Chrome 学习:Ignition、Sparkplug 和 TurboFan JIT 编译
前言
这篇笔记主要整理自 Jack Halon 的文章 Chrome Browser Exploitation, Part 2: Introduction to Ignition, Sparkplug and JIT Compilation via TurboFan,并结合 Chromium/V8 官方文档做了补充。
如果还没看过上一篇 Chrome Browser Exploitation, Part 1: Introduction to V8 and JavaScript Internals,建议先看。因为这篇默认读者已经理解了对象布局、Map/Shape、指针标记、指针压缩、内联缓存(IC)这些基础概念。
版本说明
本文重点整理的是经典的
Ignition -> Sparkplug -> TurboFan这条学习主线,它非常适合理解旧版 V8 的 JIT 行为,也很适合阅读浏览器利用相关文章。但如果把它当成 2026 年 V8 的完整现状就不准确了。V8 官方在 2023 年 12 月 5 日发布的 Maglev 文章里说明,Chrome M117 已经引入了 Maglev;又在 2025 年 3 月 25 日发布的 Land ahoy: leaving the Sea of Nodes 中说明,TurboFan 的 JavaScript 后端已经大量迁移到 Turboshaft。也就是说,本文更适合建立“漏洞分析语境下的经典 V8 心智模型”,而不是追求当前实现的逐行对应。
本文重点回答 4 个问题:
- JavaScript 代码在 V8 里到底是怎么一步步执行起来的?
- Ignition、Sparkplug 和 TurboFan 各自负责什么?
- 反馈向量、类型守卫、反优化(deopt,deoptimization)这些概念为什么重要?
- 这些优化为什么会演变成 JIT 漏洞?
先记住整条主线
如果只想先抓住主干,可以先记住下面这条链路:
1 | JavaScript 源码 |
从漏洞分析角度看,最关键的不是“它会不会优化”,而是:
- 它根据什么信息做优化。
- 它做了哪些推测。
- 它如何验证这些推测。
- 推测失效时如何回退。
这几件事一旦有一处做错,就可能出现类型混淆、越界访问或者错误的机器码生成。
Chrome 安全模型
在看编译器之前,先把浏览器的大框架放在脑子里。V8 并不是孤立运行的,它是嵌在 Chrome/Blink 里的。而浏览器利用往往不是“拿下一个 JavaScript bug 就等于拿下整个系统”,原因就在于 Chrome 的进程模型和沙箱。
多进程 + 沙箱
Chromium 采用多进程架构,把不同职责拆到不同进程里。最核心的两个角色是:
browser process:主进程,负责 UI、资源协调、进程管理。renderer process:渲染进程,负责页面内容、Blink、V8 等。
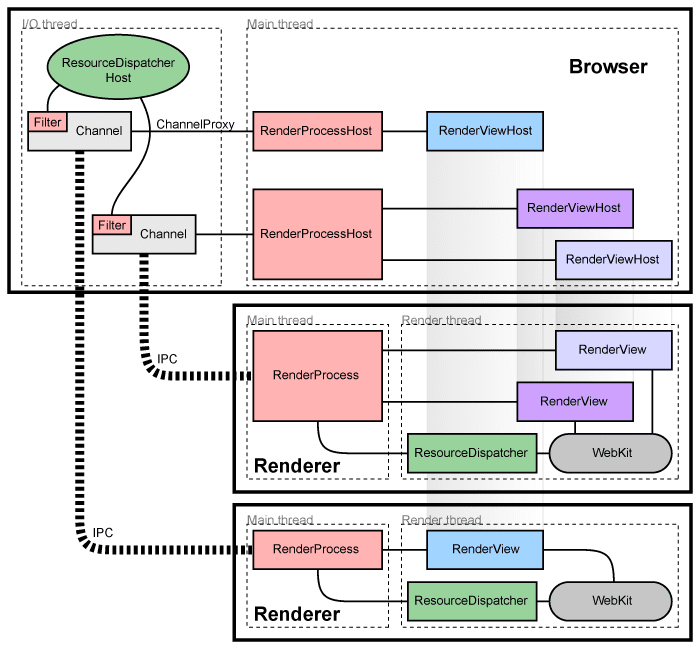
在实际运行中,你通常会看到一个主进程和多个子进程。具体是“一标签一进程”还是“多个标签共享进程”,还会受到站点隔离、进程复用等策略影响,但对于理解漏洞利用来说,抓住“渲染器和浏览器主进程是隔离的”这一点就够了。
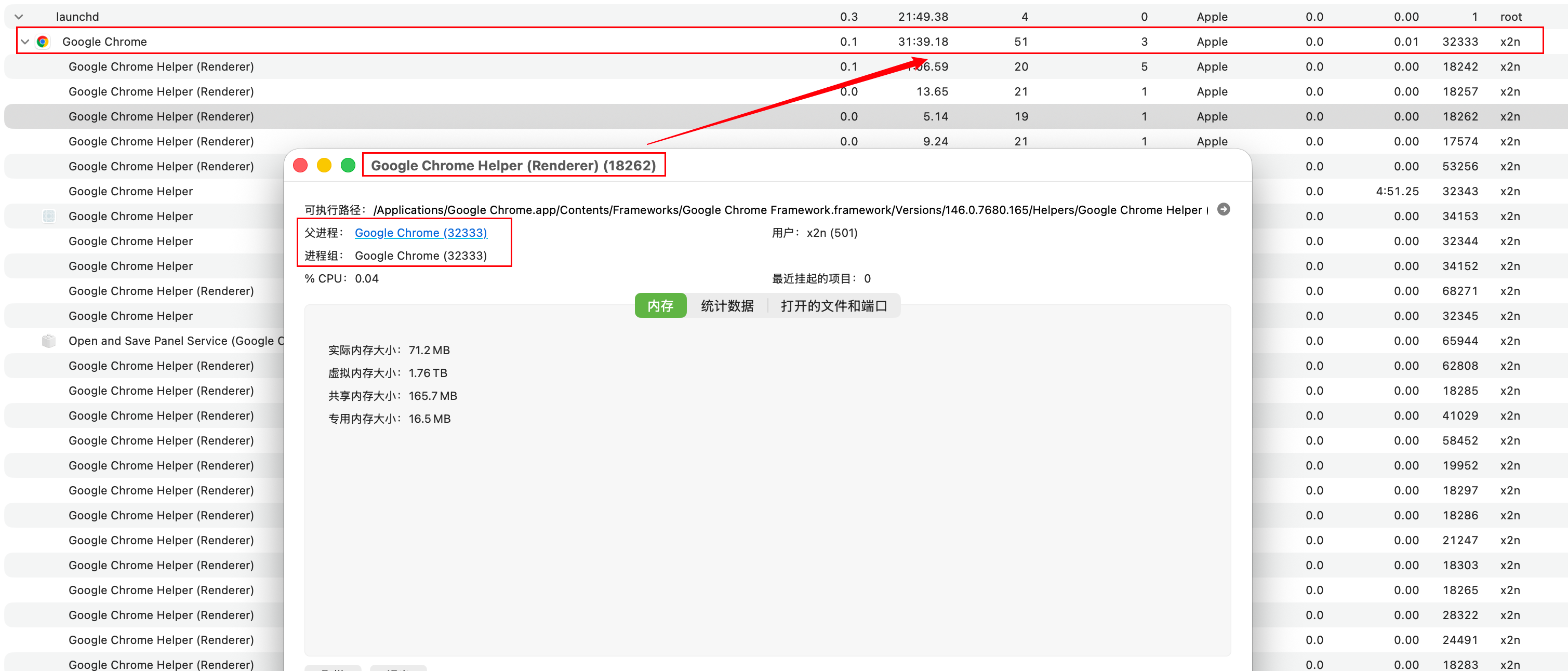
Chrome 还会进一步把渲染进程放进沙箱里,限制它对文件系统、网络、Cookie、显示输出和用户输入的直接访问。于是一个典型结论就出来了:
拿到 renderer 内的代码执行权限,并不等于拿到整个系统权限。
这也是为什么浏览器利用里经常会区分:
- renderer RCE
- sandbox escape
- full chain exploitation
V8 的 Isolate 和 Context
在 Blink 中,V8 不是“全浏览器只有一个实例”。更准确地说,V8 通过 Isolate 和 Context 来做执行环境隔离。
Isolate可以理解为一个独立的 V8 虚拟机实例,拥有自己的堆、GC、运行时状态。Context可以理解为某个全局对象对应的执行上下文,比如一个window/iframe所在的 JavaScript 世界。
通常可以把关系理解为:
- 一个线程对应一个
Isolate - 一个
Isolate里可以有多个Context
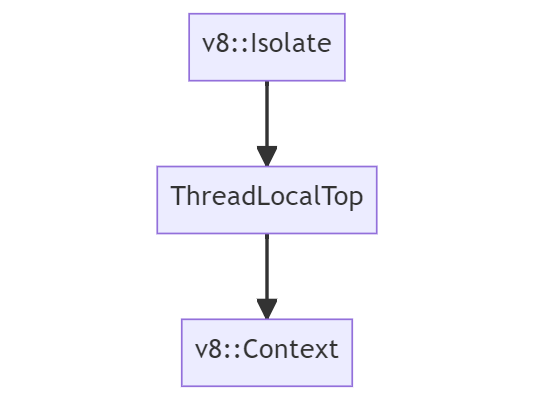
这件事对安全很重要,因为不同脚本、不同 frame 的对象不能乱串。如果进入了错误的 Context,轻则读写错对象,重则直接变成安全问题。
想继续深挖的话,可以看:
- Chromium Multi-process Architecture
- Chromium Sandbox Design
- Design of V8 Bindings
- Getting Started with Embedding V8
Ignition:V8 的字节码解释器
现在回到 V8 本身。
在经典流水线里,JavaScript 源码先被解析成 AST,然后由 BytecodeGenerator 生成字节码,再交给 Ignition 执行。

为什么 Ignition 很重要
Ignition 不只是“先跑一遍”的解释器。它至少做了 3 件后续编译阶段离不开的事:
- 把 AST 变成字节码。
- 建立函数的解释器栈帧。
- 在执行过程中收集反馈数据,供后续优化器使用。
所以从 JIT 漏洞视角看,Ignition 是整个优化链条的起点。
寄存器机器,其实是“栈上的虚拟寄存器”
Ignition 是一个基于寄存器的解释器,并带有一个累加器(accumulator)。
这里的“寄存器”并不是 CPU 的物理寄存器,而是函数栈帧里的一组槽位,也就是所谓的虚拟寄存器。每条字节码会把输入和输出写到这些槽位上,而不是直接操作真实硬件寄存器。
这也是为什么理解 Ignition 时,栈帧布局特别重要。
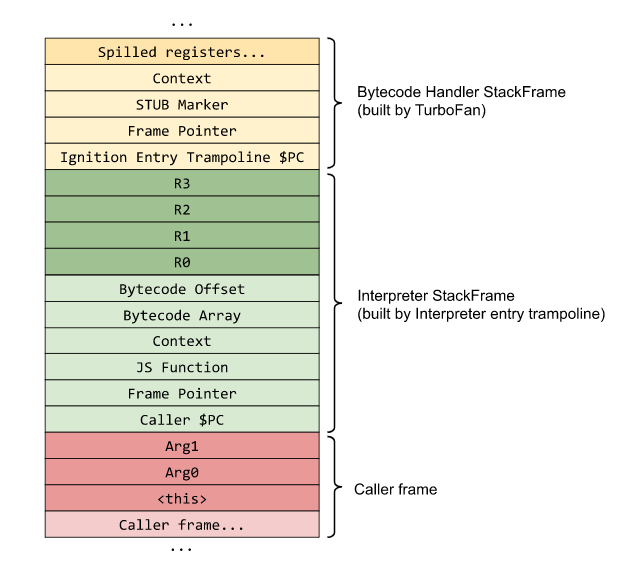
上图里可以把内容分成几块来看:
- 红色部分:函数参数。
- 绿色部分:局部变量和表达式求值需要的临时值。
- 浅绿色部分:当前
Context、调用信息、JSFunction指针等。
这里的 JSFunction 指针通常也可以理解成 closure,它会把你带到很多关键对象上,比如:
SharedFunctionInfoContextFeedbackVector
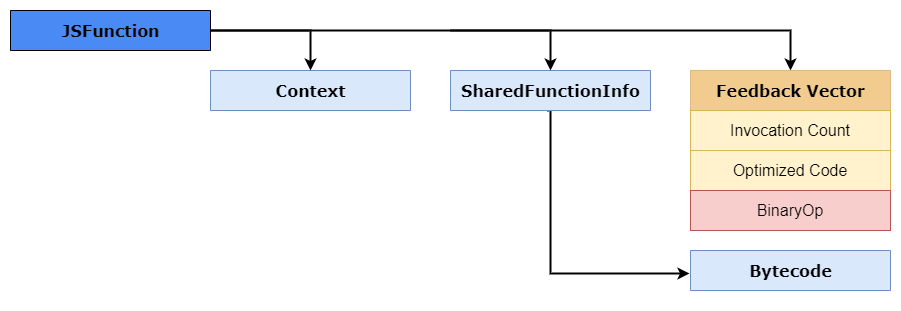
另一个容易混淆的点是:为什么图里看不到 accumulator?
因为 accumulator 不是解释器帧里的一个普通槽位。它更像解释器执行状态的一部分,由解释器配合机器寄存器和帧信息来维护。
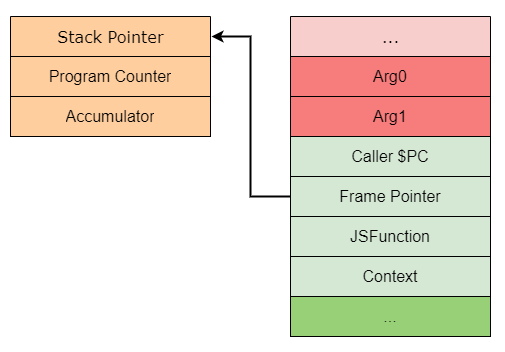
谁来创建解释器栈帧
当 JavaScript 函数第一次以解释模式执行时,入口通常会走到 InterpreterEntryTrampoline。
它负责做几件关键的事:
- 为函数建立解释器栈帧。
- 为寄存器文件分配空间。
- 把这些寄存器槽先初始化成
undefined。
最后一点很关键。因为GC(Garbage Collection,垃圾回收)会扫描栈帧,如果里面留下了未初始化垃圾值,GC 可能把它误当成有效引用。
字节码到底长什么样
V8 的字节码定义在 v8/src/interpreter/bytecodes.h。
很多名字都很有规律:
Lda*:把值加载到 accumulator。Sta*:把 accumulator 里的值存出去。Star*:把 accumulator 存入某个寄存器。
例如:
1 | V(LdaSmi, ImplicitRegisterUse::kWriteAccumulator, OperandType::kImm) |
这表示 LdaSmi 会把一个立即数形式的小整数(SMI)加载到 accumulator。
除了字节码本身,函数还会关联一个 BytecodeArray。可以把它理解成“这个函数的字节码序列对象”。它不仅保存字节码流,还保存:
- frame size
- register count
- constant pool
- handler table 等辅助信息
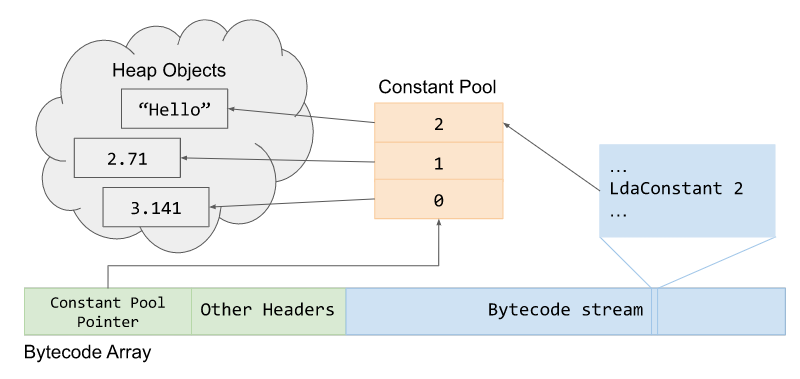
其中 constant pool 也很重要。像字符串属性名、常量引用这些堆对象,不会直接硬编码在字节码指令里,而是通过 constant pool 间接引用。
用一个例子看懂字节码
考虑这个函数:
1 | function incX(obj) { |
在 d8 --print-bytecode 下,可以看到类似下面的输出:
1 | Bytecode length: 11 |
可以按顺序理解:
-
LdaSmi [1]
把整数1放进 accumulator。 -
Star0
把 accumulator 里的1存进寄存器r0。 -
LdaNamedProperty a0, [0], [1]
从第一个参数寄存器a0里取出obj,再根据 constant pool 中索引0对应的属性名x,把obj.x加载到 accumulator。后面的反馈槽索引用于属性访问反馈收集。 -
Add r0, [0]
把r0里的1和 accumulator 中的obj.x做加法。 -
Return
返回 accumulator 里的结果。
这就是为什么我觉得字节码虽然一开始看着很“汇编”,但一旦摸清命名规律,理解难度其实不高。
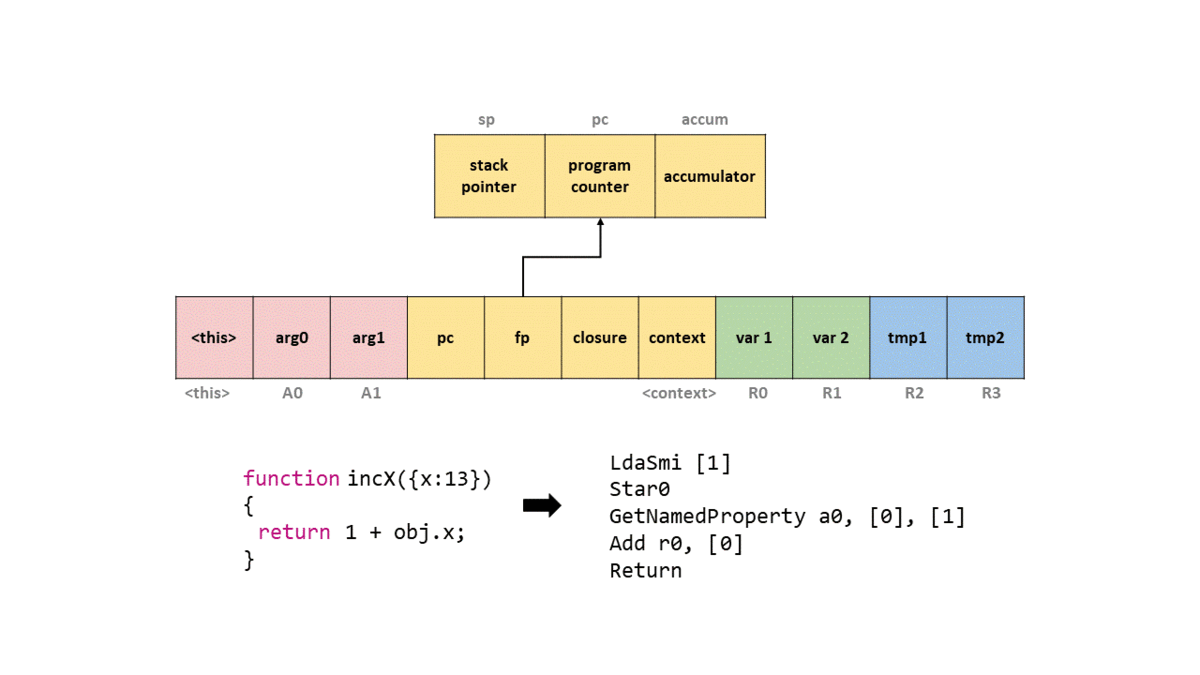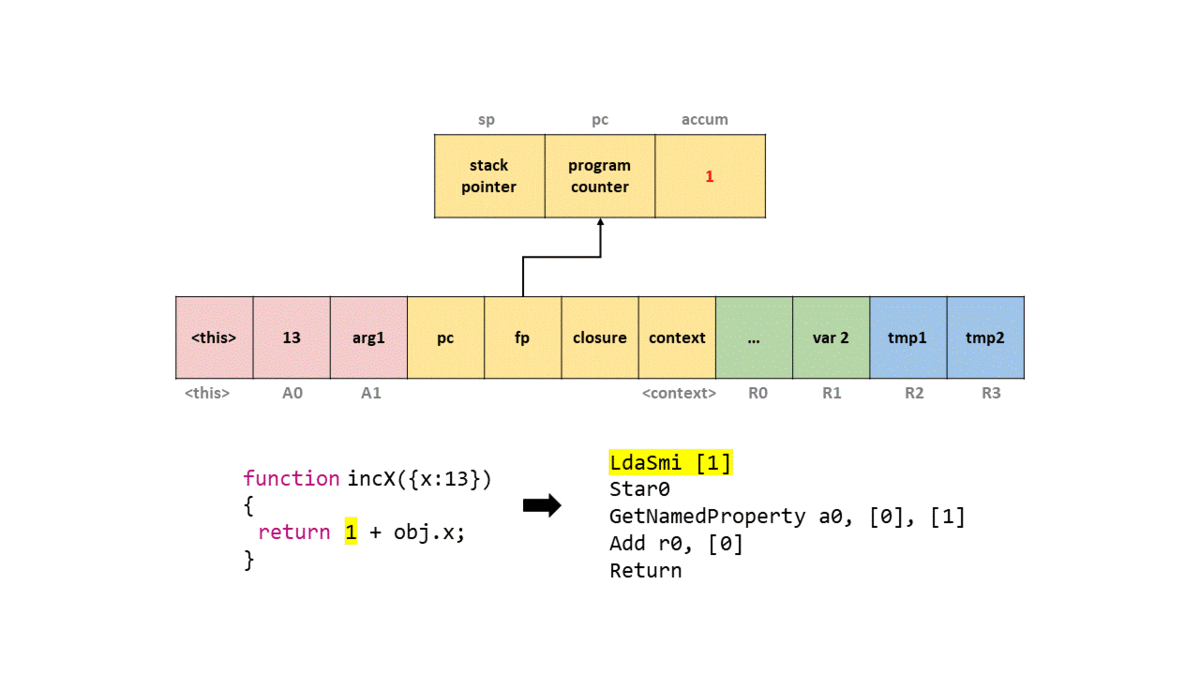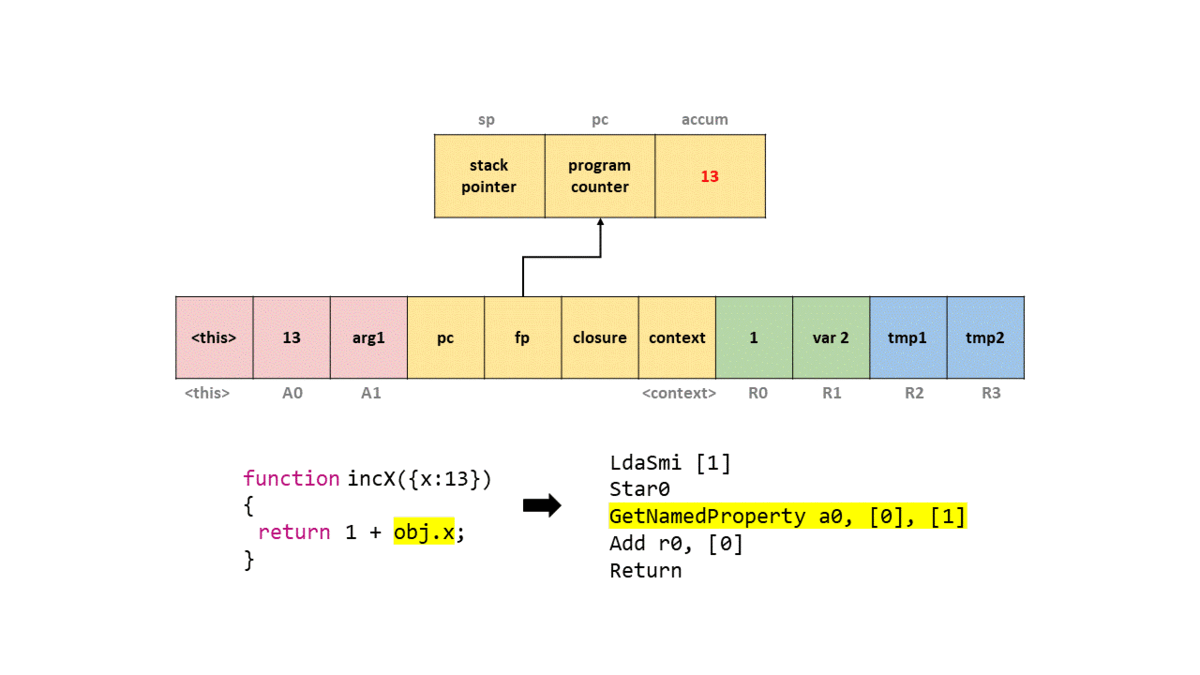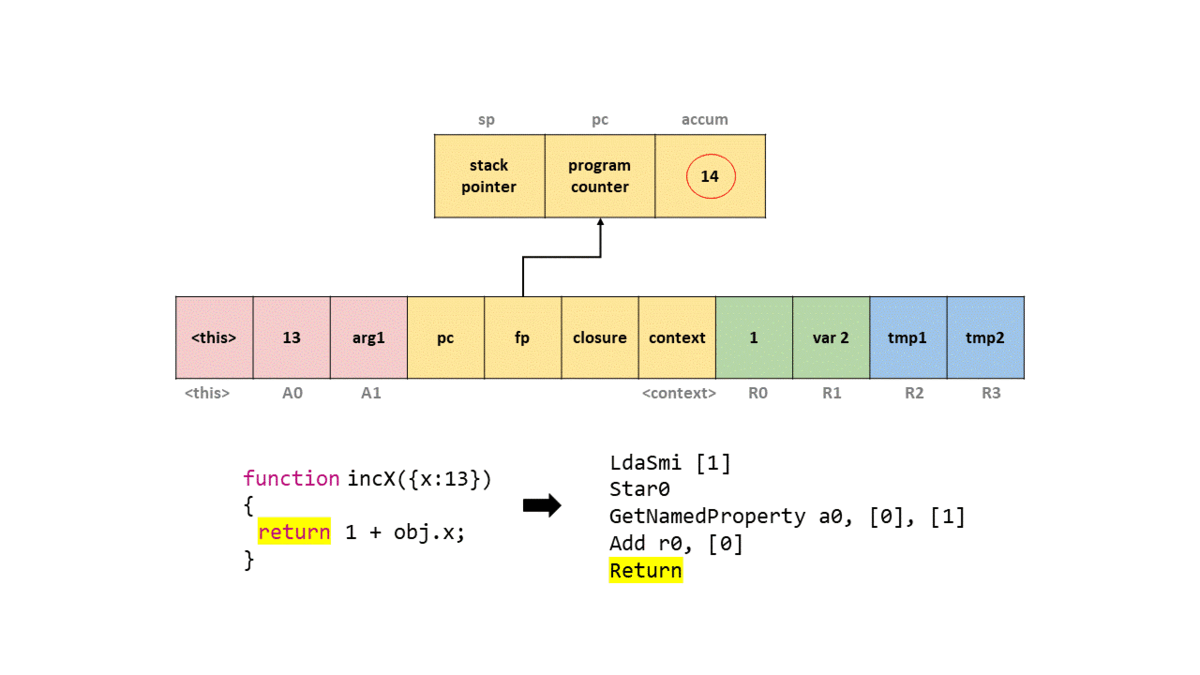
Ignition 对漏洞分析意味着什么
如果站在利用角度看,Ignition 本身给你的最重要信息不是“它慢”,而是:
- 栈帧是怎么布的。
- 寄存器操作数怎么映射到槽位。
FeedbackVector是从哪里开始被填充的。SharedFunctionInfo和BytecodeArray如何成为后续编译阶段的输入。
后面 Sparkplug 和 TurboFan 的很多问题,本质上都是在消费这些信息时出了错。
Sparkplug:极快的基线编译器
在 Ignition 和 TurboFan 之间,V8 又插入了一层 Sparkplug。
官方在 2021 年 5 月 27 日发布的文章 Sparkplug — a non-optimizing JavaScript compiler 中,把它定义为一个极快的、非优化的 JavaScript 编译器。
Sparkplug 为什么快
核心原因就两个字:省事。
它快,不是因为它更聪明,而是因为它少做事:
- 它不再从 JavaScript 源码出发,而是直接从 Ignition 已经生成好的字节码出发。
- 它不做 TurboFan 那种重量级 IR 构建和复杂优化。
- 它尽可能复用解释器已经做好的工作,比如变量解析、控制流结构、函数帧布局。
可以把 Sparkplug 理解成:
不是“深入优化代码”,而是“尽快把字节码变成能直接跑的机器码”。
官方实现里,它基本上是对字节码做非常线性的遍历,并为每条字节码生成对应的机器码序列。它的优化机会非常有限,主要是局部的、便宜的改进,而不是全局重写程序。
它和 Ignition 的关系比想象中更近
Sparkplug 最巧妙的一点,不在于它能生成机器码,而在于它尽量保持“解释器兼容”的栈帧。
官方文档的说法是:Sparkplug 维护 interpreter-compatible stack frames。这意味着:
- 调试器、异常处理、栈回溯、性能分析器不需要为它单独重写一整套逻辑。
- 从 Ignition tier-up(升到更高执行层级)到 Sparkplug 的成本很低。
- OSR(on-stack replacement)更容易做。
这也是为什么很多资料都会强调 Sparkplug 和 Ignition 栈帧几乎是 1:1 对应的。
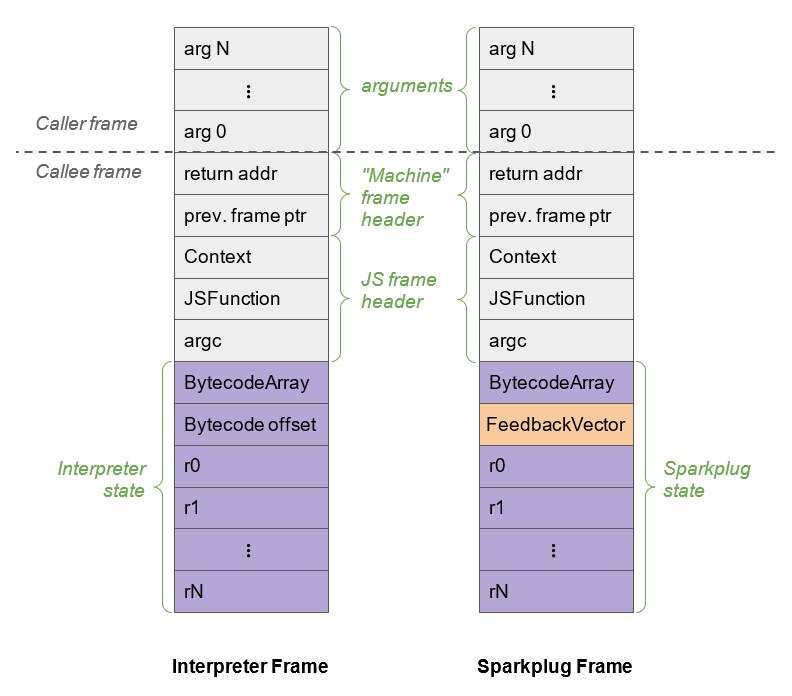
对学习来说,抓住这句话就够了:
Sparkplug 的核心价值不是“优化得多猛”,而是“几乎不增加额外复杂度,却能显著降低解释器的调度开销”。
Sparkplug 带来了什么收益
解释器运行字节码时,每一步都要反复做这些事:
- 读当前字节码
- 解码操作码
- 根据当前字节码,在分发表里查出对应的处理例程入口
- 跳转到那段负责执行这条字节码的解释器代码
这些步骤本身就有开销。Sparkplug 通过把这条“解释流程”固化成机器码,避免了重复的解码和分发开销,所以能明显提高执行速度。
OSR:为什么相似栈帧很重要
OSR(on-stack replacement)可以粗暴理解成:
程序执行到一半,把“当前正在跑的版本”切换成另一个版本。
在 V8 里,热点函数可能先由 Ignition 跑,之后换成 Sparkplug,再进一步进入更重的优化 tier(执行层级)。栈帧布局越接近,这种切换越容易做,也越不容易出错。
从利用视角看 Sparkplug
Sparkplug 自身不是最常见的 JIT bug 温床,因为它做的优化不多。但它仍然很重要,原因是:
- 它要正确理解解释器帧布局。
- 它要正确处理 tier-up 和 OSR。
- 它要正确维护栈状态和元数据。
所以一旦 frame layout、寄存器计数、OSR 元数据出了问题,仍然可能变成可利用漏洞。历史上就出现过这类问题,比如 Issue 1179595。
TurboFan:真正做“推测优化”的地方
前面的 Ignition 和 Sparkplug,更多是在解决“如何先把代码跑起来、再尽快跑得更快”。
TurboFan 解决的是另一个问题:
当某段代码已经足够热,能不能根据运行时反馈,做更激进的推测和优化,换来更高的峰值性能?
在经典 V8 模型里,这就是 TurboFan 的职责。
热点代码如何进入 TurboFan
我们看一个简单例子:
1 | function hot_function(obj) { |
第一次看这段代码时,V8 并不会立刻为它生成 TurboFan 优化后的机器码,而是先让它跑起来,并观察哪些路径真的变“热”了。
在旧版 V8(例如 9.7.0)的 ./d8 --trace-opt /path/to/test.js 里,经常能看到类似输出:
1 | [marking 0x0c5608293511 <JSFunction (sfi = 0xc56082933e5)> for optimized recompilation, reason: small function] |

这里有两个细节要看清:
- 日志里显示的是匿名的
<JSFunction (sfi = ...)>,而不是<JSFunction hot_function ...>。 - 同时它带有
using TurboFan OSR,说明这里触发的是 OSR(On-Stack Replacement,栈上替换)。
这意味着:被优化的更像是“当前正在执行、并且已经跑热了的外层脚本/循环路径”,而不一定是 hot_function 这个命名函数本身单独生成了优化代码。
所以更严谨的说法是:当循环足够热时,V8 可能会把当前执行中的热点路径通过 OSR 送入 TurboFan,而不是在第一次调用 hot_function 时就立刻为它生成优化后的机器码。
如果日志里明确出现 <JSFunction hot_function ...>,那才能更直接地说明 hot_function 本身被单独送去做了优化编译。
第一次看 --trace-opt 日志时,下面几个英文也很容易卡住:
optimized recompilation:不是“重新解析一遍 JavaScript”,而是把已经在跑的函数提升到更高 tier 再编译一次。OSR:On-Stack Replacement,不是重新调用函数,而是“函数跑到一半,直接把当前执行位置切进优化后的代码继续跑”。sfi:SharedFunctionInfo,可以理解成函数共享元数据。日志里经常用它来区分不同函数。small function:旧版 V8 常见的优化原因之一,强调“函数足够小,值得优化”;新版日志里也常见hot and stable这种更强调“足够热、反馈也足够稳定”的说法。
为什么 TurboFan 必须“猜”
TurboFan 的难点在于:JavaScript 是动态语言,很多类型信息只有到运行时才知道。
例如:
1 | function add(i) { |
这里的 i 到底是什么?
- number
- string
- object
- 可以先经过
ToPrimitive转成原始值的对象
这里的 ToPrimitive 是 ECMAScript 规范里的一个转换步骤。可以把它粗暴理解成:
如果一个值本身不是
number、string这类原始值,而是一个对象,那么 JavaScript 在某些运算里会先尝试把它“变成一个原始值”,再继续往下算。
例如,一个对象如果定义了 valueOf(),那 1 + obj 可能会先把对象转成数字再做加法;如果它更适合转成字符串,那同一个 + 也可能退化成字符串拼接。
从 ECMAScript 语义上看,+ 不是单纯的整数加法,它可能是:
- 数值加法
- 字符串拼接
- 先做
ToPrimitive - 再做
ToString或数值转换
如果编译器完全不做假设,那就只能保守地生成一大堆检查和慢路径代码,速度不会好。
所以 TurboFan 必须“猜”,也就是做 speculative optimization。
它靠什么来猜:FeedbackVector 和 IC
这些猜测不是拍脑袋。TurboFan 主要依赖两类信息:
- Inline Cache(IC)收集到的对象形状/访问模式信息
FeedbackVector里记录的反馈槽
例如对 add(i) 这种二元操作,反馈向量里通常会有一个 BinaryOp 槽位,记录历史上看到的输入类型。
如果运行了一段时间后,它观察到 i 一直是小整数,那么对 TurboFan 来说,一个非常自然的推断就是:
这段代码大概率可以按“整数加法”来优化。
推测优化长什么样
继续以上面的 add(i) 为例。
如果历史反馈告诉 TurboFan:i 一直是 number,那么它可以走一条非常快的路径:
- 不再按完整 ECMAScript 语义处理所有可能类型。
- 直接把
1 + i当成数值加法处理。 - 生成更少、更直接的机器指令。
但这会立刻引出一个安全问题:
如果后面突然有人传进来的是字符串怎么办?
这时候就需要 类型守卫(type guard)。
类型守卫和 deopt
TurboFan 的优化代码不是盲信历史反馈,而是会在关键位置插入守卫。只有守卫通过,才能继续跑优化后的机器码。
例如,你可能会在优化后的汇编里看到类似逻辑:
1 | movq rcx,[rbp-0x38] |
它表达的意思非常直接:
- 先把值取出来
- 检查它是不是符合预期表示
- 不符合就跳走
跳走之后去哪?去未优化代码,也就是回到解释器/较低 tier(执行层级)的执行路径,这个过程就叫 deoptimization(反优化),简称 deopt。
这一点非常关键:
TurboFan 的“快”,不是无条件的快,而是“在假设成立时走快路径;假设失效时立刻回退”。
一个典型 deopt 场景
还是用 add(i) 举例:
1 | function add(i) { |
前 7000 次,add(i) 基本只看到了 number,于是 TurboFan 很可能先按 number-only 路径优化。
后面突然出现 "string",守卫不成立,于是发生 deopt,回到较低 tier 继续执行。
更有意思的是:如果这段函数仍然足够热,TurboFan 还可能再次编译它,只不过这一次的反馈更宽了,优化后的代码会兼容更多类型。
这也解释了为什么:
- 同一个函数会被优化
- 又被 deopt
- 之后再被重新优化
Feedback Lattice:反馈为什么只会“越看越宽”
反馈系统可以理解成一种单向扩张的状态机。
一个简化的心智模型如下:
1 | None |
这里的重点不是精确枚举每个节点,而是理解两个性质:
- 反馈通常只会朝“更宽泛”的方向发展。
- 一旦退化到
Any,说明这段代码已经变得比较多态了,优化空间会变小。
这也对应两个常见术语:
- monomorphic:反馈很稳定,比如某个属性访问总看到同一种 shape。
- polymorphic:反馈开始变复杂,比如同一位置看到了多种 shape 或多种类型。
对 JIT 来说,可预测性越高,越容易出激进优化;可预测性越差,越容易走保守路径。
Sea of Nodes、SSA 和中间表示
当 TurboFan 决定优化一个函数后,它不会直接从字节码“硬翻”到最终机器码。中间还会先构建 IR(中间表示)。
经典 TurboFan 最有名的点,就是它使用了 Sea of Nodes 风格的 IR(Intermediate Representation,中间表示),并以 SSA(Static Single Assignment) 作为基础。
先看一个很小的 SSA 例子:
1 | // function add(i) { return 1 + i; } |
SSA 的核心思想是:每个值只赋值一次。这样编译器更容易追踪依赖关系,也更容易做优化。
在 Sea of Nodes 里,程序会被表示成“节点 + 边”的图:
- 节点:操作、常量、加载、存储、调用、检查等
- Value 边:谁依赖谁的值
- Control 边:控制流顺序
- Effect 边:有副作用操作的顺序约束
这套表示法对编译器很强大,但人类看起来并不直观。这也是为什么官方后来在 2025 年明确写过,TurboFan 的 JavaScript 后端已经大量从 Sea of Nodes 转向了更传统的 CFG 风格 IR(Turboshaft)。
不过对于读旧版 JIT 漏洞文章来说,Sea of Nodes 这套语言你还是得会。
Turbolizer:看 TurboFan 图最方便的工具
如果想真正看图,可以用:
1 | ./d8 \ |
然后把生成的 turbo-*.json 扔到 Turbolizer
它能帮你看到:
- 原始 bytecode graph
- 各个优化阶段后的 graph
- 最终机器码
这一点对理解具体优化非常有帮助,因为很多所谓的“JIT bug”,本质就是:
某个节点本来应该存在,但在某个 pass 之后被错误替换、错误合并,或者错误消除了。
以一个turbo_demo.js脚本测试,如下:
1 | function hot_function(obj) { |
然后执行:
1 | mkdir -p /tmp/turbo |
发现生成了一个turbo-hot_function-0.json,将其放到 Turbolizer中,如下:
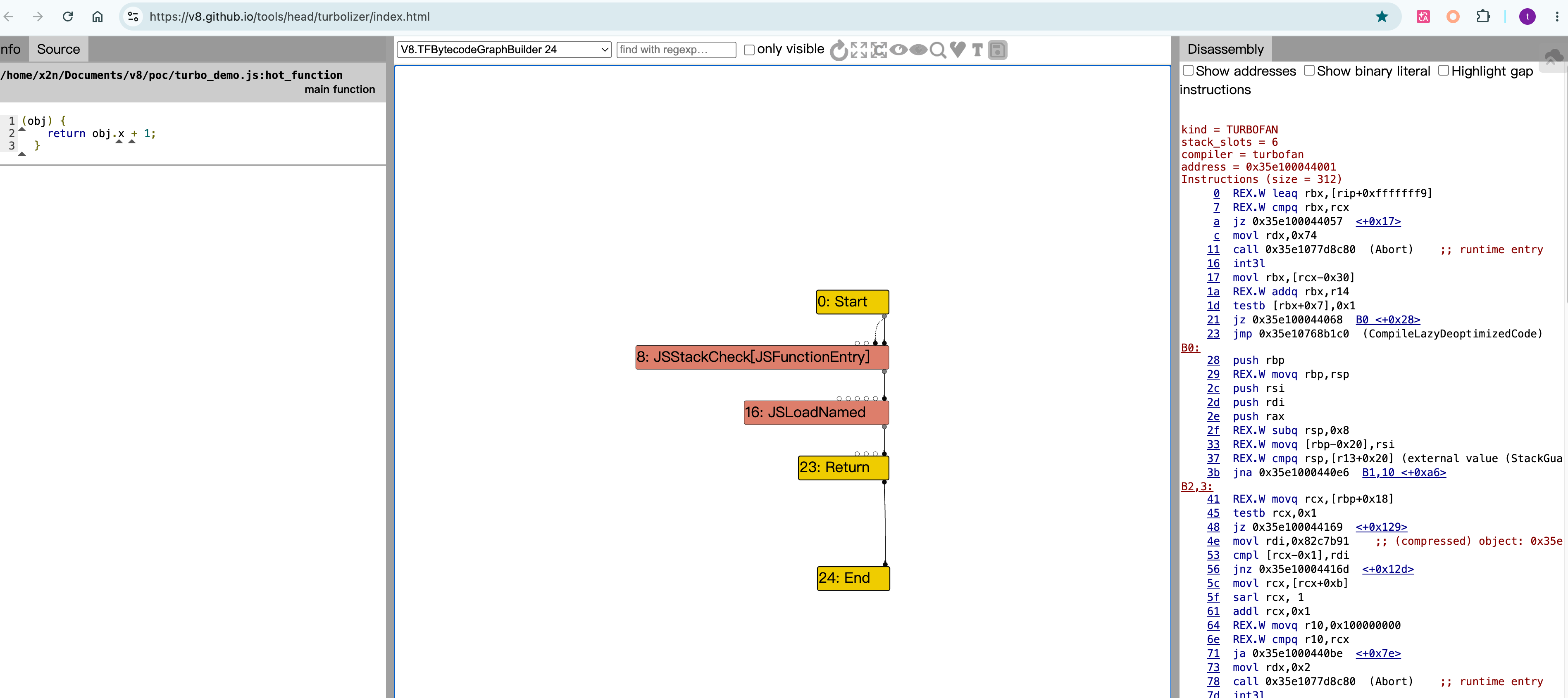
TurboFan 里最常见的几类优化
理解 JIT bug,不需要把每个 pass 全背下来,但下面这几类最好亲手跑一遍。每个例子都可以单独跑 --trace-turbo-filter=<函数名>,然后在 Turbolizer 里截对应阶段的图。不同 V8 版本里节点编号会变,但观察重点不变:看类型、范围、合并点、检查节点和重复节点是怎么变化的。
Typer
Typer 负责给图上的节点推导类型。
它回答的是:
这个节点大概率是什么类型?
示例typer_demo.js:
1 | function typerDemo(x) { |
对应的运行命令可以写成:
1 | mkdir -p /tmp/turbo |
然后把生成的 turbo-typerDemo-0.json 导入 Turbolizer,就能看到下面的结果:
点击19: Return,点击键盘的↑键,可以看到其中忽略的一些节点。
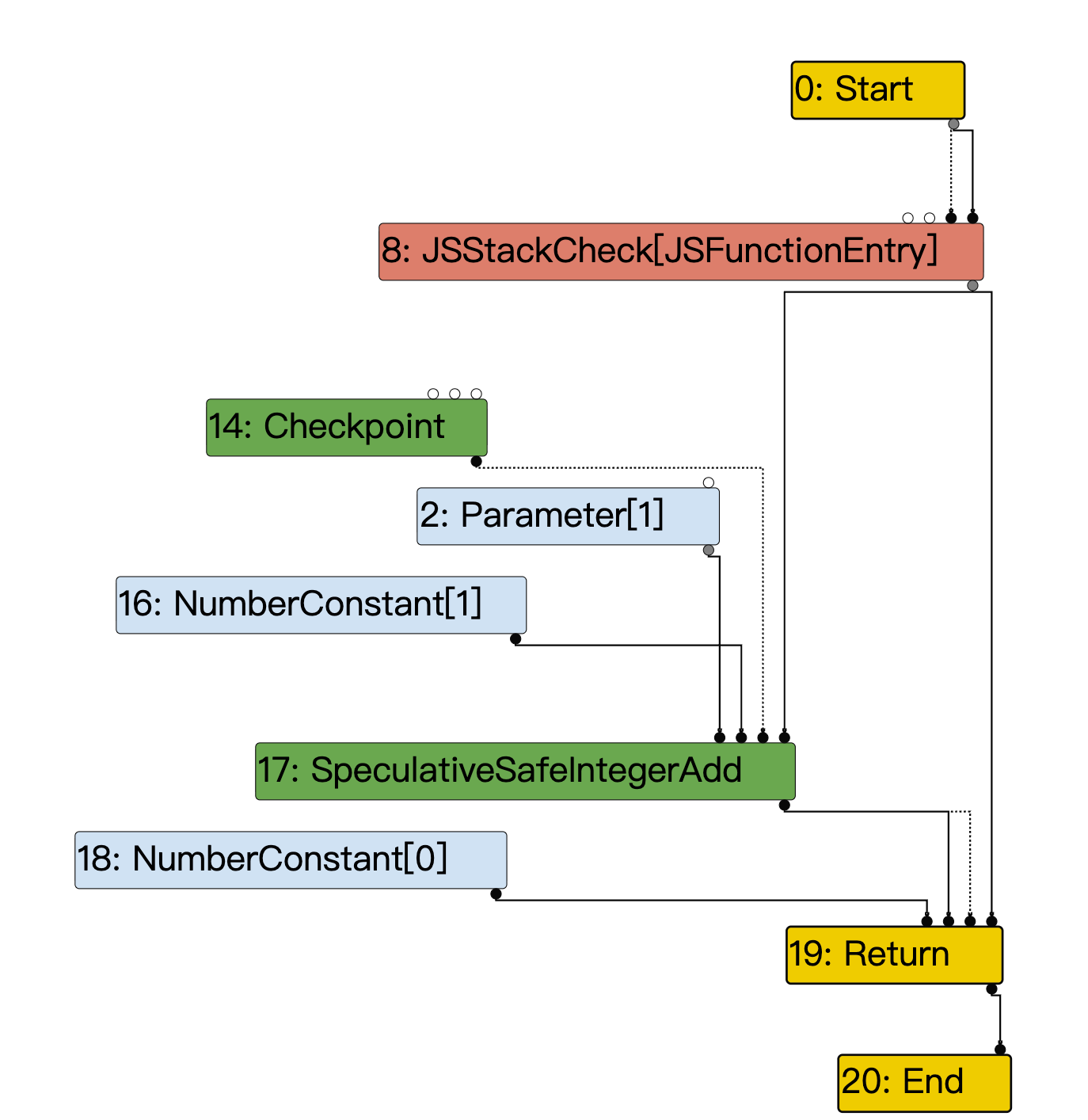
看图时切到 V8.TFTyper,重点找 SpeculativeSafeIntegerAdd / SpeculativeNumberAdd 这类节点,点开后看它的 type/range 是否被收窄。
以我实际跑这个例子时,在 V8.TFTyper 里看到的图为例,可以把它读成下面这样:
2: Parameter[1]:函数参数x16: NumberConstant[1]:常量117: SpeculativeSafeIntegerAdd:把x和1做一次“带推测前提的安全整数加法”19: Return:返回这次加法的结果14: Checkpoint:如果后面的推测失效,V8 需要能从这里恢复状态并 deopt 回未优化代码
这里最关键的是 SpeculativeSafeIntegerAdd 这个节点。它说明 TurboFan 此时已经不再把 x + 1 当成一个完全通用的 JavaScript + 来处理,而是基于反馈和类型推导,先假设:
x大概率是 number- 更具体地说,这里可以走安全整数路径
- 因而这次加法可以按更快的整数语义来优化
换句话说,Typer 并不是“把代码变快”的最后一步,但它会先把原本语义很宽的 JavaScript + 收窄成一个更具体的优化节点。后面的优化阶段看到这个节点时,就会继续在“这里大概率是安全整数加法”这个前提上往下做。
如果这个前提后来被打破,比如你突然传进来字符串、对象,或者别的不符合预期的值,那么这条推测路径就可能触发 deopt,回到较低 tier 的执行路径。
所以对学习来说,这张图最值得记住的不是节点编号,而是这条链路:
1 | Parameter(x) |
这就是 Typer 在图上最直观的一种表现:它让后续优化器有理由相信,“这里不是字符串拼接,也不是通用慢路径,而是一条可以按整数语义继续优化的加法路径”。
如果类型推导错了,后续一连串优化都可能建立在错误前提上。
Range Analysis
范围分析是在类型之外,继续问:
这个值最小是多少?最大是多少?
示例range_demo.js:
1 | function rangeDemo(flag) { |
对应的运行命令可以写成:
1 | mkdir -p /tmp/turbo |
然后把生成的 turbo-rangeDemo-0.json 导入 Turbolizer,就能看到下面的结果:
然后点击xxx
待补充
这个例子里,a 只有两条来源:1 和 2。SSA 里通常会出现 Phi 节点来合并这两个值,所以在 V8.TFTyper 里你能看到 Phi[kRepTagged],在 V8.TFSimplifiedLowering 里能看到它如何流向 LoadElement 或 CheckBounds。
这也是我前面那句“a 可能是 1 或 2,因而 values[a] 的索引范围是受限的”的直接图像化版本。
Bounds Checking Elimination(BCE)
BCE 的目标很直接:
如果编译器已经证明数组索引一定合法,那就没必要每次都再做边界检查。
示例:
1 | function bceDemo(values) { |
看图时重点看 V8.TFSimplifiedLowering 和 V8.TFLoadElimination:如果 BCE 生效,CheckBounds 往往会变少、变窄,或者被搬到循环外。它不一定每次都“完全消失”,但你能明显看到检查结构被压缩了。
这类优化的危险点也很明确:
一旦“证明过程”错了,删掉的就不是无关紧要的代码,而是安全边界本身。
Redundancy Elimination
冗余消除的意思是:
两个检查如果等价,或者前一个已经足以保证后一个成立,那后一个就可以去掉。
示例:
1 | function redundancyDemo(arr) { |
在 Turbolizer 里,这类例子最适合看 V8.TFLoadElimination 或 V8.TFEarlyOptimization:你会发现第二个 arr[0] 很可能不再单独保留,而是直接复用第一次读取的结果。
如果 effect chain 建模错了,或者某个 reducer 把一个本不该等价的节点当成等价节点,就可能把本该保留的检查一起删掉。
其他常见优化
下面这些也很常见,适合当作“补充观察题”:
Control Flow Optimization
它会尽量简化分支和汇合。
1 | function cfoDemo(flag) { |
在图里主要看 Branch / IfTrue / IfFalse / Merge 是否被简化,或者某些分支是否被折叠。
Global Value Numbering(GVN)
它会识别等价计算,避免重复做同样的事。
1 | function gvnDemo(x) { |
在图里重点看重复的 x + 1 是否被合并成同一个值。
Dead Code Elimination(DCE)
它会删除结果根本不会被用到的代码。
1 | function dceDemo(x) { |
如果优化有效,unused 对应的节点会很容易在图里消失。
Alias Analysis
它分析两个内存访问会不会互相影响。
1 | function aliasDemo(obj) { |
如果编译器能确认两个字段不会互相污染,就能更大胆地重排或消除某些访问;如果分析错了,还是会出安全问题。
这些优化本身都很正常,但一旦前提判断错了,依然会把“该保留的检查”或者“该存在的副作用顺序”一起删掉。
为什么 JIT 优化会演变成漏洞
到这里,其实就能回答最关键的问题了:
为什么性能优化会变成安全漏洞?
因为 JIT 优化的本质,就是在“尽量保持语义不变”的前提下,把动态语言执行得更像静态语言。
而这个过程非常依赖假设。
一旦假设错了,常见的漏洞模式就会出现:
-
错误的类型假设
编译器以为这里始终是某种 shape/某种表示,结果实际传进来了别的对象。 -
错误的副作用建模
编译器以为某个操作不会改对象状态,结果它会。 -
错误的范围推导
编译器以为索引绝不会越界,结果某条路径上可以越界。 -
错误的检查消除
编译器以为某个CheckMap/CheckBounds是冗余的,结果它恰恰是最后一道防线。 -
错误的 deopt 元数据
编译器在回退时没法正确恢复解释器状态,也可能造成状态错乱。 -
传统 C++ 内存安全问题
别忘了,V8 编译器和运行时本身也是 C++ 实现的,照样可能有 UAF、OOB、整数溢出等经典 bug。
浏览器利用文章里最常见的一类说法就是 type confusion。它本质上是:
编译器把一个值当成 A 类型来用,但运行时它其实是 B 类型。
一旦这个错位发生在对象布局、元素种类、数组长度、指针解释等关键位置,后面就很容易走向任意地址读写、伪造对象或任意代码执行。
读 JIT Bug 时我会重点看什么
如果后面继续读 V8/Chrome 漏洞分析文章,我觉得可以按下面的顺序看:
- 先看原始 JavaScript 语义,确认作者到底利用了哪个动态特性。
- 再看字节码,确认 Ignition 眼里的真实执行步骤。
- 看反馈是否稳定,是单态还是多态。
- 看优化后 graph 里哪些检查被插入了,哪些检查被删掉了。
- 看 deopt 点和 side-effect 建模,确认“编译器为什么相信这里安全”。
- 最后再看漏洞触发点,判断它属于类型推导错、范围分析错、检查消除错,还是副作用建模错。
只要把这条阅读路径建立起来,后面看任何 JIT bug,都会顺很多。
用 d8 调试后续 Chrome / V8 漏洞时最常用的命令
如果后面要继续看 Chrome / V8 漏洞分析文章,我更建议把这一节当成“调试手册”来用,而不是把它当成一组入门演示。
核心思路其实很简单:
- 先看 JavaScript 在 Ignition 眼里到底变成了什么字节码。
- 再看函数有没有被送进优化 tier。
- 再看 TurboFan 图里插了哪些检查、删了哪些检查。
- 最后看当假设失效时,V8 会在哪个点 deopt。
下面这些命令,是我觉得后面读 JIT 漏洞时最常用的一组。
1. 看字节码:确认解释器眼里的真实执行步骤
1 | ./d8 --print-bytecode ./poc.js |
这一步最适合回答两个问题:
- 这个 PoC 里的属性访问、加法、数组访问,在字节码层面到底对应哪些指令?
- 哪个 bytecode offset 会和后面的
deopt日志、节点编号对应起来?
如果你在后面的日志里看到 bytecode offset 5、LdaNamedProperty、Add、StaNamedProperty 这些名字,就知道它们不是抽象名词,而是可以和真实执行步骤一一对上的。
2. 看对象和反馈:确认反馈向量、Map、元素种类是否稳定
1 | ./d8 --allow-natives-syntax ./poc.js |
进入 d8 后,经常会配合这些内部函数:
1 | %DebugPrint(obj); |
这一步最适合观察:
- 某个对象当前的
Map是什么 - 数组的 elements kind 有没有发生变化
- 函数对象上是否已经挂上了
FeedbackVector
如果一个漏洞分析反复提到“先把数组打成 PACKED_DOUBLE_ELEMENTS”或者“先把反馈喂成单态”,本质上就是在为这一步服务。
3. 看什么时候进入优化:确认是 OSR,还是函数本身被单独优化
1 | ./d8 --trace-opt ./poc.js |
这一步最适合回答:
- 到底有没有发生 TurboFan 优化
- 被优化的是外层热循环,还是某个命名函数本身
- 是普通优化,还是
OSR(on-stack replacement,栈上替换)
如果你想稳定观察某个具体函数被优化,通常会配合:
1 | ./d8 --allow-natives-syntax --trace-opt --no-concurrent-recompilation ./poc.js |
再用:
1 | %PrepareFunctionForOptimization(fn); |
这样做的意义不是“作弊”,而是把“这个函数是否真的进了 TurboFan”这件事确定下来,避免被外层热循环的 OSR 日志干扰。
4. 看什么时候 deopt:确认哪条假设失效了
1 | ./d8 --allow-natives-syntax --trace-opt --trace-deopt --no-concurrent-recompilation ./poc.js |
这一步最适合回答:
- 这段优化代码是不是又回退了
- 回退原因是什么,比如
not a Smi、wrong map、out of bounds - 回退发生在第几个优化版本、哪个 bytecode offset、哪个节点附近
例如我实际跑过的一个最小例子里,最后出现的是:
1 | [bailout (kind: deopt-eager, reason: not a Smi): begin. deoptimizing ... bytecode offset 5 ...] |
这类日志的价值很高,因为它通常直接告诉你:
- 编译器原来假设这里是小整数
- 这个假设已经失效
- 当前执行流正在退回未优化代码
5. 导出 TurboFan 图:确认图里有哪些节点被插入、替换或删掉了
1 | mkdir -p /tmp/turbo |
这一步最适合回答:
CheckMap、CheckBounds、Phi、LoadElement这些节点在不在- 它们在哪个 phase 之后发生了变化
- 某个看起来“应该保留”的节点,是在哪一轮 pass 里消失的
如果你后面要对着漏洞文章复现图,通常会重点切这几个 phase:
V8.TFTyperV8.TFSimplifiedLoweringV8.TFLoadEliminationV8.TFEarlyOptimization
6. 看 reducer 到底替换了什么:定位“是哪一步把节点改坏了”
1 | ./d8 --trace_turbo_reduction ./poc.js |
这一步在简单入门时不一定常用,但在读复杂 JIT bug 时很关键。
它最适合回答:
- 是哪个 reducer 把某个节点替换掉了
- 某个检查是被谁删掉的
- 图上的“变化”到底发生在哪一步,而不是只看最终结果
如果你已经在 Turbolizer 里看到“一个节点不见了”,但还不知道它是怎么不见的,这个命令就很有用。
7. 一套我自己会优先走的最小排查顺序
如果给我一个新的 Chrome / V8 JIT PoC,我通常会按这个顺序看:
--print-bytecode:先确认解释器语义。%DebugPrint:确认对象布局、Map、elements kind、反馈状态。--trace-opt:确认有没有真的进入 TurboFan。--trace-deopt:确认假设会不会崩,崩在哪里。--trace-turbo:看图里有哪些CheckMap/CheckBounds/Phi。--trace_turbo_reduction:追具体是哪一步把图改成了现在这个样子。
如果把这条顺序建立起来,后面再读漏洞文章里那些“先喂反馈、再触发优化、最后打破假设”的套路,就不会觉得全是黑魔法了。
d8 调试速查
下面这些命令在学习 V8 JIT 时非常常用。需要注意两点:
d8的具体 flag 和输出格式会随 V8 版本变化。- 如果你分析的是某个特定 Chrome 漏洞,最好尽量使用与目标版本接近的
d8/V8 构建环境。
| 目的 | 命令 |
|---|---|
| 打印字节码 | d8 --print-bytecode |
允许使用 %DebugPrint 等内部语法 |
d8 --allow-natives-syntax |
| 看函数当前入口/反汇编 | %DisassembleFunction(fn) |
打印函数对象、FeedbackVector 等 |
%DebugPrint(fn) |
| 观察何时进入优化 | d8 --trace-opt |
| 观察何时 deopt | d8 --trace-deopt |
| 导出 TurboFan 图 | d8 --trace-turbo your.js |
| 观察 graph reducer 做了哪些替换 | d8 --trace_turbo_reduction your.js |
总结
把这一篇压缩成一句话就是:
Ignition 负责把 JavaScript 变成可执行字节码并收集反馈,Sparkplug 负责以极低成本把字节码变成基线机器码,TurboFan 则基于运行时反馈做推测优化,并依靠类型守卫和 deopt 保证“快路径”不偏离 JavaScript 语义。
而浏览器 JIT 漏洞,往往就出在这条链路最微妙的地方:反馈被错误理解、守卫被错误消除、范围被错误推导、副作用被错误建模,或者回退状态被错误恢复。
理解了这条主线,后面再去看具体漏洞,比如 CheckMap、CheckBounds、LoadElimination、RedundancyElimination、deopt 这些词,就不会再是一团雾了。
参考
- Chrome Browser Exploitation, Part 2: Introduction to Ignition, Sparkplug and JIT Compilation via TurboFan
- Chrome Browser Exploitation, Part 1: Introduction to V8 and JavaScript Internals
- Chromium Multi-process Architecture
- Chromium Sandbox Design
- Design of V8 Bindings
- Getting Started with Embedding V8
- Using d8
- Built-in functions
- Ignition
- Firing up the Ignition interpreter
- Sparkplug — a non-optimizing JavaScript compiler
- TurboFan
- Maglev - V8’s Fastest Optimizing JIT
- Land ahoy: leaving the Sea of Nodes
- Turbolizer
- JavaScript Engine Fundamentals: Shapes and Inline Caches
- What’s up with Monomorphism?