /src/objects/map.h 和 /src/objects/descriptor-array.h 源文件中。
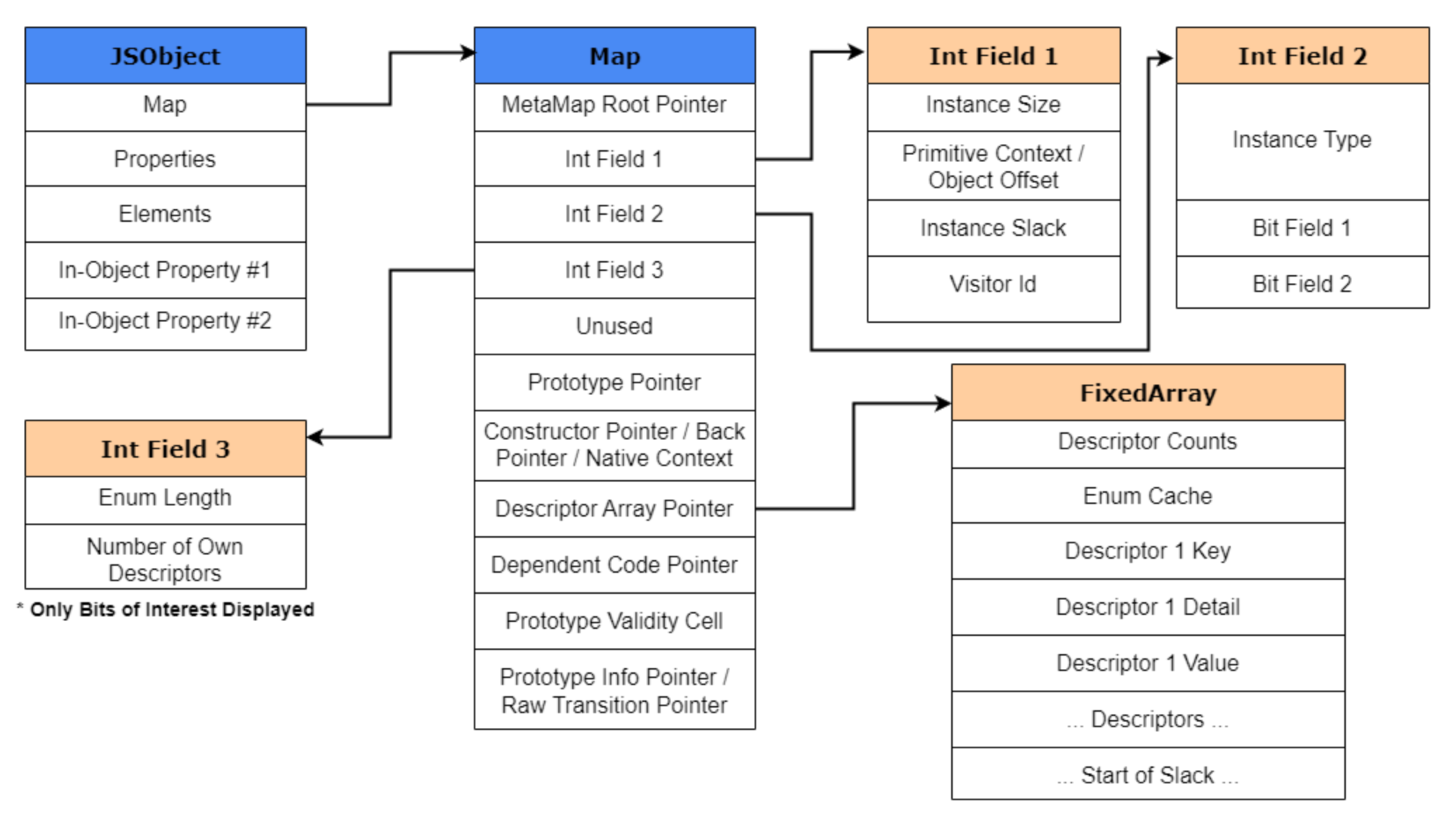
现在我们了解了Map的布局,接下来解释一下我们经常提到的“Shape”。如你所知,每个新创建的JSObject都会有一个hidden class,其中包含每个属性的内存偏移量。有趣的是,如果该对象的属性被创建、删除或动态更改,则会创建一个新的hidden class,这个新的hidden class保留了现有属性的信息,并包含了新属性的内存偏移量。请注意,只有在添加新属性时才会创建新的hidden class,添加数组索引属性不会创建新的hidden class。
那么,这在实践中是如何体现的呢?我们以以下代码为例:
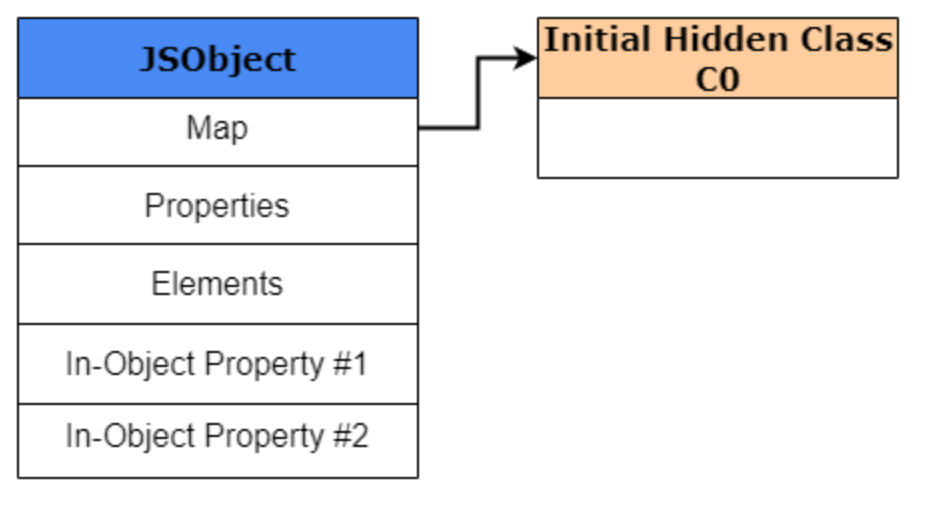
1 | var obj1 = {}; |
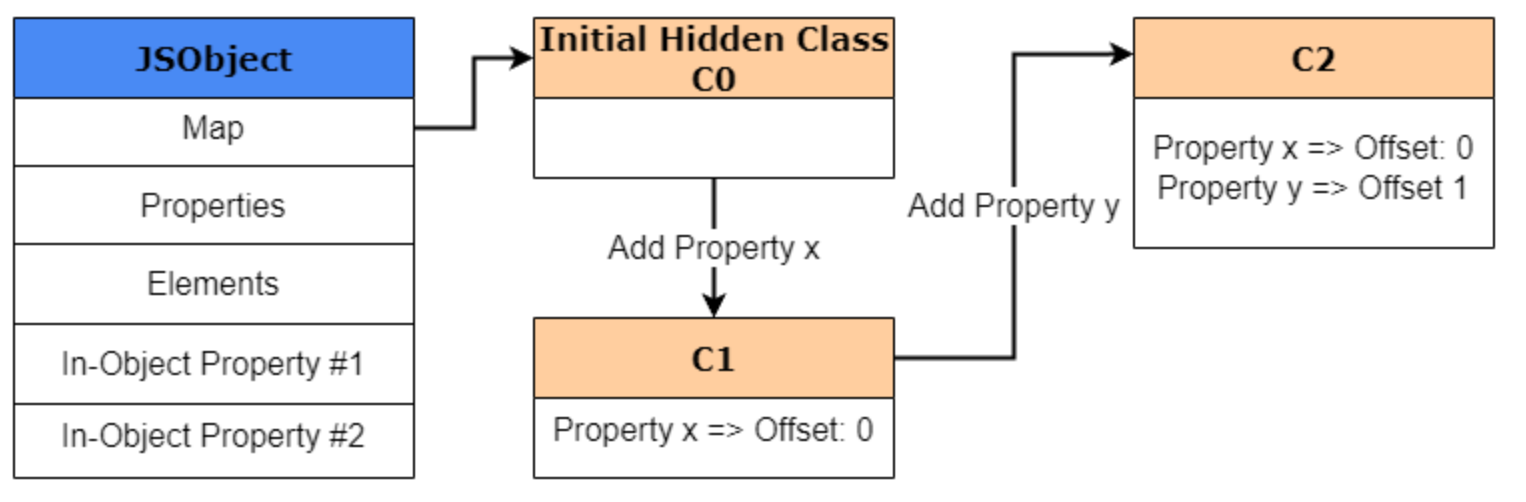
首先,我们创建一个名为obj1新对象,该对象会被创建并存储在V8的堆内存中。由于这是一个新创建的对象,显然需要创建一个hidden class,即使该对象尚未定义任何属性,这个hidden class也会被创建并存储在V8的堆内存中。为了便于示例,我们将这个初始hidden class称为 “C0”。
当执行到下一行代码并执行obj1.x = 1时,V8将创建一个名为 “C1” 的第二个hidden class,该类基于C0。C1是第一个用于描述属性 x 在内存中位置的hidden class。但是,它存储的不是指向 x 值的指针,而是 x 的偏移量,偏移量为 0。
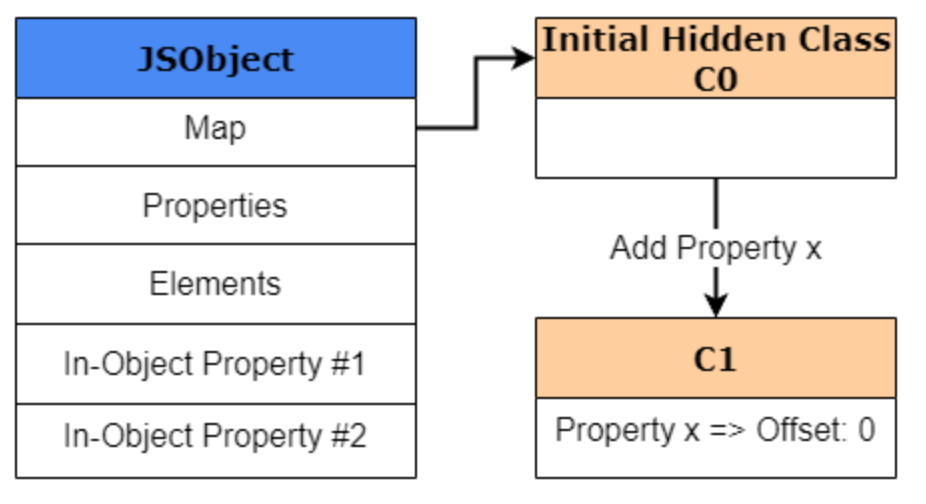
这里为什么是一个对属性(property)的偏移,而不是它的值???🤔
在V8中,这是一种优化技巧。Map对象在内存使用方面相对来说比较昂贵。如果我们把属性的键值对以字典形式存储在每个新创建的JSObject中,那么由于解析字典速度较慢,这将导致大量的计算开销!
其次,如果创建一个新对象obj2,它与obj1共享相同的属性,例如x和y,会发生什么情况?即使它们的值可能不同,但这两个对象实际上共享了相同名称且顺序相同的属性,或者我们称之为相同的**“Shape”**。在这种情况下,将相同的属性名称存储在两个不同的位置会造成浪费。
这正是V8速度快的原因:它经过优化,尽可能在结构相似的对象之间共享Map。由于相同结构的所有对象的属性名称相同且顺序一致,我们可以让多个对象指向内存中同一个HiddenClass,并通过属性偏移量而非值指针来访问它们。此外,由于Map和JSObject一样都是在HeapObject中分配内存,因此也便于垃圾回收。
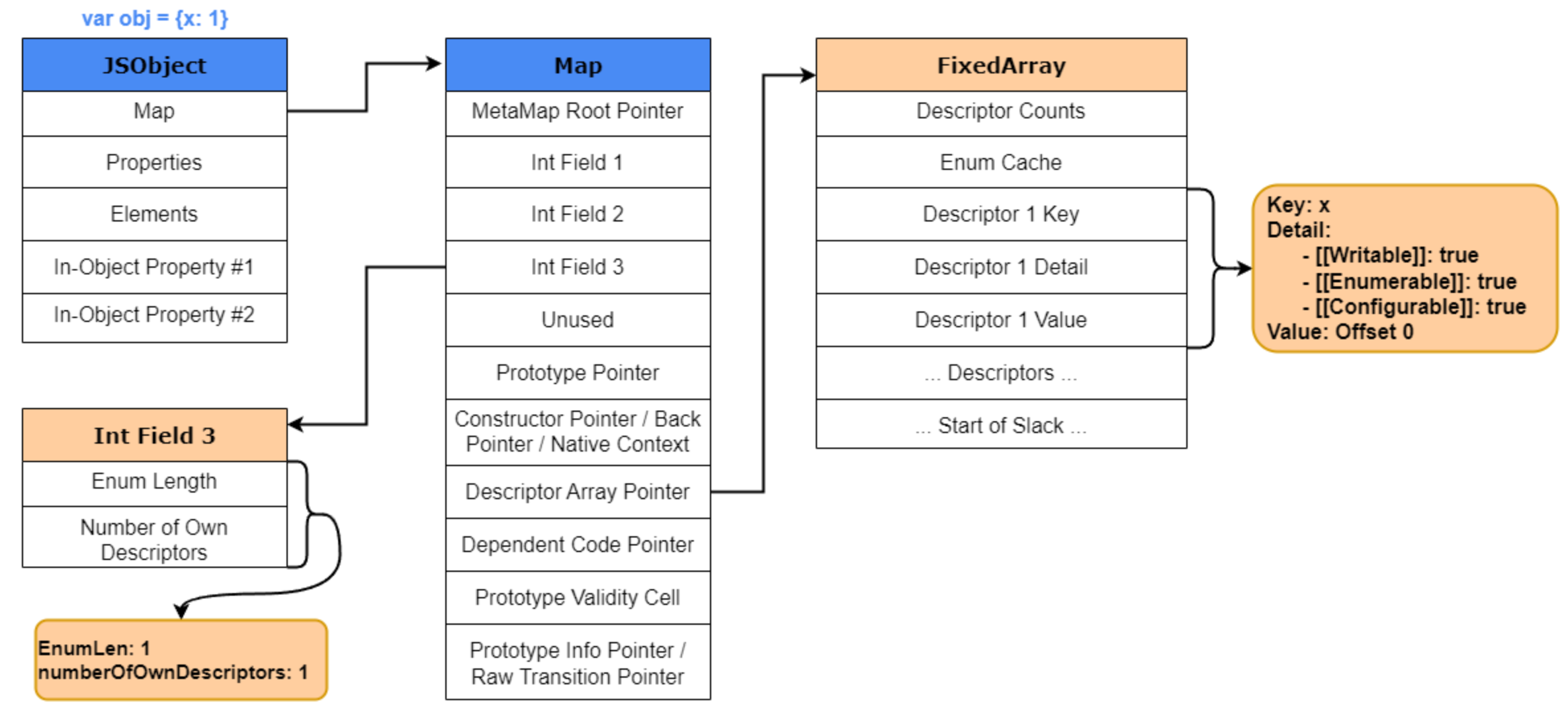
为了更好地解释这个概念,我们暂时跳出上面的例子,来看看HiddenClass的关键部分。HiddenClass中最重要的两个部分是 DescriptorArray和Int Field 3(第三个位字段),它们共同构成了Map的“Shape”。如果你回顾一下上面的 Map 结构,你会发现Int Field 3存储了属性的数量,而 DescriptorArray 则包含了关于已命名属性(named properties)的信息,例如属性名称(name)、值存储的位置(offset)以及属性的具体属性值(properties attributes)。
例如,假设我们创建一个新对象var obj { x : 1}。x 属性将被存储在JavaScript对象的“对象内属性(In-Object properties)” 或 称“属性存储(Properties store)”。由于创建了一个新对象,同时也会创建一个新的HiddenClass。在该HiddenClass中,描述符数组(descriptor array)和Int Field 3将被填充。由于我们只有一个属性,Int Field 3会将numberOfOwnDescriptors 设置为 1 ,然后描述符数组(descriptor array)会填充与属性x相关的详细信息,包括键(key)、详细信息(detail)和值(value)。该描述符(descriptor)的值(value)将被设置为0。
为什么是0呢?因为对象内属性(In-Object properties)和属性存储(Properties store)本质上就是一个数组。因此,通过描述符的值设置为0,V8就知道对于任何相同类型的对象,key的value都将位于该数组的偏移量0处。
下面可以看到我们刚才解释内容的直观示例:
V8调试
让我们看看在V8中会是什么样子。首先使用 --allow-natives-syntax参数启动v8,并执行以下JavaScript代码:
1 | var obj1 = {a: 1, b: 2, c: 3} |
完成后,我们将使用%DebugPrint()命令来显示对象的属性(properties)、映射(map)以及其他信息,例如实例描述符(instance descriptor)。执行后,注意以下事项:
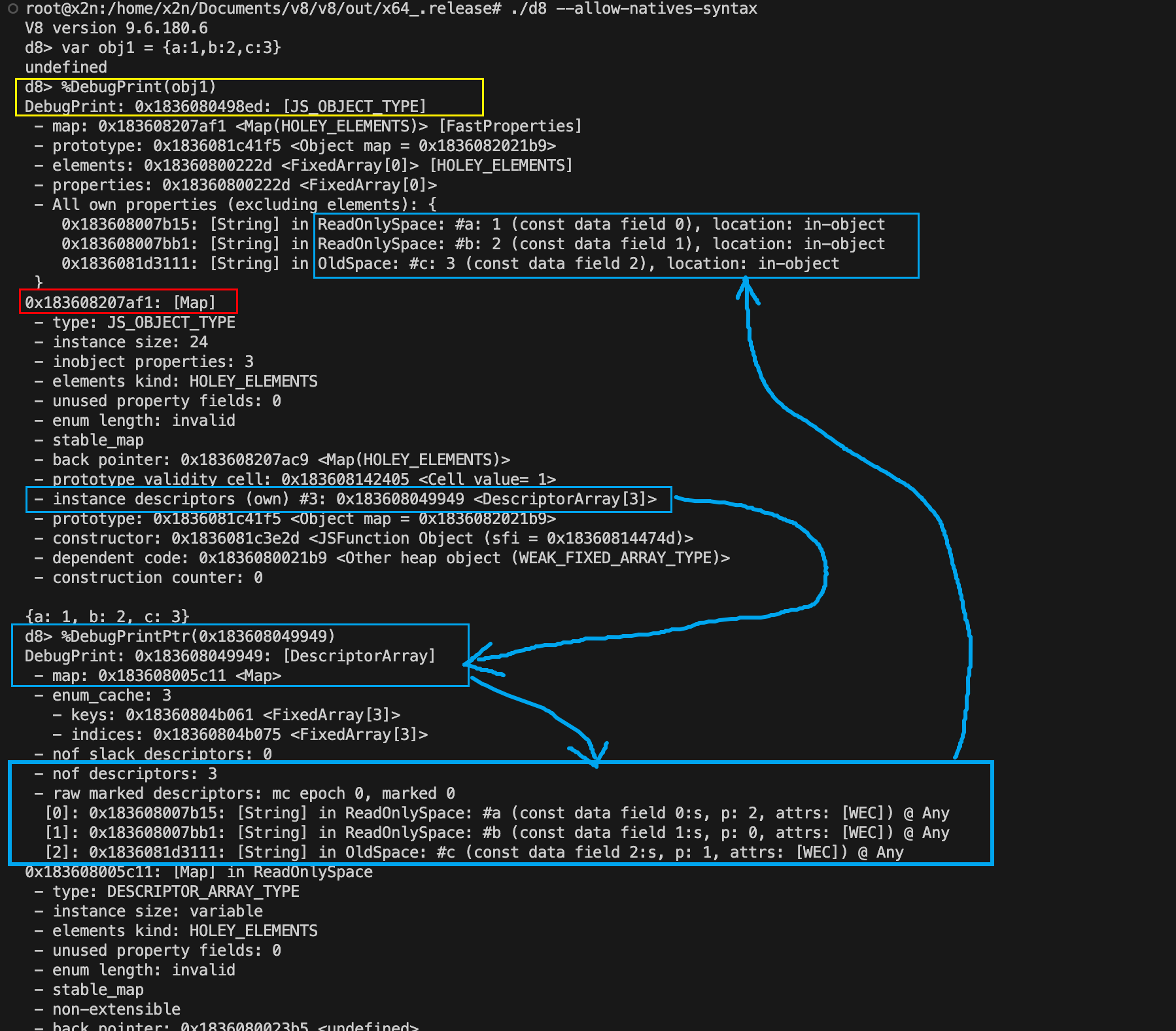
黄色部分显示的是我们的对象obj1。红色部分显示的是指向HiddenClass或Map的指针。在该HiddenClass中,我们找到了指向DescriptorArray的实例描述符(instance descriptors)。使用%DebugPrintPtr()函数访问该数组的指针,我们可以看到该数组在内存中的更多细节,这些细节以蓝色高亮显示。
请注意,我们有3个属性,这与Map中instance descriptors部分的descriptors数量一致。在下方,我们可以看到descriptors数组保存着属性键,而const data field则保存着属性存储中对应属性值的偏移量。现在,如果我们沿着箭头从偏移量向上找到对象,我们会发现偏移量确实匹配,并且每个属性都已分配了正确的值。
另外,请注意这些属性的右侧,您可以看到每个属性的location ;正如我之前提到的,这些属性位于in-object 。这几乎可以证明,这些偏移量指向的是对象内部(In-Object)和属性存储(Properties store)中的属性。
好了,现在我们明白了为什么要使用偏移量(offset),让我们回到之前的HiddenClass示例。正如我们之前所说,通过向obj1添加属性x,我们现在会创建一个名为“C1”的新HiddenClass,其偏移量为x。由于我们创建了一个新的HiddenClass,V8会使用“类转换(class transition)”更新“C0”,该转换表明,如果创建了一个具有属性x的新对象,则HiddenClass应直接切换到“C1”。
然后,当我们执行obj1.y = 2,这个过程会重复进行。此时会创建一个名为C2的新HiddenClass,并在C1中添加一个类转换,该转换声明对于任何具有属性x对象,如果添加了属性y,则HiddenClass应转换到C2。最终,所有这些类转换会形成一个称为“转换树(transition tree)”的结构。
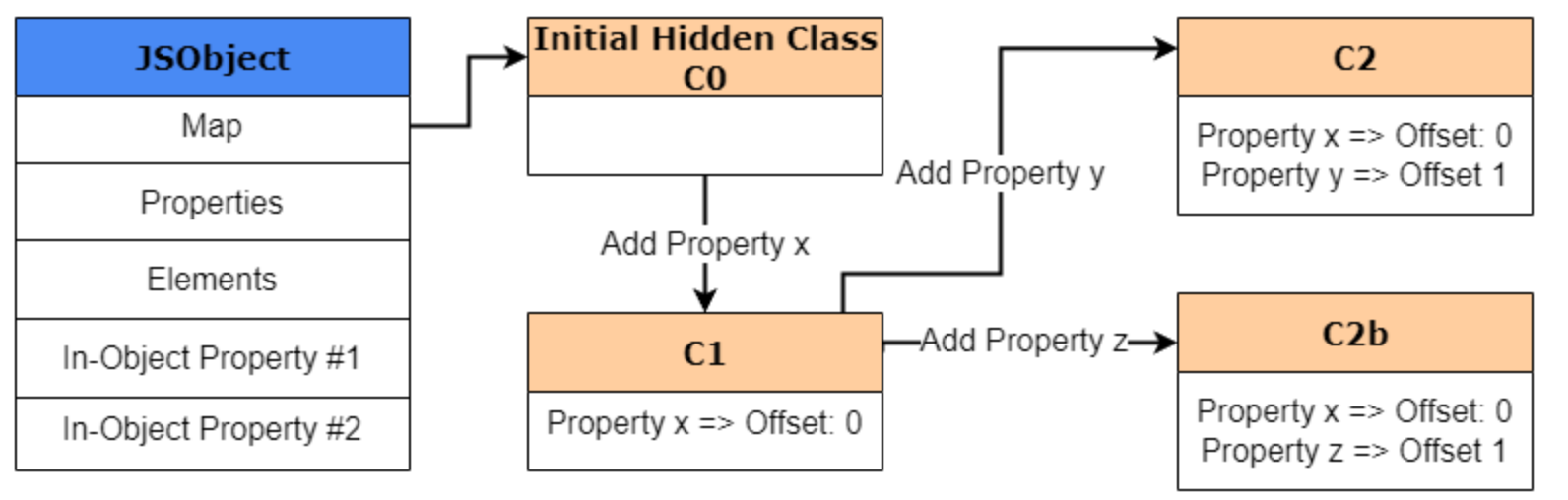
此外,需要注意的是,类转换取决于属性添加到对象的顺序。因此,如果属性 z 是在属性 y 之后添加的,“Shape”将不再相同,也不会遵循从 C1 到 C2 的相同转换路径。取而代之的是,将创建一个新的HiddenClass,并添加一条从 C1 到 C2 的新转换路径来处理该新属性,从而进一步扩展转换树。
现在我们理解了这一点,让我们来看看当两个形状相同的对象共享一个 Map 时,对象在内存中的样子。
首先,使用 --allow-natives-syntax 参数再次启动 d8 ,然后输入以下两行 JavaScript 代码:
1 | d8> var obj1 = {x: 1, y: 2}; |
完成后,我们将再次使用 %DebugPrint() 命令对每个对象进行测试,以显示它们的properties、map和其他信息。执行后,请注意以下事项:
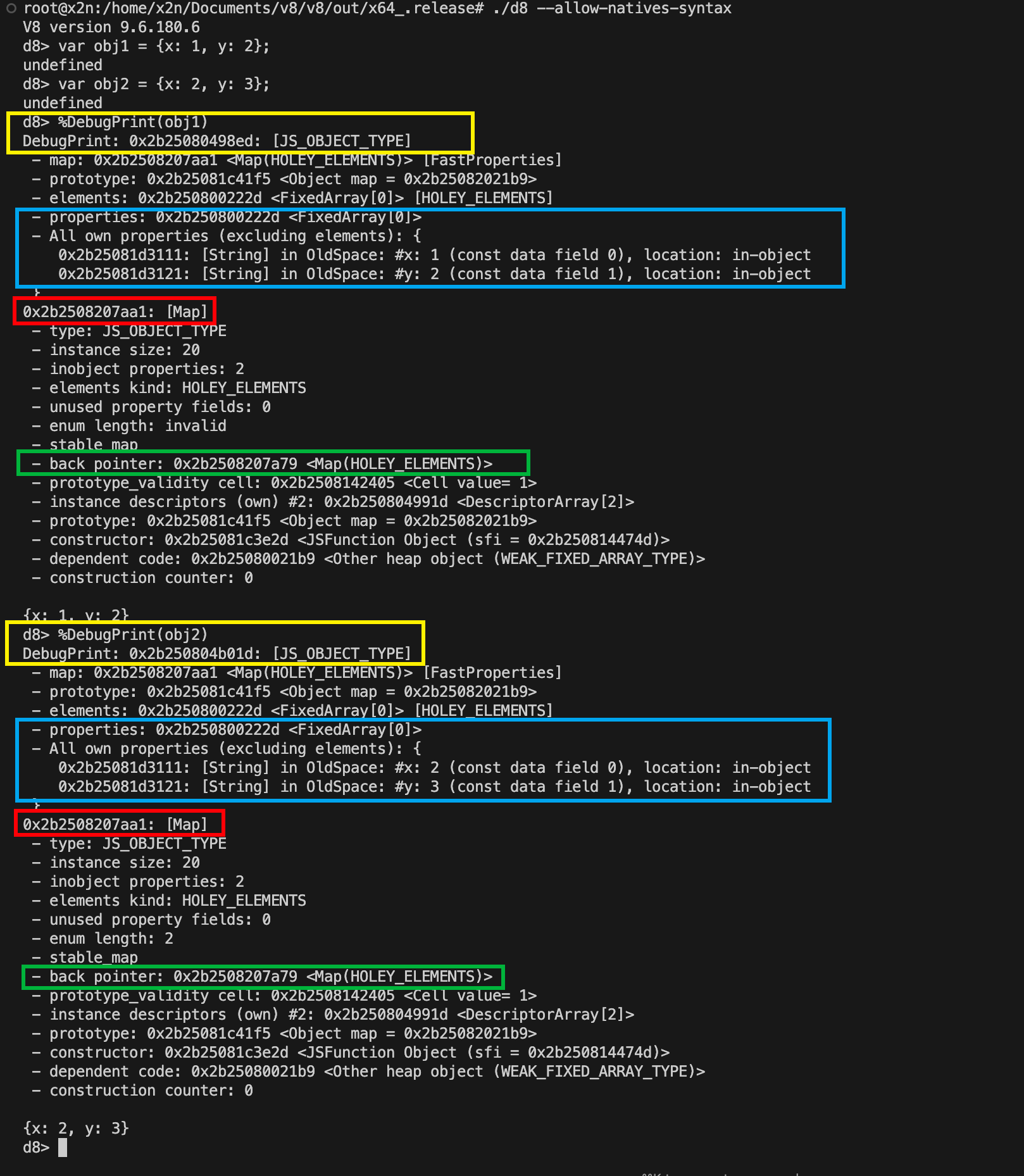
在黄色区域,我们可以看到两个对象obj1和obj2。请注意,它们都是JS_OBJECT_TYPE类型,但在堆内存中拥有不同的地址,因为它们显然是具有不同属性的独立对象。
我们知道,这两个对象shape相同,因为它们都包含顺序相同的x和y属性。在这种情况下,在蓝色区域,我们可以看到这些属性位于同一个FixedArray中,x和y的偏移量分别为0何1。这是因为,正如我们所知,shape相同的对象共享一个HiddenClass(红色区域),该HiddenClass具有相同的描述符数组(descriptor array)。
从图中可见,对象的大多数属性和Map地址都是相同的,因为这两个对象共享同一个Map。
现在我们来关注一下绿色高亮显示的back_pointer。回顾一下我们之前提到的从 C0 到 C2的映射转换示例,你会注意到我们提到过一个叫做“转换树(transition tree)”的东西。每次创建一个新的HiddenClass时,V8都会在后台创建一个transition tree,并将新旧HiddenClass连接起来。这个back_pointer就是transition tree的一部分,因为它指向了转换发生的父映射。这样,V8就可以沿着back_pointer链遍历映射,直到找到保存对象属性的映射,即它们的shape。
下面用d8来深入了解一下它的工作原理。我们将再次使用%DebugPrintPtr()命令来打印V8中地址指针的详细信息。这次我们将使用back_pointer地址来查看其详细信息。完成后,你的输出应该和我的类似。
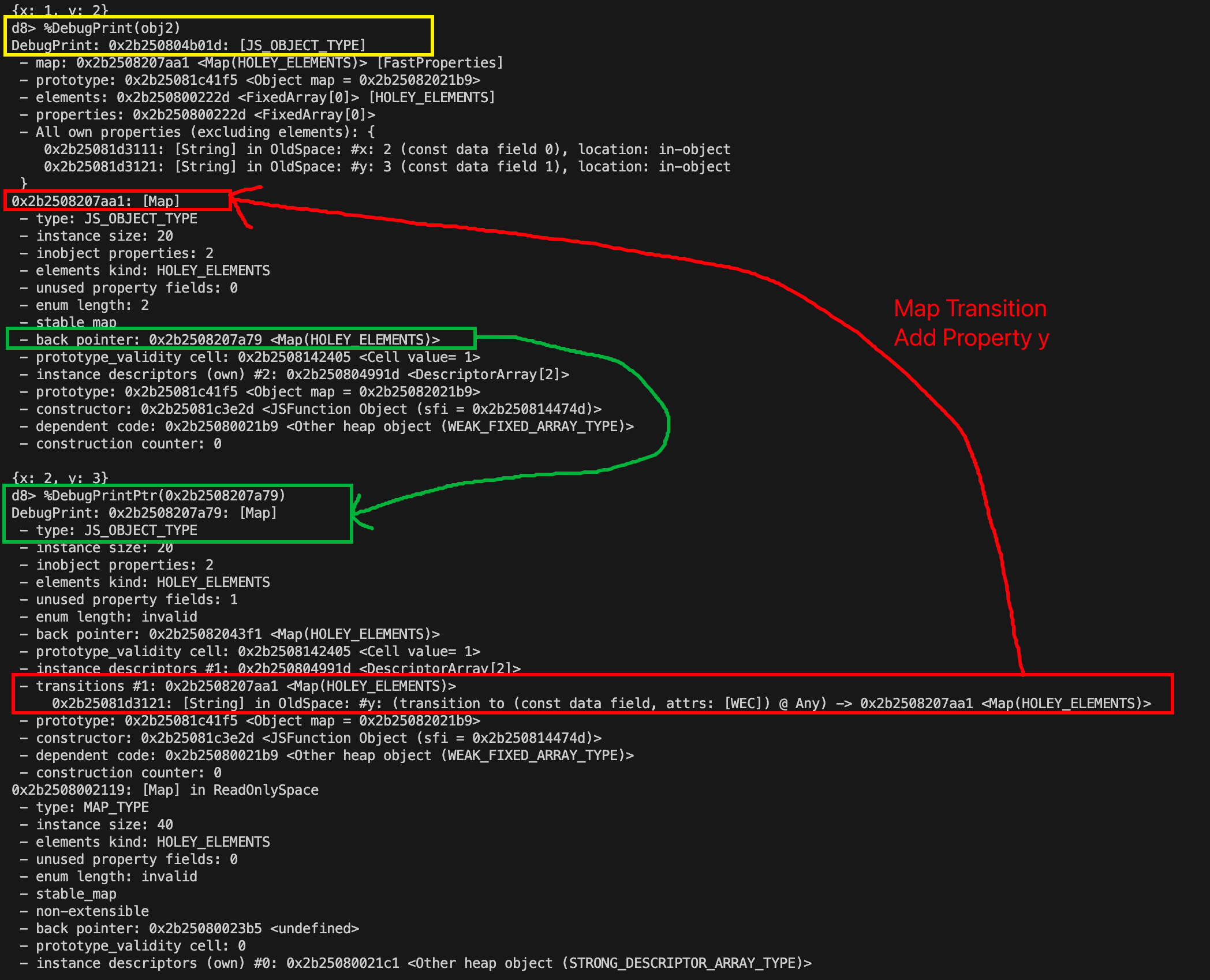
在绿色部分,我们可以看到back_pointer解析到内存中的JS_OBJECT_TYPE,而它实际上是一个Map!这个Map就是我们之前讨论的C1 Map。我们知道Map如何回溯到它之前的Map,但是当添加属性时,它如何知道要转换到哪个Map呢?如果我们仔细观察Map中的信息,就会发现实例描述符下方有一个红色的**”transitions“**部分。这个transitions部分包含了Map结构中原始转换指针(Raw Transition Pointer)指向的信息。
在 V8 中,Map 的转换使用名为 TransitionsAccessor 的组件。这是一个辅助类,它封装了 Map 在其 Map::kTransitionsOrPrototypeInfo 字段(也称为我们之前提到的Raw Transition Pointer)中存储与其他 Map 转换的各种方式。该指针指向一个名为 TransitionArray 的对象,它本身也是一个 FixedArray ,用于保存 Map 属性更改的转换信息。
回顾红色高亮部分,我们可以看到该转换数组(transition array)中只有一个转换(transition)。在该数组中,我们可以看到transitions #1详细描述了当y属性添加到对象时没发生的transition。如果添加了y属性,他会指示Map更新为存储在0x2b2508207aa1的Map,该Map与我们当前的Map匹配!如果存在另一个transition,例如,将z属性添加到x而不是y属性,那么该transition array中将会有2个元素,分别指向该对象shape对应的Map。
那么,如果我们删除一个属性,transition tree会发生什么变化呢?在这种情况下,V8每次删除属性时都会创建一个新的Map,这其中存在一些微妙之处,我们知道,Map在内存使用方面相对昂贵,因此,当属性删除到一定程度时,继承(inheriting)和维护transition tree的成本会越来越高,速度也会越来越慢。如果删除对象的最后一个属性,Map只会调整其back pointer,使其返回到之前的Map,而不会创建一个新的Map。但是,如果我们删除对象的中间属性(middle property)会发生什么呢?在这种情况下,每当我们添加过多属性或删除非最后一个元素时,V8都会放弃维护transition tree,并切换到一种称为字典模式(dictionary mode)的较慢模式。
那么,什么是dictionary mode呢?既然我们已经了解了 V8 如何使用HiddenClass来跟踪对象的shape,现在我们可以回过头来,进一步了解这些Properties和Elements在 V8 中是如何存储和处理的。
Properties
Elements
Viewing Chrome Objects In-Memory
Pointer Tagging
Pointer Compression
参考
JavaScript引擎的一般流程 https://jhalon.github.io/chrome-browser-exploitation-1/ ↩︎
JavaScript: The Good Parts https://www.youtube.com/watch?v=5nmpokoRaZI ↩︎
Understanding V8’s Bytecode https://medium.com/dailyjs/understanding-v8s-bytecode-317d46c94775 ↩︎
Firing up the Ignition Interpreter https://v8.dev/blog/ignition-interpreter ↩︎