Chrome-v8学习-精简版-1
前言
对之前文章的精简版[1]。
1、JavaScript引擎基础工作流
1.1 为什么要先学引擎原理?
所有V8漏洞的本质都是:V8引擎在解析/执行JS代码的过程中,某个步骤的逻辑出现了错误,导致攻击者可以控制内存、执行任意代码。所以我们必须先知道「正常情况下V8是怎么工作的」,才能理解「哪里会出问题」。
1.2 常见JS引擎对比
| 引擎名称 | 所属厂商 | 使用场景 |
|---|---|---|
| V8 | Chrome浏览器、Node.js | |
| SpiderMonkey | Mozilla | Firefox浏览器 |
| JavaScriptCore | Apple | Safari浏览器 |
所有JS引擎都遵循ECMAScript标准,核心工作逻辑基本一致,学会V8之后其他引擎也可以快速举一反三。
1.3 JS引擎的编译流水线(核心流程)
JS最初是纯解释型语言,执行效率很低,现代JS引擎都会引入JIT(即时编译)优化,整体流程如下:
1 | JS代码 → 解析器(Parser) → AST抽象语法树 → Ignition解释器 → 字节码 |
每个步骤的作用:
- 解析器(Parser):
-
先把JS代码拆成「Token」(比如
var num = 42会拆成var关键字、num标识符、=运算符、42数字四个Token)- 再把Token转换成AST(抽象语法树),同时检查语法错误,有语法错误直接抛出,不会往下执行。
- Ignition解释器:把AST转换成跨平台的字节码,边解释边执行,启动速度快,但执行效率低。
- TurboFan优化编译器:如果某段代码被反复执行(比如循环里的代码、被频繁调用的函数),就会被标记为「热点代码」,交给TurboFan编译成高度优化的机器码,执行效率可以接近C/C++。
- 注意:优化是基于「代码执行时的假设」做的,比如假设函数的参数一直是整数,如果后续参数变成了字符串,优化后的代码就会「去优化」,退回到字节码执行。很多V8漏洞就是利用了优化过程中的假设错误,这也是我们后面重点要学的内容。
1.4 栈机 vs 寄存器机
Ignition解释器是基于「栈机」设计的,而TurboFan编译后的机器码是基于「寄存器机」的:
- 栈机:所有操作都基于栈来完成,比如计算
1+2,先把1压入栈,再把2压入栈,弹出两个数相加,把结果压回栈。优点是跨平台、实现简单,缺点是执行速度慢。 - 寄存器机:直接操作CPU寄存器来完成计算,执行速度快,但是和平台架构强绑定。
2、V8对象内存表示
2.1 为什么V8要做这么多内存优化?
JavaScript是动态类型语言:你可以随时给对象加属性、删属性、改属性类型,不像C++对象在编译时结构就固定了。如果每次访问对象属性都要哈希查表,JS执行速度会非常慢,所以V8设计了大量优化机制来提升属性访问速度,而这些优化的「边角情况」就是漏洞高发区。
2.2 基础概念:Smi和堆对象
V8把所有JS值分成两大类:
| 类型 | 说明 | 内存特征 |
|---|---|---|
| Smi(Small Integer,小整数) | 范围在-2^30 ~ 2^30-1之间的整数,不需要单独在堆上分配内存 |
内存地址最后一位是0(...00),值直接存在指针里,比如1在内存里存的是2(...10)(左移1位,把最后一位空出来当标记位) |
| HeapObject(堆对象) | 除了小整数之外的所有值:对象、数组、字符串、浮点数、函数等,都需要在堆上分配内存 | 内存地址最后一位是1(...01),指针指向堆上的真实对象地址 |
✅ 小技巧:你看V8内存里的值,最后一位是0就是数字,是1就是对象指针,这个标记机制后面漏洞利用的时候会经常用到。
2.3 核心概念:Hidden Class(也叫Map,注意和JS的Map对象区分开)
V8给每个对象都分配了一个隐藏类(Map),用来描述这个对象的结构:有哪些属性、属性的类型、属性在内存里的偏移位置。结构相同的对象会共享同一个Map,这样不需要每个对象都存一份结构信息,大大节省内存和提升访问速度。
举个例子:
1 | const obj1 = {x:1, y:2} |
Map的过渡规则:
当你给对象加属性时,Map会按照固定顺序过渡:
1 | const obj = {} // Map A:空对象 |
✅ 重点:
- 只有属性添加顺序完全一样的对象,才会共享同一个Map
- 如果删除属性、或者添加太多属性,对象会从「快模式」切换到「慢模式(字典模式)」,所有属性存在哈希表里,不再有Map过渡,访问速度会变慢,同时也无法共享Map。
2.4 属性的存储方式
V8的对象属性分两大类:
- 命名属性:比如
obj.x、obj.name这种通过名字访问的属性
- In-Object属性:直接存在对象本身的内存里,访问速度最快,数量固定,初始化对象时分配
- 快属性:存在单独的属性数组里,通过Map里的索引来访问,速度稍慢
- 慢属性(字典模式):存在哈希表里,不需要Map,访问速度最慢,一般是属性太多/删除属性时才会触发
- 索引属性(Elements):比如
arr[0]、arr[1]这种数组索引访问的属性,存在单独的Elements数组里
2.5 数组的Elements类型
V8对数组做了非常细的分类,目的是为了优化数组操作的速度,核心有3个维度:
维度1:元素类型
| 类型 | 说明 |
|---|---|
PACKED_SMI_ELEMENTS |
数组里全是小整数,没有空洞 |
PACKED_DOUBLE_ELEMENTS |
数组里有浮点数,没有空洞 |
PACKED_ELEMENTS |
数组里有对象/字符串等非数字类型,没有空洞 |
维度2:是否有孔洞(holes)
-
PACKED:数组是连续的,没有空位(比如[1,2,3]) -
HOLEY:数组有空位(比如[1,,3],索引1是空的),访问的时候需要检查空位,速度更慢✅ 重点:Elements类型的过渡是单向的,只能从高级往低级过渡,不能回头:
-
如果你给全是整数的数组加一个浮点数,数组类型就从
PACKED_SMI_ELEMENTS变成PACKED_DOUBLE_ELEMENTS,就算你后来把浮点数删掉,也变不回SMI类型了。 -
如果你给数组加了一个空位,就变成
HOLEY_*类型,就算你把空位填上,也变不回PACKED类型了。
这里面的概念有点多了,下面详细解释一下。
思考1:前文提到的孔洞(hole)是什么意思?
(1)英文原文
对应V8官方术语是 hole(复数形式holes),教程里对应的数组类型标记是HOLEY_*,和表示「无孔洞数组」的PACKED_*是对应概念。
(2)具体含义
孔洞指数组中未被实际赋值的空索引位置,注意和「存储了undefined值的索引」是完全不同的概念:
1 | // 有孔洞的数组:索引2的位置是hole,没有实际存储任何值 |
(3)为什么V8要专门区分hole?
核心是性能优化:
- 如果数组是
PACKED(无孔洞)的,V8操作数组时不需要额外判断某个索引是否存在,直接按内存偏移量读取即可,速度极快 - 如果数组是
HOLEY(有孔洞)的,每次访问索引时V8都需要额外做判断:这个索引是不是不存在?是不是要去原型链上查找对应的属性?会带来额外开销
✅ 重点注意:孔洞的标记是不可逆的,只要数组出现过孔洞,就会一直被标记为HOLEY类型,哪怕你后续把孔洞的位置补上值,也不会变回PACKED类型,性能开销会一直存在。
这个概念后面学漏洞利用会经常用到:很多V8越界读写漏洞的根源,就是V8对孔洞的校验逻辑出现了错误,导致攻击者可以绕过边界检查,读写数组范围外的内存。
思考2:快属性和慢属性之间的区别是什么?
二者之间本质区别:访问方式的差异
| 类型 | 存储结构 | 访问速度 | 依赖 | 适用场景 |
|---|---|---|---|---|
| 快属性(Fast Properties) | 线性数组 | 极快(O(1),和C++访问结构体成员速度相当) | 依赖Map的描述符数组 | 属性结构稳定、添加顺序固定的对象 |
| 慢属性(Slow Properties / 字典模式) | 哈希表 | 表 慢(O(1)平均复杂度,但有哈希计算、冲突处理开销,比快属性慢几倍到几十倍) | 不依赖Map,自包含哈希表 | 属性频繁增删、结构非常不规律的对象 |
1. 快属性详解
快属性是V8默认的属性存储模式,核心是用Map的描述符数组记录属性的位置,用线性数组存属性值:
(1)核心结构
每个对象有三块核心内存:
1 | 对象内存首地址 → [ 指向Map的指针 | 指向Elements数组的指针 | 指向Properties数组的指针 | In-Object属性值... ] |
(2)两种快属性细分
- In-Object属性:属性值直接存在对象本身的内存里,连Properties数组的跳转都不需要,是最快的属性。一般对象初始化时定义的前N个属性(不同V8版本N不同,一般是前几个)会被分配为In-Object属性,数量固定。
- 普通快属性:属性值存在独立的Properties数组里,需要多一次内存跳转,速度稍慢,但可以动态扩展容量。
(3)访问流程示例
比如要访问obj.x:
- 拿到
obj的Map,查Map的Descriptor数组,找到x对应的偏移量是0 - 如果
x是In-Object属性:直接按偏移量读对象本身的内存,拿到值 - 如果是普通快属性:去Properties数组读索引0的位置,拿到值
整个过程不需要任何哈希计算,和C++里obj.x的访问速度几乎一样。
2. 慢属性(字典模式)详解
当对象的属性变化不符合Map的过渡规则时,V8会将对象不可逆地降级为慢属性模式,放弃Map优化,改用哈希表存储。
(1)触发降级的常见条件
- 动态添加的属性太多(一般超过20个,阈值随V8版本调整)
- 删除了非最后添加的属性(比如先加
x、再加y,然后删除x,破坏了Map过渡的顺序) - 属性名非常不规律,比如大量随机字符串、数字字符串作为属性名
(2)核心结构
降级后,Map不再维护属性的偏移信息,对象的Properties位置直接指向一个哈希表:
1 | Properties哈希表 → { "x": 1, "y": 2, "z": 3 ... } |
(3)访问流程
访问obj.x时,需要对x做哈希计算、处理哈希冲突、查表才能拿到值,速度比快属性慢很多,优点是不需要维护Map过渡链,适合属性频繁增删的场景,内存开销更低。
✅ 验证方式
你可以在V8的d8 shell里用%DebugPrint(obj)直接看到对象的属性模式:
1 | # 快属性模式的对象输出会有这个标记 |
为什么漏洞利用会关注这个?
很多V8类型混淆漏洞的核心原理就是:攻击者通过特殊构造的JS代码,让V8错误地判断对象是快属性/慢属性模式,从而计算出错误的内存偏移,最终实现越界读写内存。
3、Map的完整结构
我们首先明确:这里的Map是V8内部的HiddenClass(隐藏类),也叫Shape,和JavaScript原生的Map对象是完全不同的概念,后面提到的Map默认都指V8内部的隐藏类。
Map是V8用来描述堆对象内存布局的「元数据」,是所有属性访问、类型判断的核心依据,完整结构如下:
3.1 Map核心字段(通用结构,不同V8版本字段顺序/数量略有差异)
你可以在d8调试时用%DebugPrint(obj)直接看到Map的所有字段,对应教程里的调试输出例子:
1 | 0000025300259735: [Map] in OldSpace |
每个核心字段的含义:
| 字段 | 作用 |
|---|---|
| type | 对象类型标记,比如JS_OBJECT_TYPE普通对象、JS_ARRAY_TYPE数组、JS_FUNCTION_TYPE函数等,V8通过这个字段判断对象的基础类型 |
| instance size | 该类型对象在堆上占用的总字节数,V8分配内存时会按这个大小分配 |
| inobject properties | In-Object快属性的数量,也就是对象本身内存里直接能存多少个属性,超过这个数量的属性会存到独立的Properties数组里 |
| elements kind | 数组/对象的索引属性类型,就是我们之前讲的PACKED_SMI_ELEMENTS/HOLEY_ELEMENTS等21种类型,是V8优化数组操作的核心依据 |
| back pointer | 反向过渡指针,指向当前Map是从哪个Map过渡来的(比如给空对象加x属性后生成新Map,新Map的back pointer就指向空对象的Map) |
| instance descriptors | 指向描述符数组(DescriptorArray),是快属性的核心:数组每个元素对应一个属性的元信息:属性名、属性类型(数据属性/访问器属性)、属性在In-Object/Properties数组里的偏移量、可写/可枚举/可配置标记 |
| prototype | 指向该类型对象的原型对象(对应JS的__proto__) |
| constructor | 指向创建该对象的构造函数(对应JS的constructor) |
| dependent code | 指向依赖这个Map的优化后的机器码:如果这个Map被废弃(比如对象结构发生变化),所有依赖它的优化代码都会被标记为无效,触发去优化(deoptimize) |
| stable_map标记 | 表示当前Map是稳定的,TurboFan可以基于这个Map做优化,如果后续Map结构发生变化,这个标记会被清除 |
📌 Map的过渡树结构
Map不是孤立存在的,V8会把所有通过「顺序添加属性」生成的Map连成一个过渡树,相同结构的对象会复用同一个Map,避免重复创建:
举个例子:
1 | // 1. 空对象,对应Map A |
重要规则!!!:
- 只有属性添加顺序完全一致,结构才会复用同一个Map。如果先加y再加x,会生成完全独立的另一条过渡链,不会复用上面的Map。
- 一旦删除非最后添加的属性、或者添加太多属性,对象会降级到字典模式,脱离过渡树,不再共享Map。
✅ 为什么Map是漏洞利用的核心?
V8完全依赖Map来判断对象的结构、计算属性的内存偏移,如果攻击者能篡改某个对象的Map指针,就可以欺骗V8:
- 比如把一个普通对象的Map改成数组的Map,V8就会把这个对象当成数组来解析,从而可以越界读写对象外的内存
- 比如把一个只读属性的Map描述符改成可写,就可以修改原本不能修改的内存区域
大部分V8类型混淆漏洞的本质,就是通过特殊构造的JS代码,让V8错误地给对象分配了不符合预期的Map,或者让攻击者有机会篡改对象的Map指针。
4. 指针标记(Pointer Tagging)
4.1 为什么需要指针标记?
前面我们提过,V8里Smi小整数是直接存在指针里的,不需要单独在堆上分配,这就带来一个问题:V8怎么区分一个值到底是Smi整数,还是指向堆对象的指针? 指针标记就是用来解决这个问题的,利用的是x86/x64系统的内存对齐特性:堆上分配的对象都是按4/8字节对齐的,所以内存地址的最低两位一定是0,V8就用这两位来做标记。
4.2 x64架构下的标记规则
| 值类型 | 最低位标记 | 存储规则 | 示例 |
|---|---|---|---|
| Smi(小整数) | 0 |
整数左移1位,把最低位空出来写0 | 真实值是1,内存里存的是2(二进制10,最后一位是0) |
| 强指针(指向堆对象,GC需要引用计数) | 1,次低位是0 |
真实的内存地址,最低位强制设为1 | 真实的对象地址是0x123456780,内存里存的是0x123456781 |
| 弱指针(指向堆对象,GC不需要引用计数) | 1,次低位是1 |
真实的内存地址,最低两位设为11 |
真实的对象地址是0x123456780,内存里存的是0x123456783 |
4.3 强调实战技巧
你在WinDBG/GDB里看V8内存的时候,看到一个值:
- 如果最后一位是0 → 右移1位就是真实的整数值
- 如果最后一位是1 → 减1就是真实的堆对象内存地址
对应教程例的例子:
1 | root@x2n:/home/x2n/Documents/v8/v8/out/x64_.release# ./d8 --allow-natives-syntax |
直接查看0x3791080498ed,发现内容是乱的。
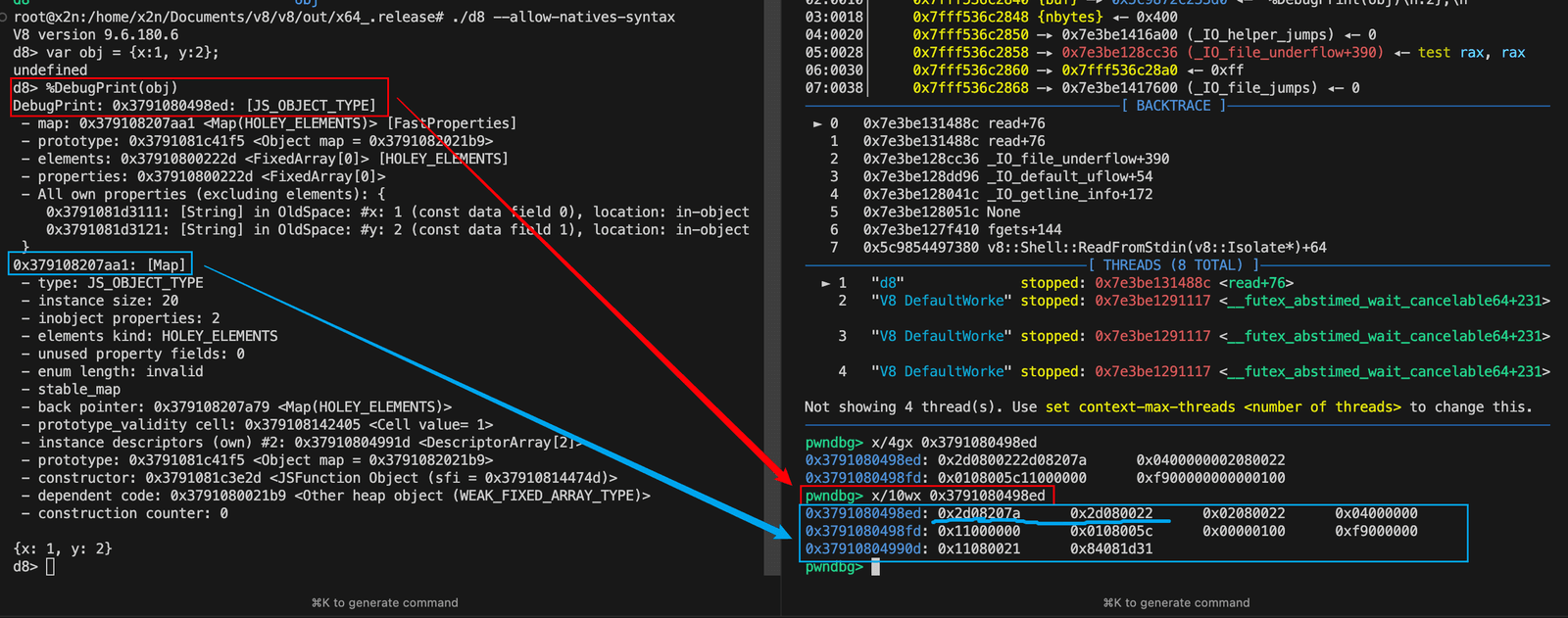
调试输出里的对象地址是0x3791080498ed,最后一位是d,二进制表示为1101,去掉最后一位1,就是1100是c,所以真实地址为真实地址是0x3791080498ec
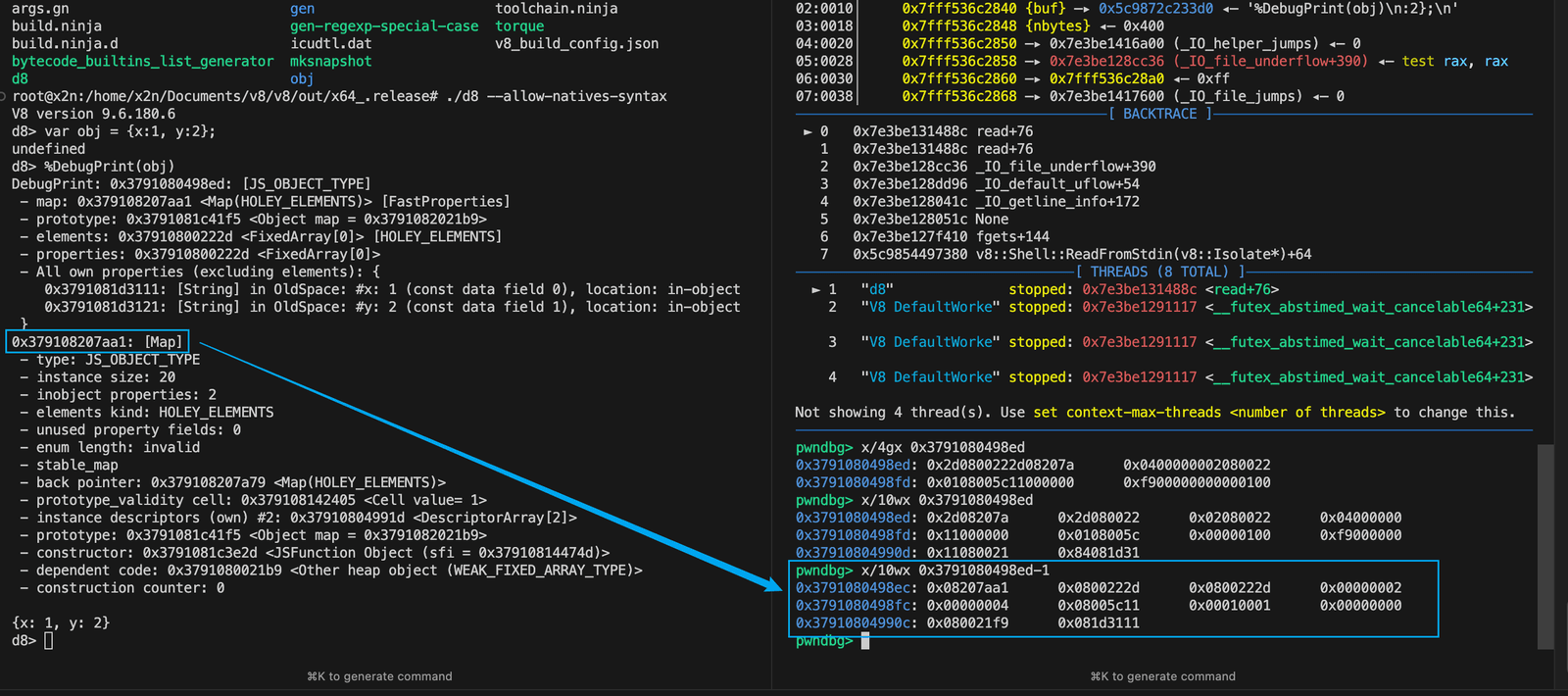
⚠️这里的黄色箭头我指错了,我想指真实地址中的内容,后面仔细看了文章才发现指错了!。我想指x/10wx 0x3791080498ed-1地址中的内容,这里0x37910800222d和0x2d080022明显对不上,下面的0x0800222d才是对的,这也正说明了x/10wx 0x3791080498ed-1才是真实的地址。
然后我们看绿色箭头部分。对象中x属性值是2,右移1位得到真实值1,y属性值是4,右移1位得到真实值2。
我们看内存中的值0x00000002和0x00000004,最后2和4分别为0010和0100,分别右移一位,就是0001和0010,就是真实的1和2值!!!。
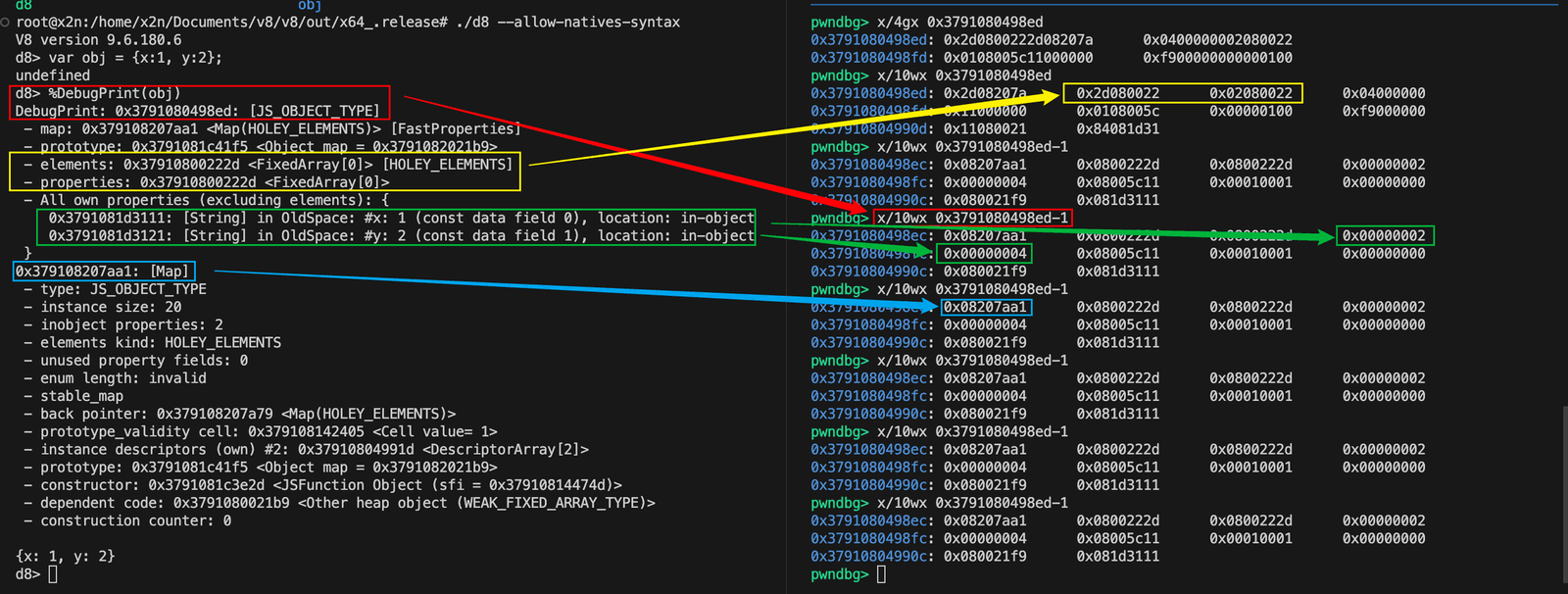
✅ 漏洞利用注意:你构造任意地址读写的时候,读出来的Smi值需要右移1位才是真实值;写Smi值的时候需要左移1位,把最后一位设成0,否则V8会把它当成指针处理。
5. 指针压缩(Pointer Compression)
5.1 为什么需要指针压缩?
x64架构下指针是8字节的,而V8堆上大部分对象里都存了大量指针,导致内存开销非常大。V8团队发现,V8的堆内存一般不会超过4GB,而且堆上的对象地址的高32位都是相同的,所以可以只存低32位的地址,高32位存在一个固定的寄存器(R13寄存器,叫Isolate Root指针)里,这样指针就从8字节压缩到了4字节,内存开销直接减少一半。
这里也可以在上面的调试中看出来,调试值只有后八位!例如:0x37910800222d,在查看内存中的内容时候,只有0x0800222d!!!。
5.2 压缩规则
- V8的整个堆内存会被映射到同一个4GB的虚拟内存区域,所有堆对象的高32位地址都相同,这个高32位的基地址存在R13寄存器里
- 对象里存的指针只有低32位,访问的时候,用
基地址 + 低32位地址就能得到完整的64位指针
对应教程里的例子:你在DBG里看对象里存的Map指针,只有低32位是有效的,高32位全是0,加上R13寄存器里的基地址才是完整的Map地址。
5.3 漏洞利用注意
- 不同版本V8的指针压缩开关可能不一样,新版本V8默认开启指针压缩,老版本可能关闭
- 如果你写的POC要跨版本运行,需要先判断目标V8是否开启了指针压缩
- 构造任意地址读写的时候,如果开启了指针压缩,只需要覆盖指针的低32位就可以控制指针指向的地址。
参考
Chrome学习-V8和JavaScript内部机制介绍 https://x2nn.github.io/2026/03/18/Chrome学习-V8和JavaScript内部机制介绍/ ↩︎