Chrome 学习:V8和JavaScript内部机制介绍
前言
这篇文章主要整理自 Jack Halon 的 Chrome Browser Exploitation, Part 1: Introduction to V8 and JavaScript Internals,目标不是把 V8 的所有实现细节一次讲完,而是先建立一套够用的心智模型。
如果你是从浏览器漏洞利用的角度学习 V8,那么这一篇最重要。因为后面很多 type confusion、数组越界、JIT 假设错误,最后都会落回这几个基础问题:
- JavaScript 引擎是怎么执行代码的?
- V8 在内存里怎么表示一个对象?
Map、Properties、Elements分别是什么?- 为什么指针标记和指针压缩会让调试结果看起来“不对劲”?
本文以“经典 V8 学习模型”为主,重点是帮助理解对象模型和漏洞分析语境下的核心概念,而不是逐行追踪最新版本 V8 的全部实现细节。
V8 是什么?
JavaScript 代码本身不能直接在浏览器里“凭空执行”,它需要一个 JavaScript 引擎。V8 就是 Google Chrome 使用的 JavaScript 引擎之一。
常见的 JavaScript 引擎包括:
- V8:Google 的 JavaScript / WebAssembly 引擎,用于 Chrome。
- SpiderMonkey:Mozilla 的引擎,用于 Firefox。
- ChakraCore:微软曾使用过的 JavaScript 引擎。
- JavaScriptCore:Apple 在 Safari / WebKit 中使用的引擎。
它们的实现方式并不完全相同,但都要遵守 ECMAScript 规范。也就是说,浏览器内部怎么优化可以不同,但 JavaScript 语义最终必须一致。
先看整体流程:JavaScript 引擎是怎么工作的
先别急着扎进对象布局。先把整条执行链路记住,后面很多细节才有落点。
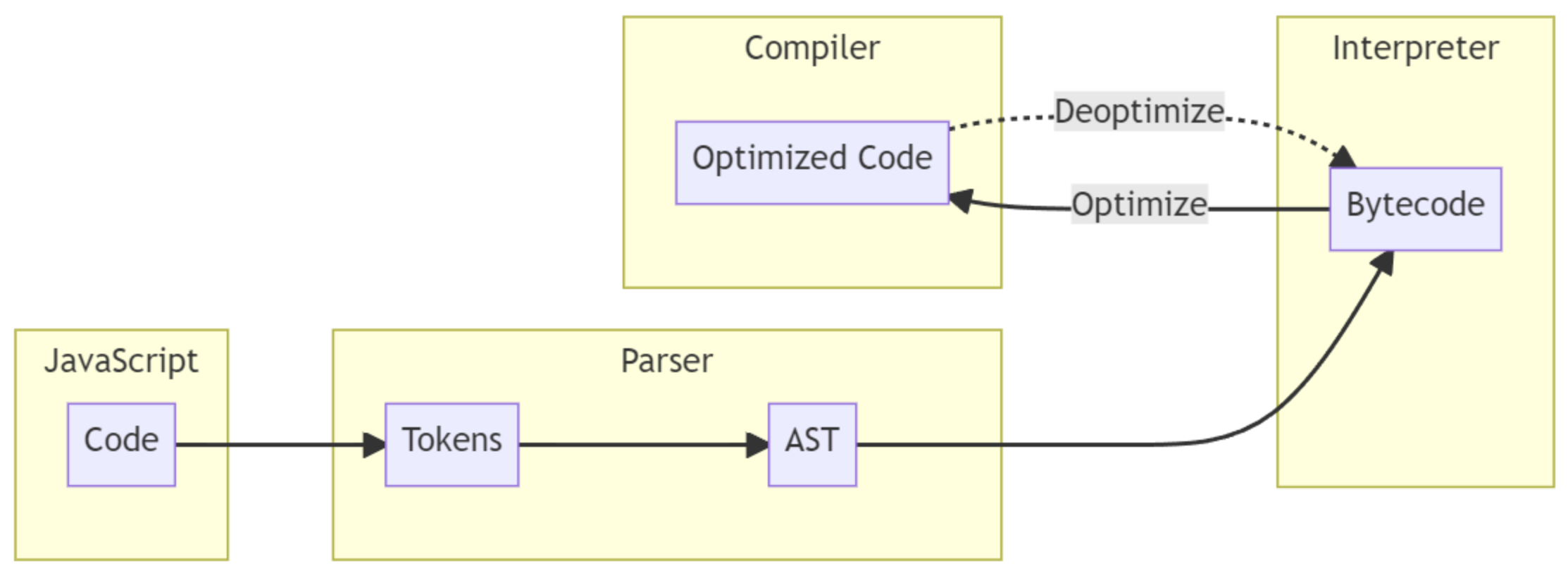
可以把 JavaScript 引擎的执行过程粗略理解成 3 步:
-
Parser(解析器)
负责把源码拆成 token,再进一步组织成 AST。 -
Interpreter(解释器)
负责把 AST 转成字节码,并执行字节码。 -
Compiler(编译器)
负责观察热点代码,并把它进一步编译成优化后的机器码。
1. Parser:从源码到 AST
以这行代码为例:
1 | var num = 42; |
解析器首先会把它切成 token,例如:
1 | var, num, =, 42 |
并分别标记类型:
1 | Keyword, Identifier, Operator, Number |
之后再把这些 token 组装成 AST。AST 可以理解成“代码的结构化语法树”,它不是源码文本,而是更适合引擎继续处理的数据结构。
2. Interpreter:从 AST 到字节码
当 AST 生成之后,解释器会继续把它转成字节码。对于 V8 来说,这部分由 Ignition 完成。
例如 var num = 42; 可能会生成类似下面这样的字节码:
1 | LdaConstant [0] |
先不用记住每条指令的含义。这里真正重要的是:
JavaScript 在 V8 里不会直接变成 CPU 机器码,而是会先变成字节码,再交给解释器执行。
3. Compiler:热点代码会被进一步优化
解释执行足够灵活,但也会有额外开销。于是当某些函数足够“热”时,编译器就会介入。
在经典 V8 流水线里,你可以把角色理解成:
Ignition:解释器,负责生成和执行字节码。Sparkplug:基线编译器,快速把字节码变成机器码。TurboFan:优化编译器,负责更激进的优化。

这一篇不深入讲 JIT 优化细节,但有一件事需要先记住:
V8 想要“快”,就必须知道对象长什么样、属性放在哪、数组里装的是什么类型。
这正是后面 Map、Properties、Elements 这些结构存在的原因。
为什么 JavaScript 的“动态性”会给引擎带来困难
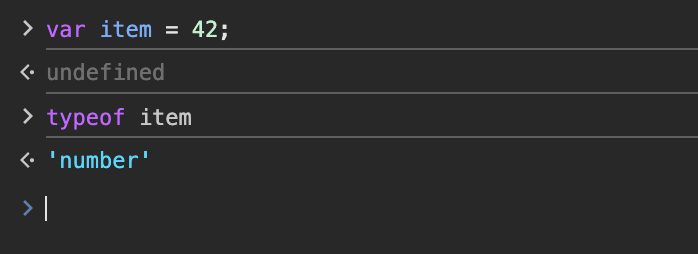
JavaScript 是动态类型语言。类型不是绑定在变量名上的,而是绑定在运行时值上的。
例如:
1 | var item = 42; |
然后你完全可以在运行时把它改成字符串:
1 | item = "Hello!"; |
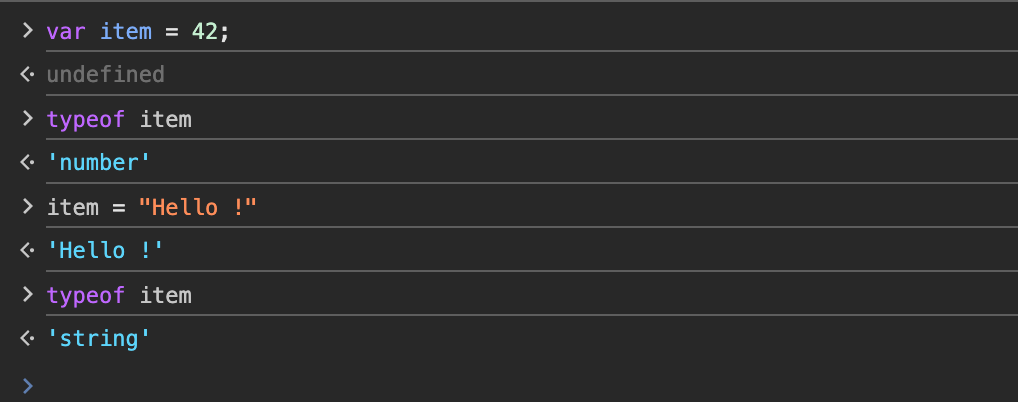
这在 JavaScript 里很正常,但对 V8 这种用 C++ 写的引擎来说就不那么轻松了。因为它需要在运行时持续判断:
- 这个值到底是对象、整数、浮点数还是字符串?
- 这个对象当前有哪些属性?
- 这些属性存在哪?
- 这个数组里装的是整数、double,还是对象引用?
如果这些判断和假设出了错,性能会下降;如果优化阶段基于错误假设生成了机器码,甚至可能演变成安全漏洞。
从漏洞分析角度看,很多类型混淆问题,本质上就是“引擎对对象布局或值类型的理解和真实情况不一致”。
JavaScript 对象在 V8 里是怎么表示的
要理解这一点,先从 JavaScript 世界的“对象”说起。
在语言层面,对象本质上是一组键值对。它可以是普通对象、数组、函数、布尔包装对象、正则对象等等。
每个属性还带有一组属性特性,比如:
valuewritableenumerableconfigurable
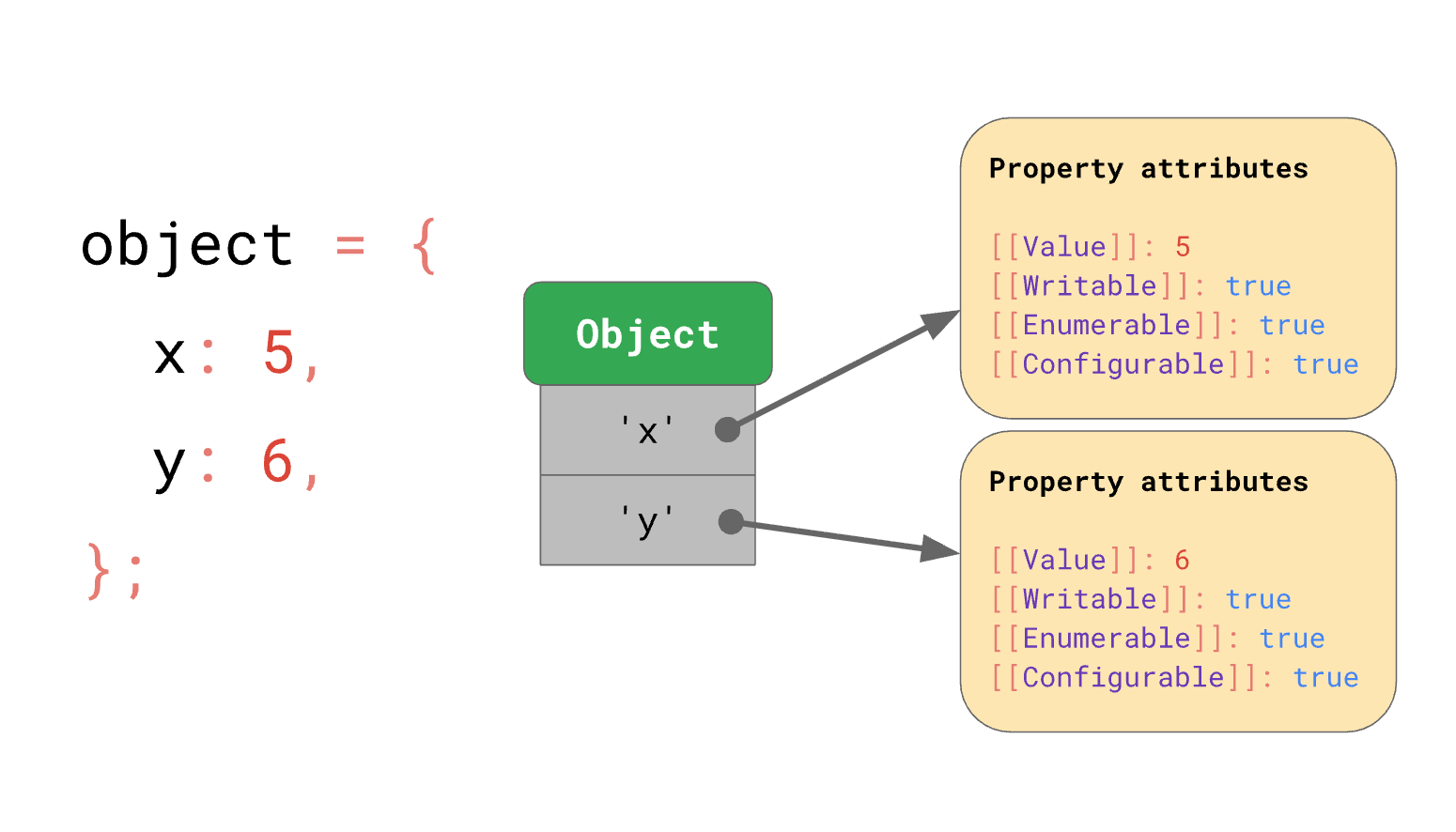
但站在 V8 内部看,一个 JavaScript 对象不会直接以“高层语义”形式存在。每当创建一个对象时,V8 都会在堆上分配一个 JSObject。
一个简化后的 JSObject 可以先记成这样:
1 | JSObject { |
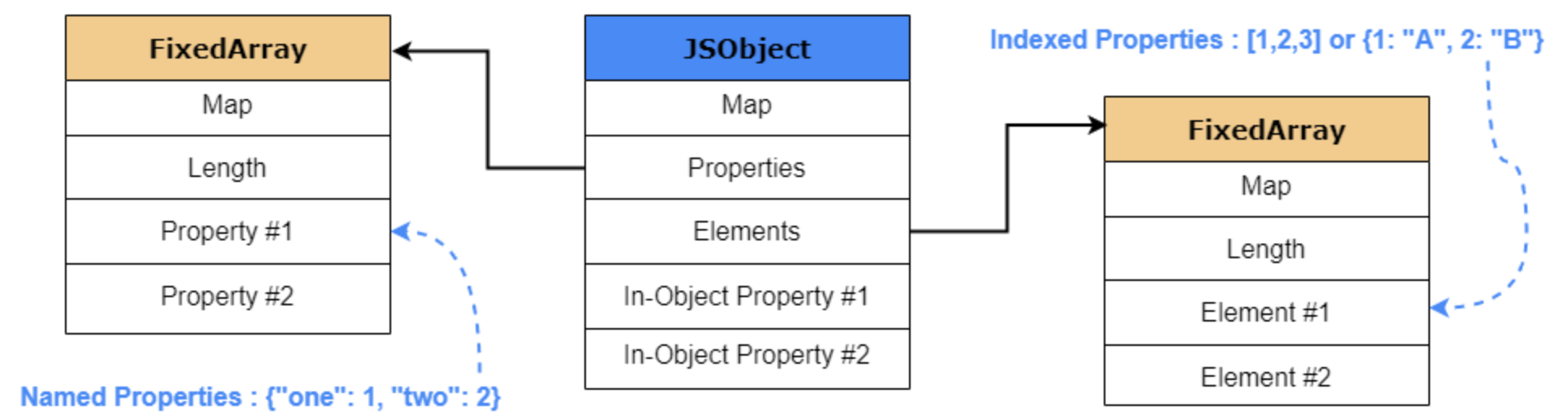
先记住一句最重要的话:
Map决定“属性在哪”,Properties/Elements决定“值放在哪”。
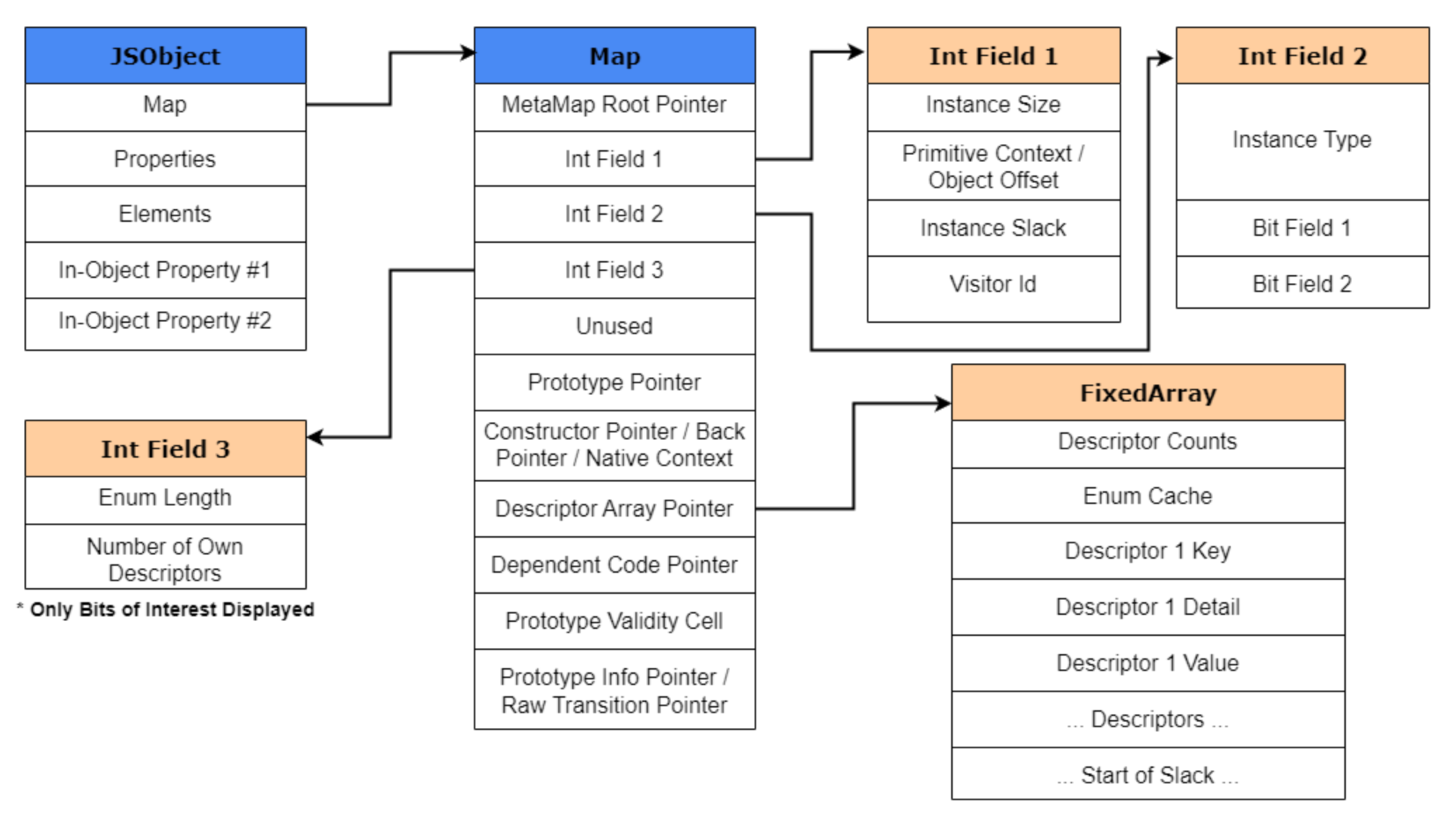
Map 是什么:V8 里的 Hidden Class
在 V8 中,Map 不是 ECMAScript 里的 Map 对象,而是另一种内部数据结构。它也常被称为:
- Hidden Class
- Shape
它的职责可以粗略概括为:
描述一个对象当前的结构和布局。
Map 里记录了什么
一个 Map 通常会记录这些信息:
- 对象类型,例如
JSObject、JSArray、HeapNumber - 对象大小
- 对象有多少个 in-object 属性槽
- 命名属性的布局信息
- 数组元素的 kind
- 原型相关信息
所以如果把它类比成静态语言中的概念,Map 更接近于:
1 | “这个对象的内存布局说明书” |
而不是“属性值仓库”本身。
为什么 Map 存的是偏移,不是值
假设你有两个对象:
1 | var obj1 = {x: 1, y: 2}; |
它们的值不同,但结构相同:
- 都有
x - 都有
y - 顺序也相同
这就意味着,它们可以共享同一个 Map。如果每个对象都重复存一份完整的“属性名到属性位置”的描述,不仅浪费内存,也会拖慢访问速度。
所以 V8 的做法是:
Map只记录属性名及其偏移- 具体值存在对象本身或独立的 backing store 中
也就是说,Map 更像这样:
1 | x -> offset 0 |
而不是:
1 | x -> 1 |
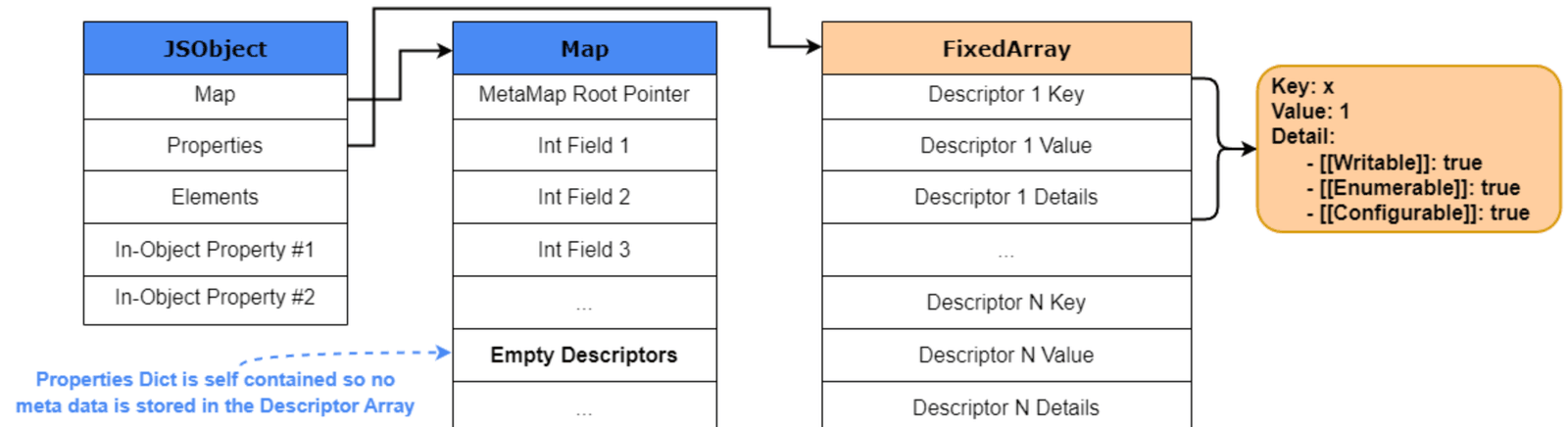
DescriptorArray:命名属性布局的关键
Map 之所以能描述对象形状,关键就在于它关联的 DescriptorArray。
可以把 DescriptorArray 理解成:
“属性名 -> 属性位置/属性描述” 的元数据表
它里面保存的不是最终值,而是类似下面这种信息:
1 | x -> offset 0 |
于是 V8 就知道:对于所有共享这个 Map 的对象,x 应该去哪个槽位读,y 应该去哪个槽位读。
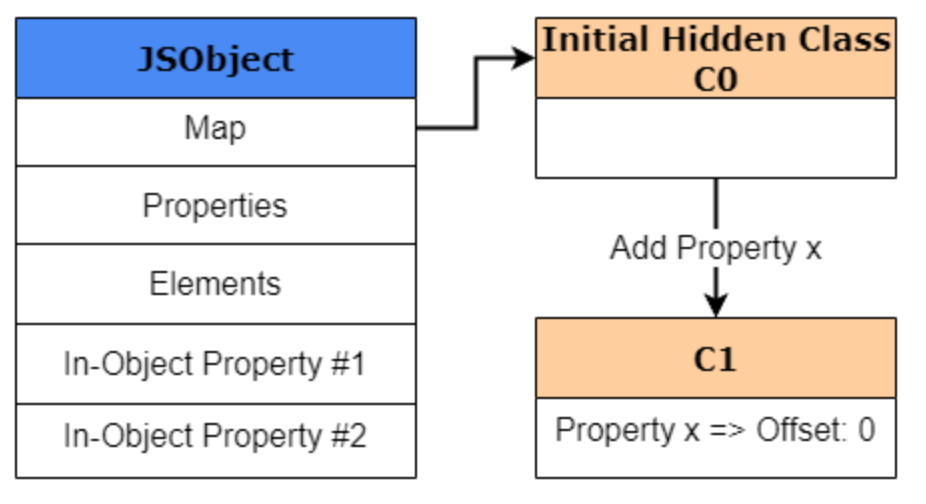
对象形状是怎么变化的:Shape Transition
JavaScript 对象不是静态的,运行时可以继续加属性:
1 | var obj1 = {}; |
V8 不会在原地“模糊修改”原有形状,而是会随着属性增加,不断让对象沿着一条 transition path 演进。
你可以把上面这个过程理解成:
1 | C0: {} |
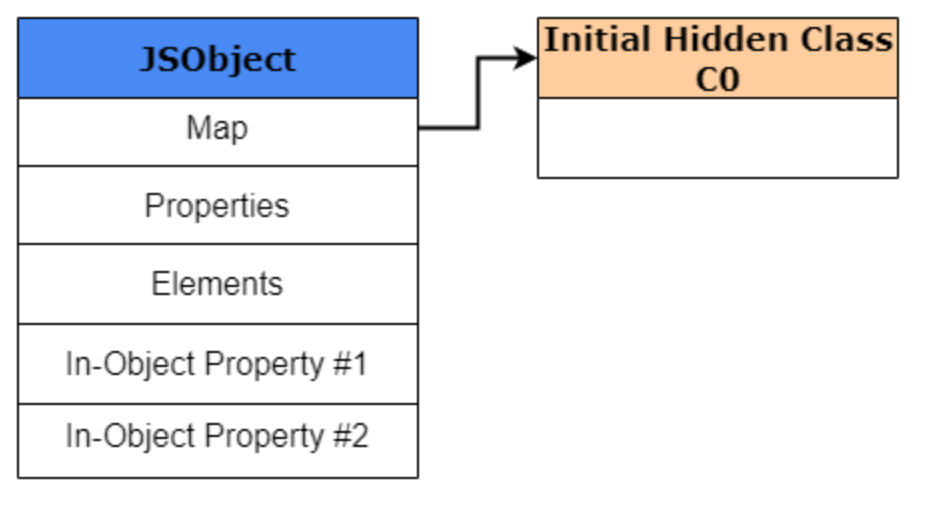
继续加 x 后,对象会从 C0 过渡到 C1:
再加 y,就会继续过渡到下一个 Map:
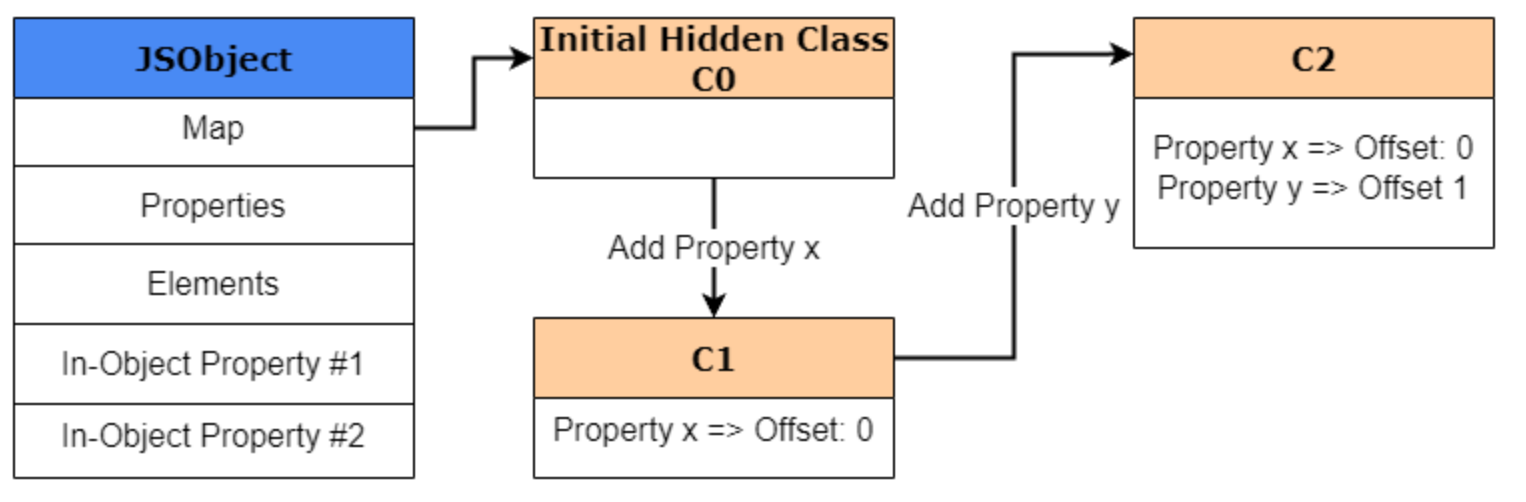
这些过渡连起来,就形成了一棵 transition tree。
属性顺序也会影响 Shape
这一点非常重要。
下面两个对象看起来只是“属性一样”,但它们的 shape 不一定相同:
1 | var a = {}; |
原因是属性添加顺序不同,transition path 也不同。
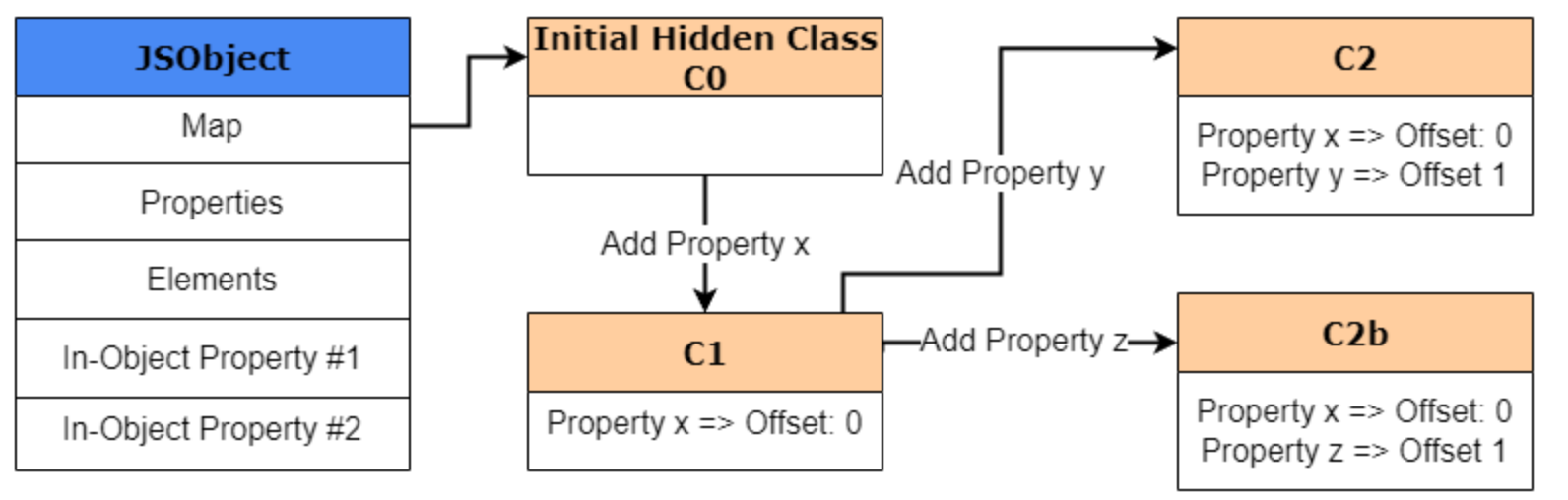
从优化角度看,这就是为什么“结构稳定、构造顺序稳定”的对象更容易被优化。
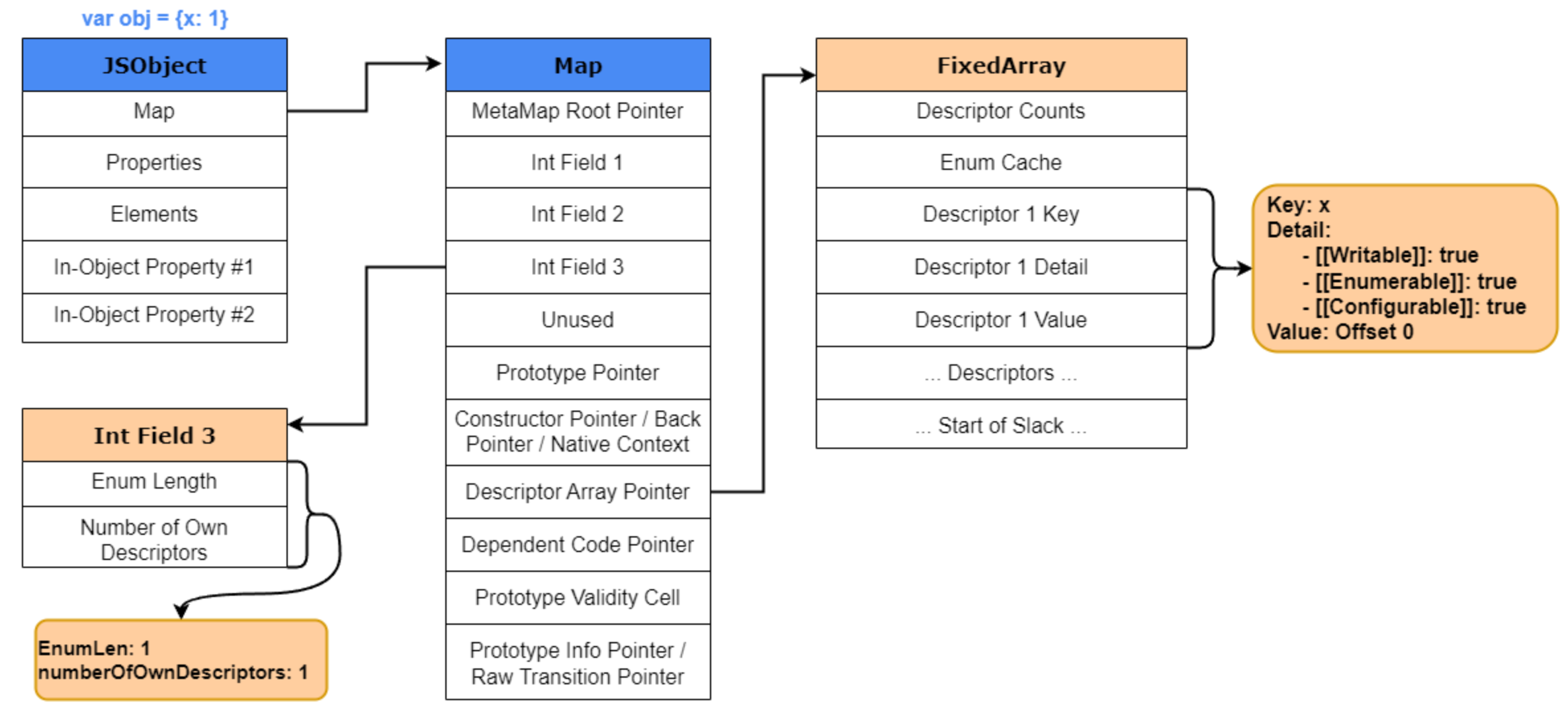
用 d8 看看 Map 到底长什么样
只讲概念很容易发虚,最好的方式还是直接看 V8 的调试输出。
先在 d8 里创建一个对象:
1 | var obj1 = {a: 1, b: 2, c: 3}; |
然后用:
1 | %DebugPrint(obj1) |
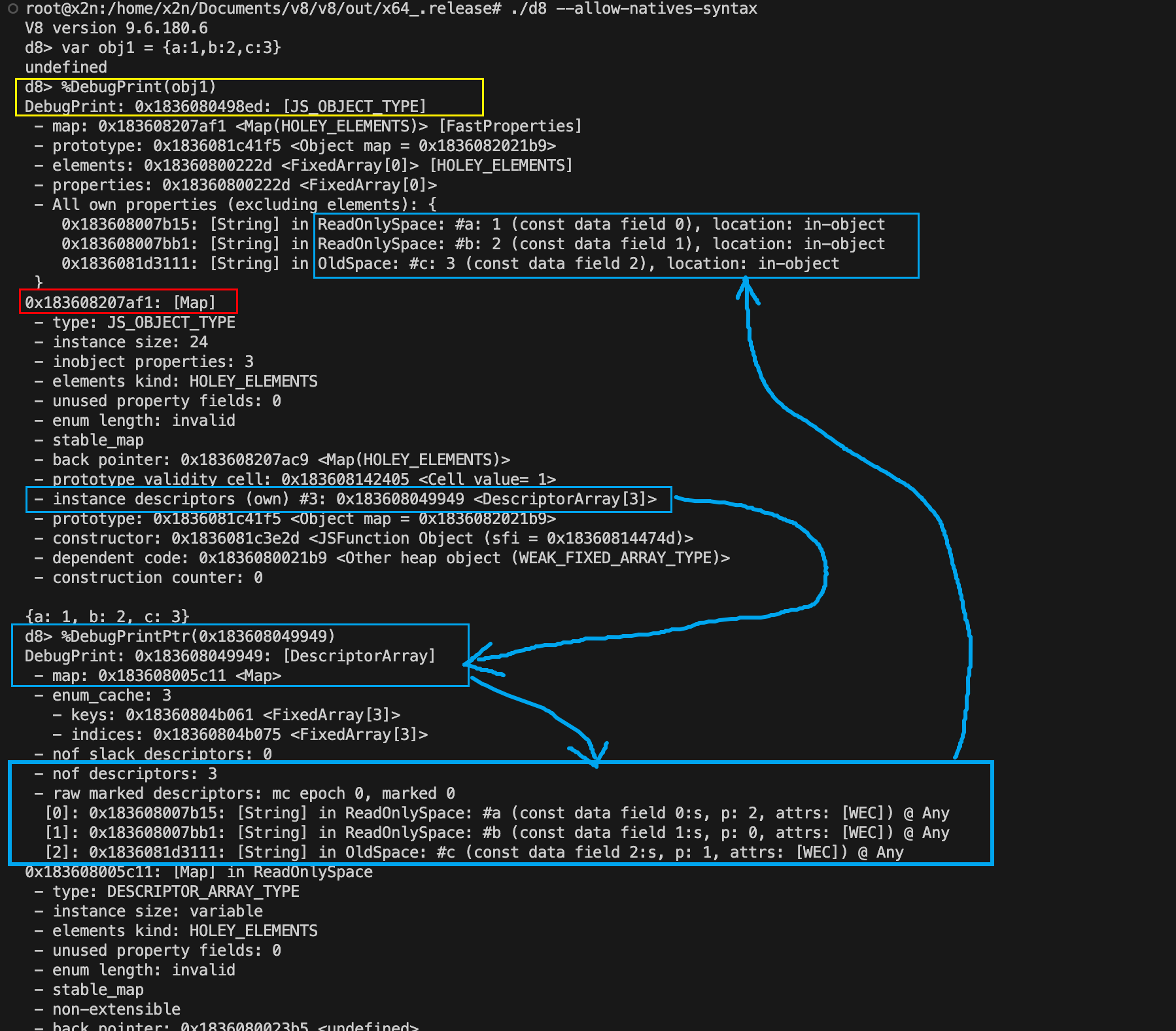
这个输出里最值得关注的几块信息是:
- 对象本身的地址
map指针instance descriptors- 各个属性的
location
你会看到:
- 对象关联了某个
Map Map里有对应的DescriptorArray- 属性可能位于
in-object
这正好和前面的理论对应上:对象负责存值,Map 负责告诉 V8 这些值该怎么解释。
多个同形对象会共享一个 Map
如果我们创建两个 shape 一样的对象:
1 | var obj1 = {x: 1, y: 2}; |
再分别 %DebugPrint(),会发现它们虽然地址不同,但会共享同一个 Map。
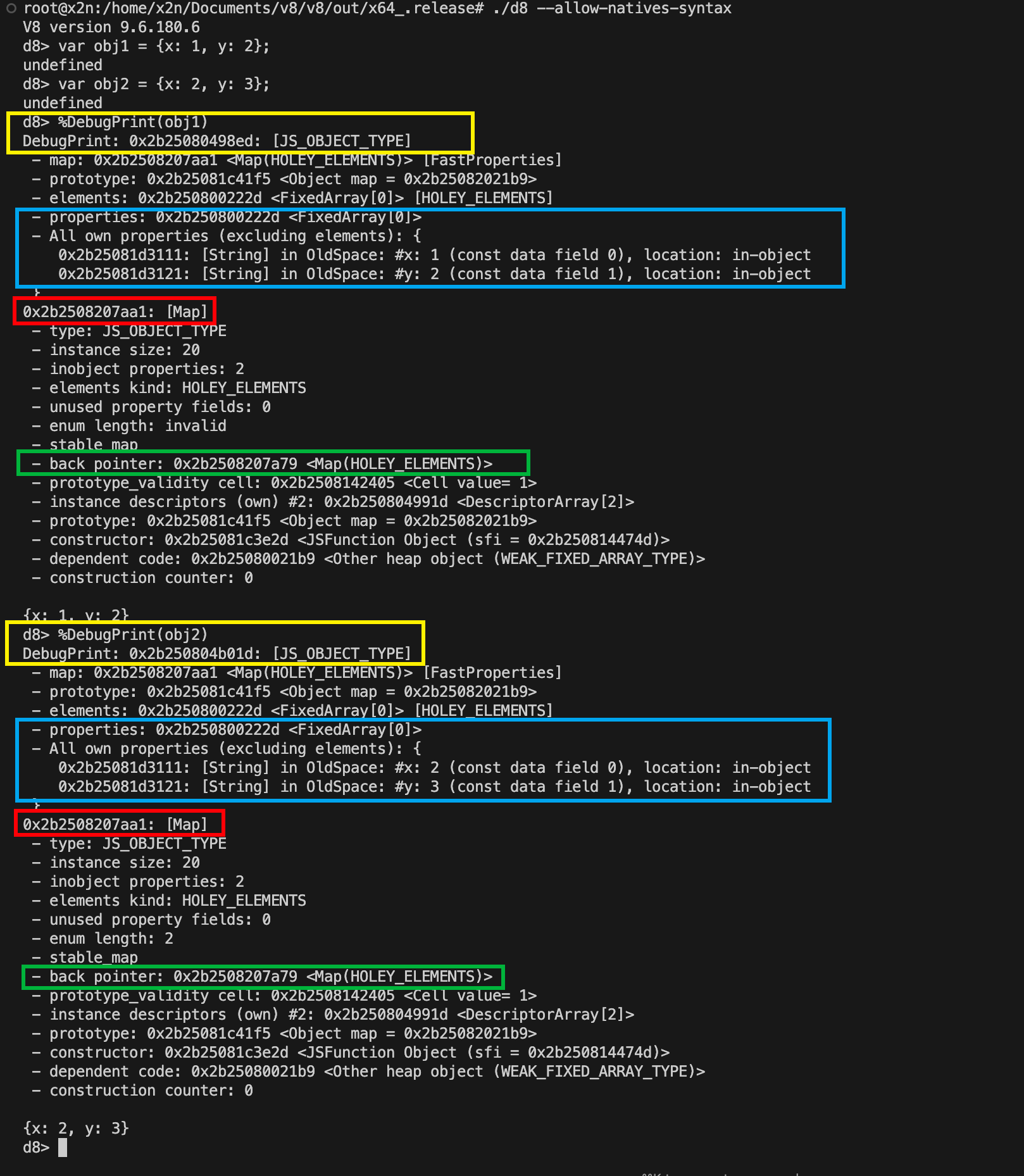
这正是 Hidden Class 优化最核心的一点:
结构相同的对象,共享同一份布局描述。
这样一来,属性访问就不需要每次都像字典那样查找字符串键,而可以更像:
1 | 先看 map |
这也是 JavaScript 引擎能把对象访问做得很快的重要原因。
back_pointer 和 transition tree
如果继续沿着 Map 里的 back_pointer 看,还能回溯到前一个 shape。
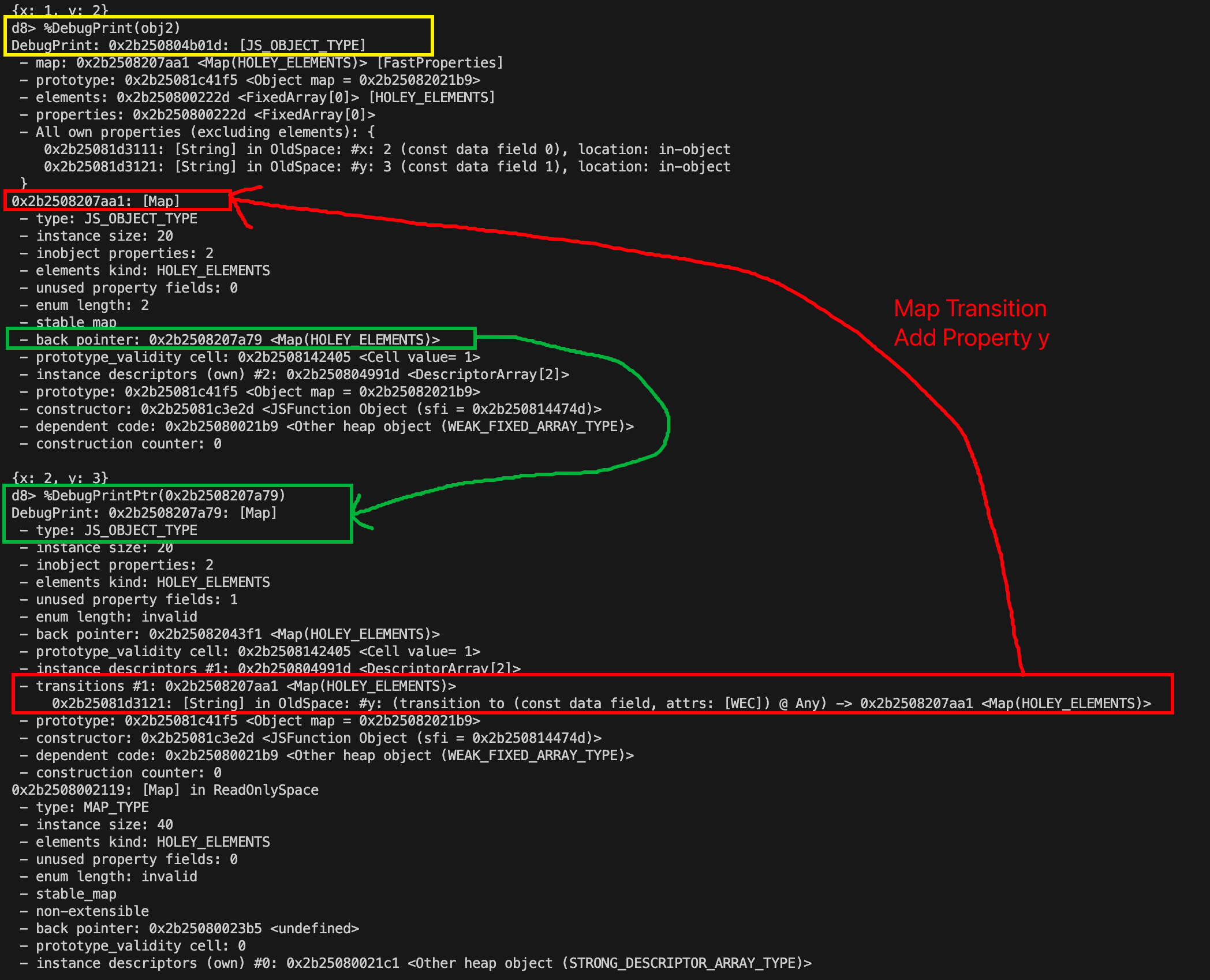
这说明 transition tree 不是抽象概念,而是真实存在于 Map 之间的链接关系。
Properties:命名属性的存储
讲完 Map,再回到对象的“值到底放哪”。
命名属性,也就是像下面这种字符串 key:
1 | obj.x |
在 V8 里通常有两种主要存法。
1. In-object properties
最理想的情况,是属性直接放在对象本体内部:
1 | obj: |
这种方式最快,因为访问时几乎没有额外间接层。
2. Properties backing store
如果对象属性变多,超出了对象初始预留的 in-object 槽位,剩余属性就会被放到 properties backing store 里。
这时访问逻辑会变成:
1 | Map 记录 offset |
Fast Properties 和 Slow Properties
V8 还会根据对象变化的频率和复杂度,区分两种模式:
-
Fast Properties
通过Map + DescriptorArray + offset来访问,适合结构稳定的对象。 -
Slow Properties
也常被叫做 dictionary mode。属性元数据不再主要依赖共享的Map,而是直接存进字典结构。
这背后的直觉也很简单:
如果一个对象老是在增删属性,继续维护漂亮的 transition tree 成本太高,不如退化成字典模式。
所以:
- 结构稳定的对象更快
- 经常增删属性的对象更容易进入慢路径
Elements:数组和整数索引属性
除了命名属性,V8 还专门把“整数索引属性”单独拿出来处理,也就是 Elements。
例如:
1 | const arr = [1, 2, 3]; |
这些就不走普通的 named properties,而是走 elements 存储。
之所以要单独拆开,是因为数组访问模式和对象属性访问模式差异很大:
- 对象属性更像字符串键查找
- 数组元素更像连续索引访问
因此 V8 会对 elements 做非常细的分类和优化。
V8 会跟踪数组的 Elements Kind
JavaScript 语言层面上,[1,2,3] 看起来只是“number 数组”。但在 V8 眼里,这还不够精细。
以这行代码为例:
1 | const array = [1, 2, 3]; |
V8 往往会把它标记为 PACKED_SMI_ELEMENTS:
SMI:小整数PACKED:数组比较紧凑,没有洞
对学习来说,先记住 3 种基本元素类别就够了:
SMI_ELEMENTS:小整数数组DOUBLE_ELEMENTS:浮点数数组ELEMENTS:对象引用、字符串等更一般的元素
Elements Kind 是按“整个数组”跟踪的
重点不是每个元素单独贴标签,而是:
V8 会给整个数组一个当前的 elements kind。
例如:
1 | const array = [1, 2, 3]; |
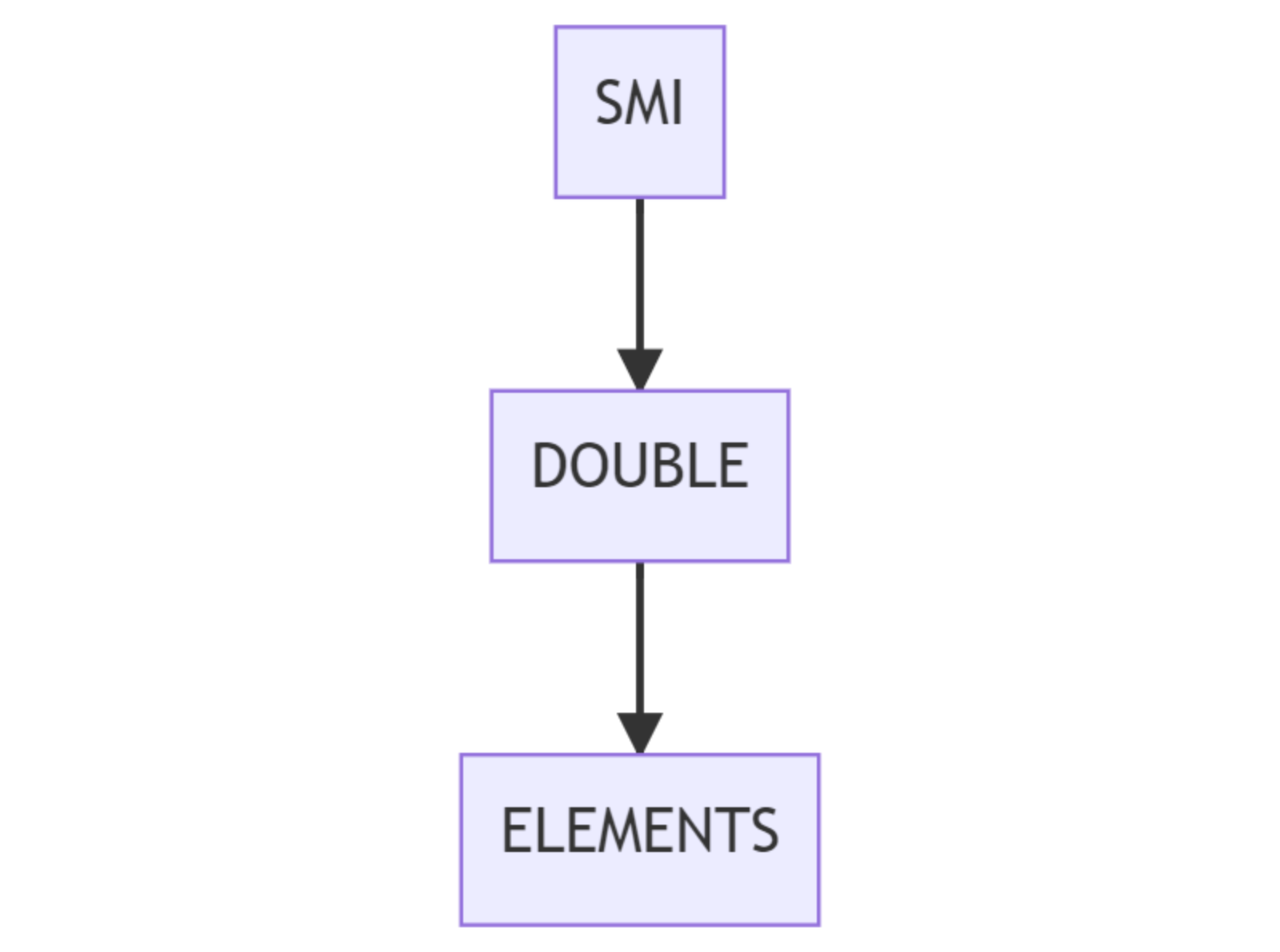
一旦数组里出现了更宽的值类型,elements kind 就会沿着一个单向路径下降。一般来说:
- 从
SMI可以降到DOUBLE - 从
DOUBLE还可以继续降到更通用的ELEMENTS
这个过程通常是不可逆的。也就是说,数组一旦“变杂”,优化空间往往只会变小,不会自动回到最理想状态。
PACKED 和 HOLEY
除了元素类型,V8 还非常在意数组里有没有“洞”。
例如:
1 | const packed_array = [1, 2, 3, 5.5, "x"]; |
PACKED 表示数组是稠密的;HOLEY 表示数组存在空洞。
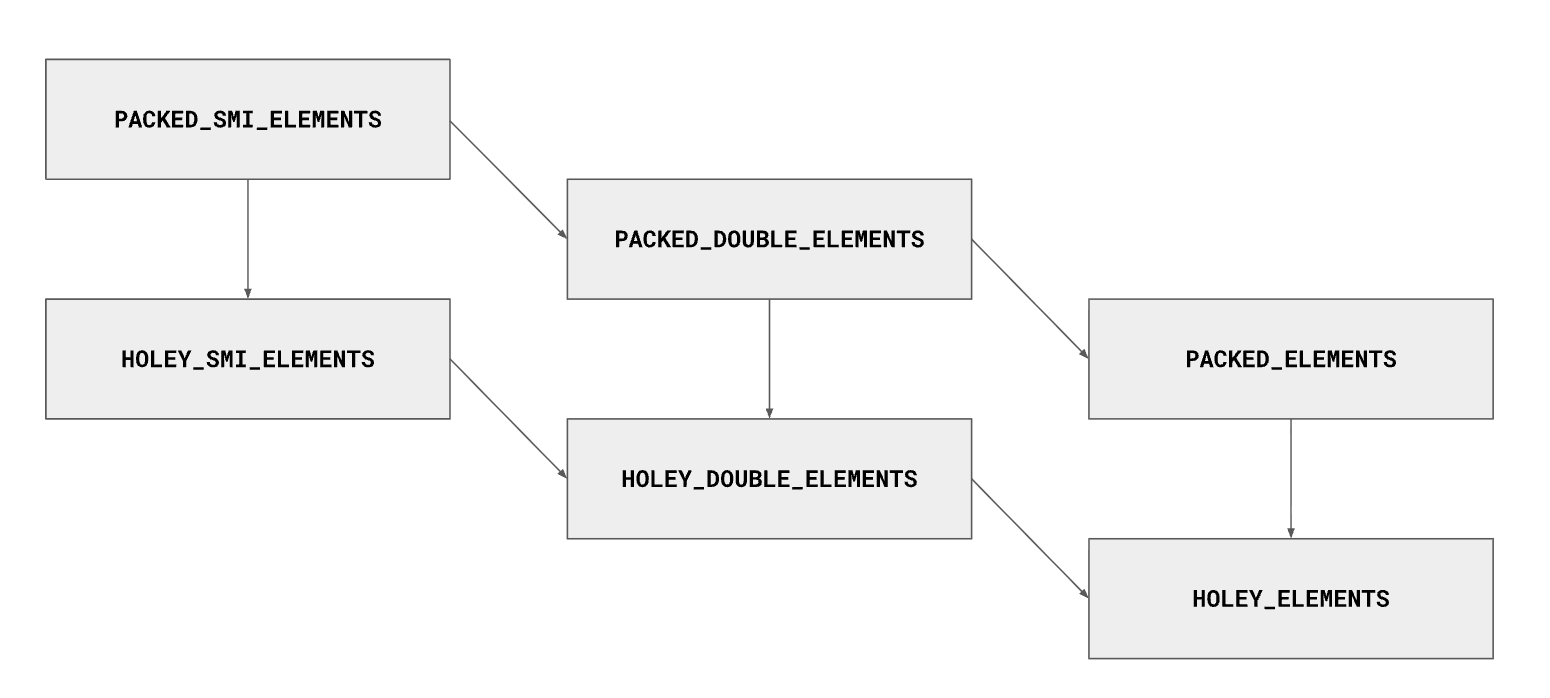
为什么这个区别重要?
因为 packed array 更容易优化。数组没有洞时,V8 可以更激进地假设:
- 索引范围更规整
- 访问路径更简单
- 检查更少
而一旦变成 holey array,很多访问都必须更保守。
Elements 也会退化成字典模式
不仅 named properties 会退化成 dictionary mode,elements 也会。
典型场景是:
- 超大稀疏数组
- 索引分布很离散
这时如果还强行维持紧凑数组存储,浪费太大,于是 V8 会用类似字典的结构来保存元素。
现在回到 exploitation 视角:为什么这些细节重要
到这里,其实可以把问题压缩成一句话:
V8 为了优化速度,需要持续记录对象的 shape、属性布局和数组元素类型。
而浏览器漏洞里常见的问题,恰恰就是这些“运行时事实”被错误理解了。
最常见的几条主线是:
-
对象 shape 被错误假设
编译器以为对象还是老的Map,但实际已经不是。 -
elements kind 被错误假设
编译器以为数组还是PACKED_SMI_ELEMENTS,但实际已经过渡到更宽的 kind。 -
属性布局解释错位
本来该按对象 A 的 layout 读,结果按对象 B 的 layout 去读。 -
字典模式 / 快模式切换处理出错
某些优化假设对象仍处于快模式,实际却已经退化。
这就是很多 type confusion 的底层背景。
在内存里看对象:为什么调试输出会让人困惑
学到这里,你已经知道:
- 对象在堆上
- 对象里有
map / properties / elements - 小整数和对象引用不一定按最直观的方式存
于是接下来就可以进入一个非常容易让初学者卡住的部分:为什么在调试器里看到的地址和 DebugPrint 输出对不上?
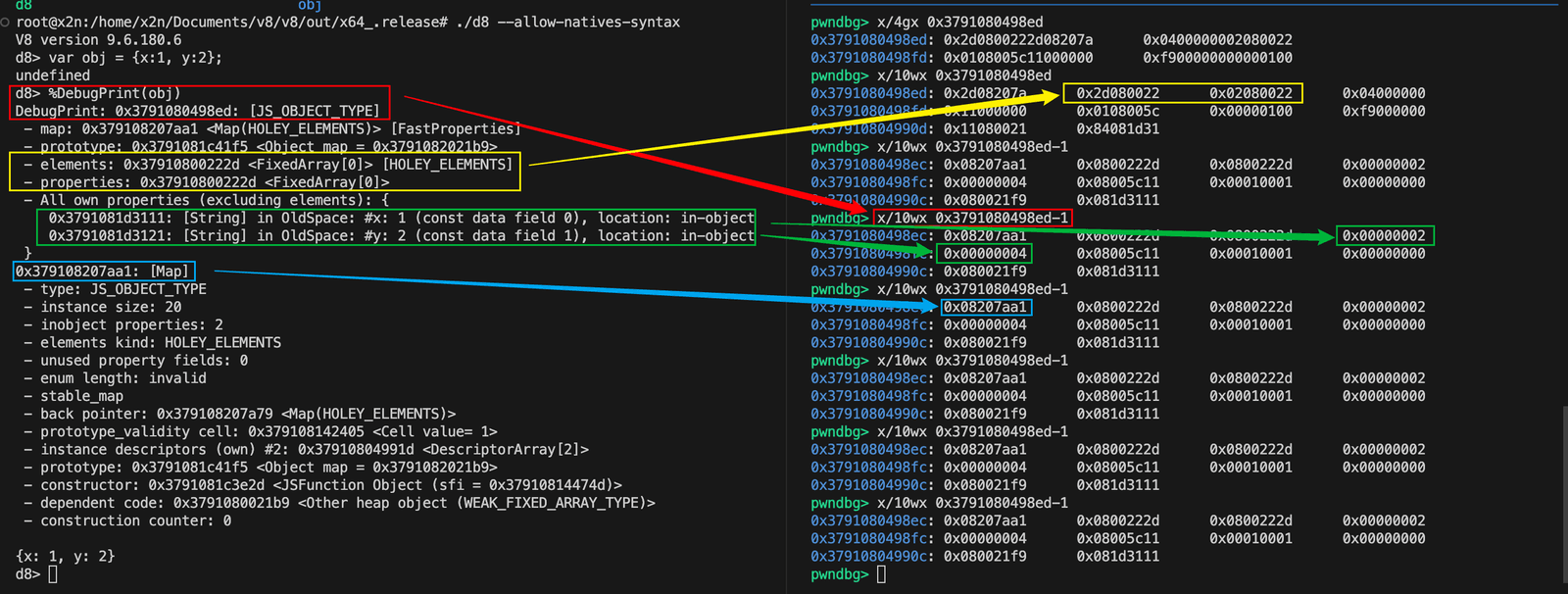
先看一个 d8 例子:
1 | var obj = {x: 1, y: 2}; |
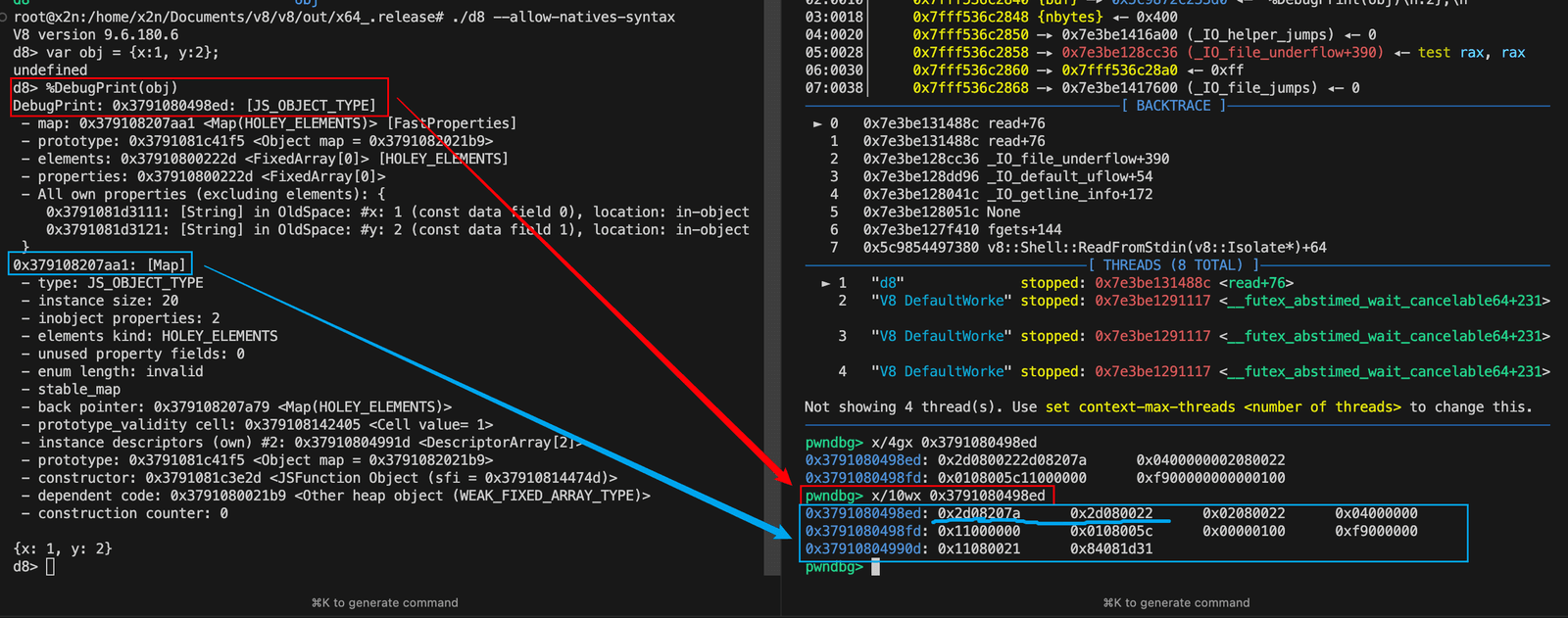
如果你再用调试器直接去读这块内存,第一眼往往会怀疑:
- 地址是不是错了?
- 指针是不是坏了?
- 为什么 map 指针看起来不像 map 指针?
答案通常不是“你看错了”,而是 V8 的两种优化一起生效了:
- pointer tagging
- pointer compression
Pointer Tagging
V8 不是把所有值都老老实实地当成完整堆对象来处理。特别是对小整数这类高频值,如果每次都专门分配一个堆对象,成本太高。
于是它会把一部分值以内联的形式编码进去。但这样立刻带来一个问题:
眼前这个 machine word,到底是堆对象指针,还是一个被编码过的立即值?
这就是 pointer tagging 要解决的事。
可以怎样理解它
一个简化理解是:
- 某些低位 bit 被拿来当“标签”
- 标签决定这个值是对象指针还是 SMI
在经典 V8 调试语境里,常见的理解方式是:
1 | Pointer: ... ... ... ... (w1) |
也就是说:
- 低位用于区分“这是指针还是 SMI”
- 对象指针在真正解引用前,需要先去掉 tag
原文里的 WinDBG/GDB 场景之所以看着“差一位”,本质就在这里。
为什么 SMI 在内存里看起来像“翻倍”
如果你在调试器里看到:
- 逻辑上的
1 - 内存里却像
2
不要立刻怀疑对象坏了。很多时候,这是因为 SMI 的编码方式导致它看起来像被左移/翻倍过。
这也是为什么直接肉眼看内存时,很容易误判。
结合调试图来看
原文的调试过程里,去掉低位 tag 之后,地址就变得合理了。
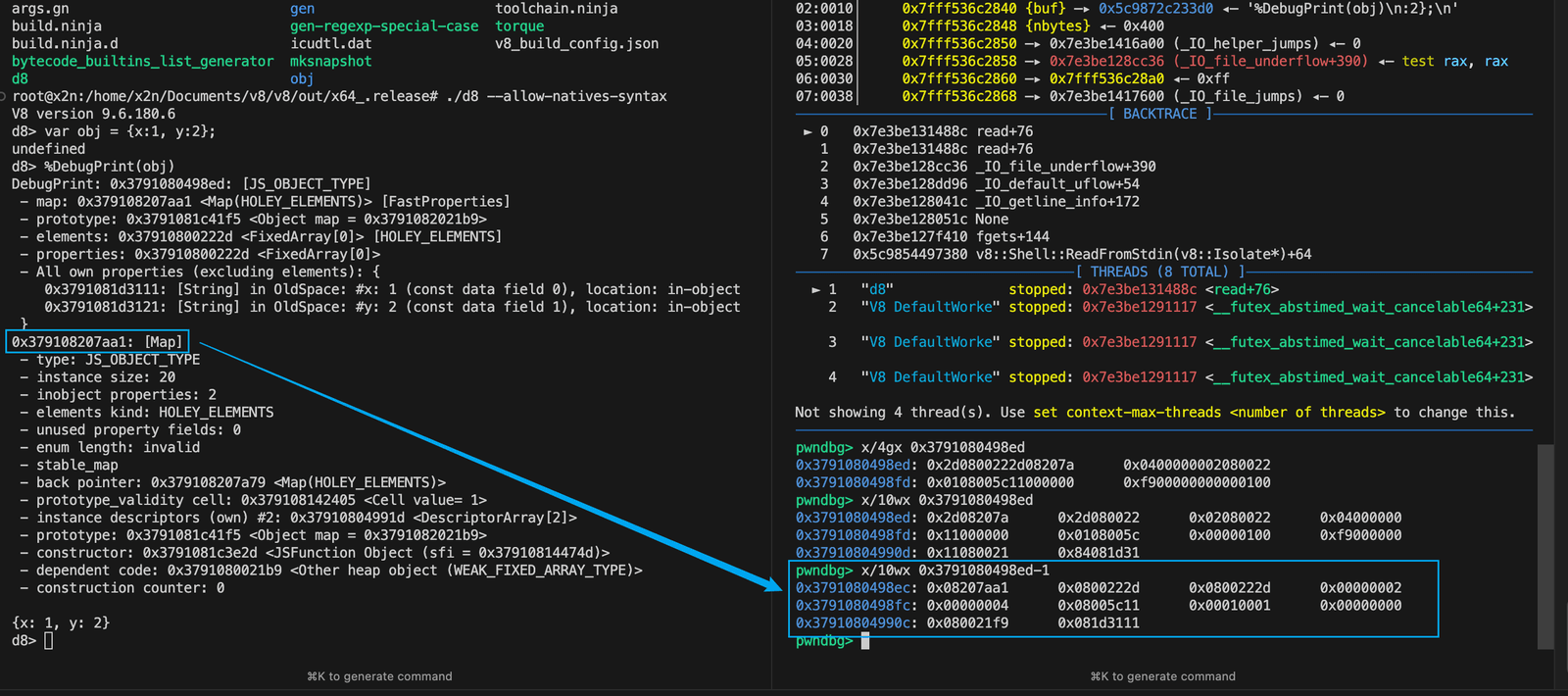
你文中后来补的这张图也很好,正好说明了“真正该对照的是去掉 tag 后的地址内容”。
Pointer Compression
接下来还有第二层优化:pointer compression。
它利用了一个非常现实的事实:
同一个 isolate / heap 里的对象,地址通常彼此很接近。
既然高位经常相同,那就没必要每个指针都完整存 64 位。
于是 V8 会:
- 在内存里只保存压缩后的低位部分
- 把高位基址放在专门的寄存器或根基址里
- 真正访问时再把两部分拼回完整地址
这就是为什么你有时会看到:
DebugPrint里是完整地址- 内存转储里只有“半截看起来能对上的指针”
这不是坏数据,而是压缩指针的正常表现。
到这里,应该把什么记住
如果你只带走几句话,我建议记住这几条:
- JavaScript 引擎不是只会“解释执行”,现代 V8 会经过解释、基线编译和优化编译多个阶段。
- V8 想优化对象访问,就必须记录对象的 shape,这就是
Map/ Hidden Class 的意义。 Map存布局,Properties和Elements存实际值。- 结构相同的对象会共享
Map,结构变化会触发 shape transition。 - 数组不仅有值,还有
elements kind,比如SMI、DOUBLE、PACKED、HOLEY。 - 调试内存时看到“地址不对劲”,优先考虑 pointer tagging 和 pointer compression,而不是先怀疑对象损坏。
总结
这篇文章其实是在给后面的 JIT 和漏洞利用内容打地基。
如果不先理解:
- 对象在 V8 里长什么样
Map怎么描述布局Properties/Elements怎么分工- 数组为什么会有不同的 elements kind
- 指针为什么会被标记和压缩
那么后面看 type confusion、越界访问、错误优化时就很容易失去方向。
所以在我看来,这一篇最重要的收获不是记住所有结构名,而是建立这样一个直觉:
V8 的很多优化,本质上都建立在“对象结构稳定、值类型可预测”这个前提上;而浏览器漏洞,恰恰经常发生在这个前提失效、却仍被错误相信的时候。
下一篇再回到编译器流水线,就会更容易理解 Ignition、Sparkplug 和 TurboFan 到底在优化什么。